
《Rethinking Reflection in Pre-Training》
摘要
语言模型反思其自身推理过程的能力,是其解决复杂问题的关键优势。尽管近期多数研究聚焦于此能力在强化学习阶段如何发展,但我们展示了它实际上在更早的时期——即模型的预训练期间——便已开始显现。为研究此现象,我们故意在思维链中引入错误,并测试模型是否仍能通过识别并纠正这些错误来得出正确答案。通过追踪模型在预训练不同阶段的表现,我们观察到这种自我纠正能力出现较早,并随时间推移而稳步提升。例如,一个基于 4 万亿 Token 预训练的 OLMo-2-7B 模型,在我们设计的六项自我反思任务中展现了自我纠正能力。
引言
反思增强了模型根据先前推理调整其响应的能力,从而提高了其输出的准确性。最近的研究报告称,“诸如反思之类的行为……是模型与强化学习环境互动的结果”。若要将能力的发展归因于此来验证这类主张,则必须在整个训练阶段进行全面的评估。在这项工作中,我们提出了一个详尽的框架来衡量反思,并且我们观察到这种现象在预训练期间持续存在。
使用现有的推理数据集对反思进行基准测试一直具有挑战性。在这类任务中,反思通常是稀疏的,并且每个模型都表现出独特的错误模式,从而产生独特的反思行为表现。我们通过区分情境反思 (situational-reflection) 和自我反思 (self-reflection) 来应对这一挑战。在情境设置中,模型检查由另一个来源(例如不同的前沿模型)创建的推理链。在自我反思中,模型则考虑其自身的推理过程。我们校准模型在被提供一些导致错误答案的干扰性推理时解决任务的能力,并以此在整个预训练过程中衡量反思能力。
\['gsd', 'avdropj'\]”。
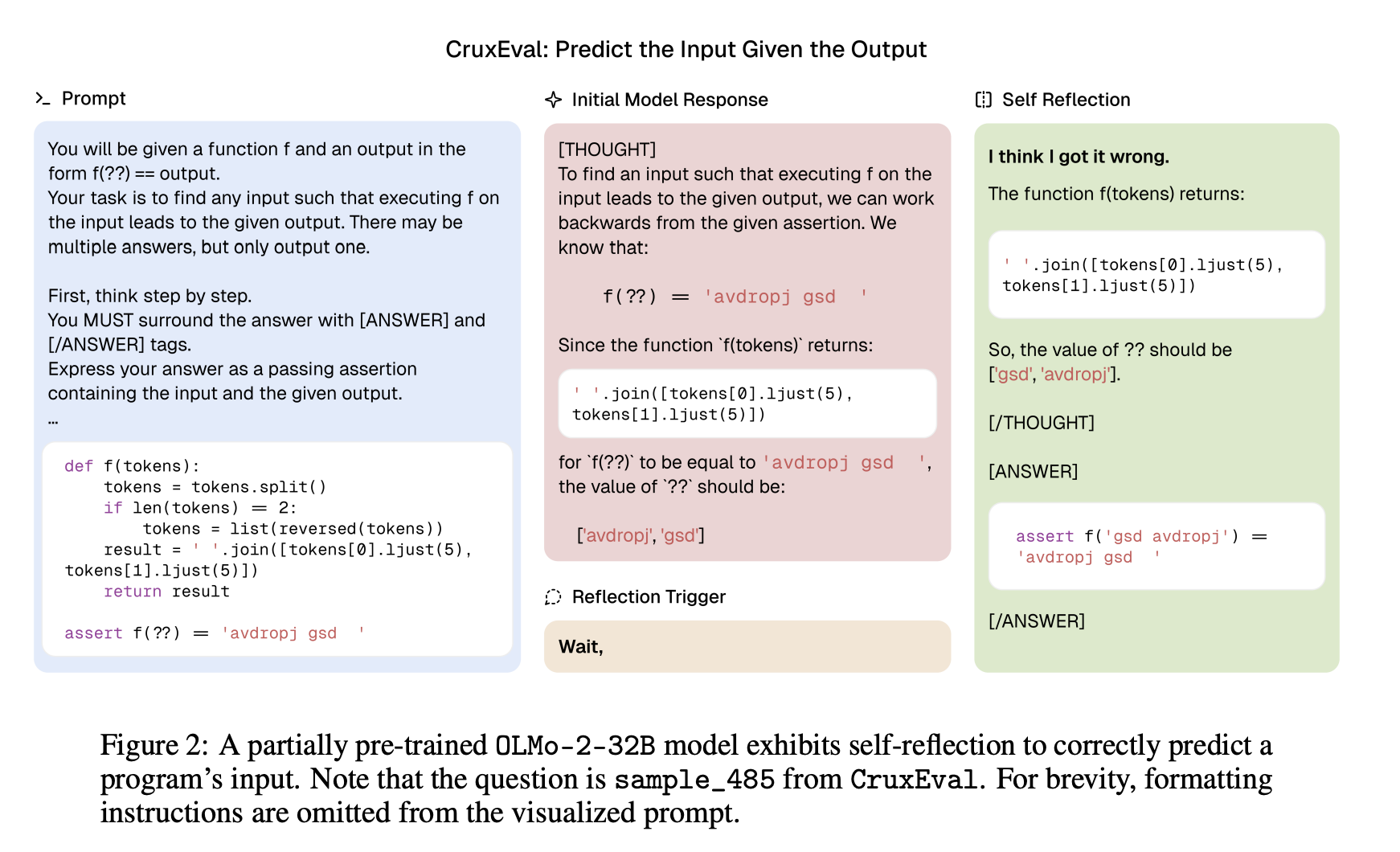
通过以编程方式引入错误的思维链 (Chains-of-Thought, CoTs),其特征包含算术扰动和逻辑不一致性等元素,我们可以控制和扩展正确完成这些任务所需的反思程度。这也保持了已建立的 CoT 格式 。此外,我们的算法方法允许通过调整已建立的推理基准,以相对快速和经济的方式创建这些数据集,这反过来又使得对模型在各种领域中的反思能力进行全面研究成为可能。我们的六个数据集,涵盖数学、编码、逻辑推理和知识获取领域,旨在评估情境反思和自我反思能力。
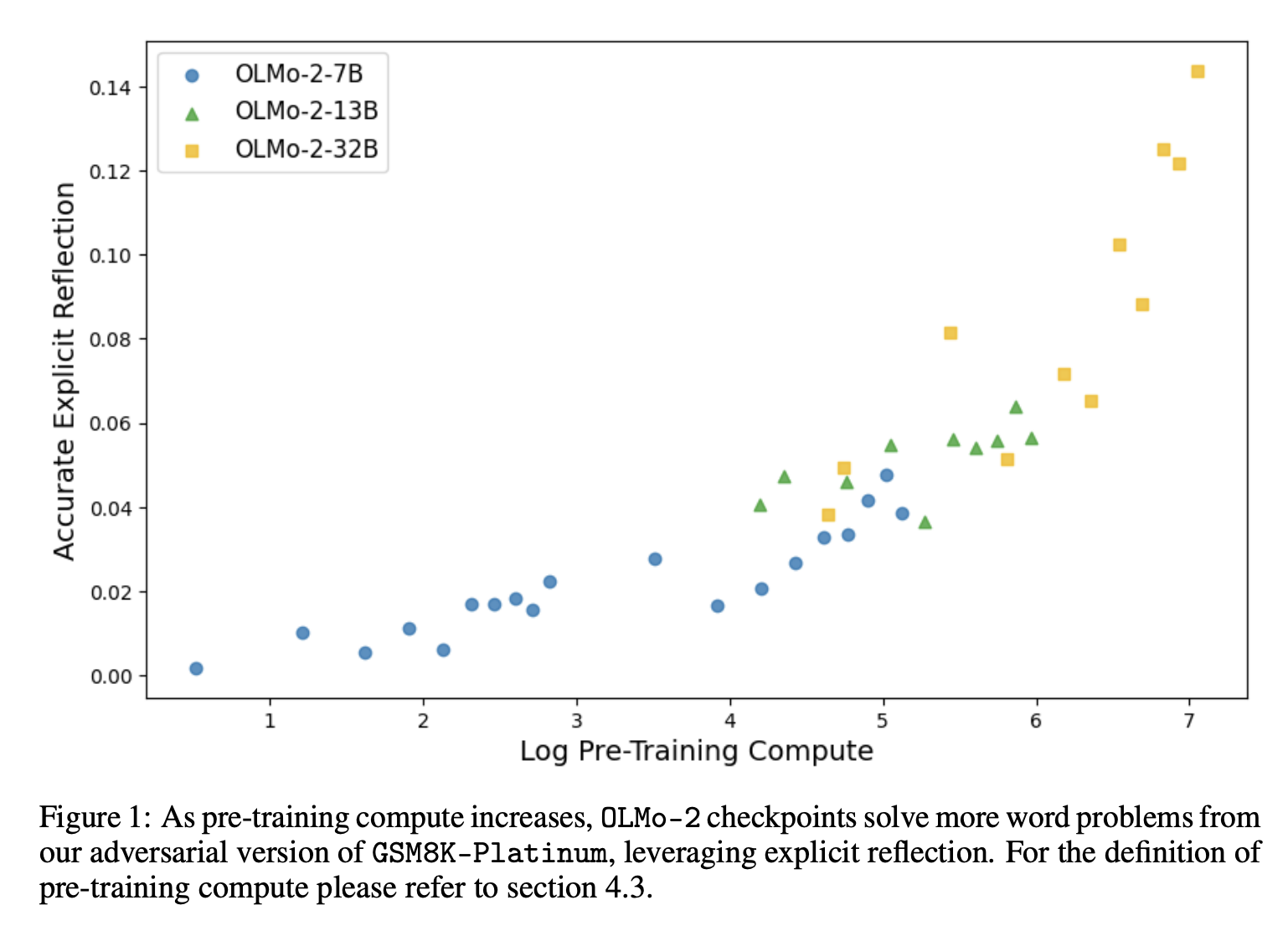
对来自 OLMo-2 模型家族、具有不同预训练计算量的检查点在我们这组六个不同数据集上进行评估的结果表明,反思在各个领域普遍存在。即使是一个简单的触发短语,如“Wait,”,也能使部分预训练的模型持续识别出引入的错误和它们自己产生的错误。具体来说,240 个数据集-检查点对中有 231 个展示了至少一个情境反思的实例,240 个对中有 154 个展示了至少一个自我反思的实例。随着预训练的增加,模型会纠正更多的对抗性示例,导致准确性与 $\log(\text{预训练计算量})$ 之间的平均皮尔逊相关系数在各项任务中达到 0.76。此外,随着预训练的进行,模型越来越多地从不正确的先前推理中恢复,模型生成中明确反思的比率增加,并且明确反思越来越多地有助于从干扰性 CoT 中恢复。
本文的贡献有三方面:
- 我们引入了一种系统化的方法,用于创建跨越代码、知识获取、逻辑推理和数学领域的六个数据集,以研究模型的反思能力。
- 我们证明了具有不同能力和训练计算量的预训练模型可以在广泛的领域中使用简单的插入语引发反思,以纠正不准确的先前推理。
- 我们观察到,持续改进的预训练可以带来更好的反思,从而能够用更少的测试时 Token 来解决相同数量的任务。
方法
定义反思
反思是一种元认知形式,涉及审视信息,评估其背后的推理过程,并基于该评估调整未来的行为。在大型语言模型的背景下,这个过程可以应用于从外部来源引入的信息或模型自身生成的信息。在这项工作中,我们创建了两种情境来引发和衡量反思:
情境反思是指模型反思由其他来源(例如不同的模型)创建的信息。
自我反思是指模型反思其自身生成的输出。
我们还通过两种形式来全面刻画反思:
显式反思 发生在模型生成的 Token 在其含义上识别并处理了对抗性情境中的错误时。显式反思可能出现在正确的模型输出中(换句话说,那些构成对我们对抗性任务的正确答案的输出),也可能出现在不正确的模型输出中。
隐式反思 发生在模型在对抗性情境中设法正确解决任务,但没有输出明确识别先前推理中错误的 Token 时。根据我们的定义,这意味着隐式反思不能导致对我们对抗性任务的错误回答。这使我们能够区分以下两种情况:其一,显式反思缺失但可以推断出发生了隐式反思;其二,根本没有发生任何反思。
使用对抗性反思数据集引发反思
我们提出了一种生成对抗性数据集的算法,该数据集能够引发语言模型的反思行为。该算法创建导致错误解的对抗性思维链 (CoT)。与自我反思(我们可以从模型自身的错误中汲取经验)不同,对于情境反思,我们必须设计人工的对抗性 CoT。从高层次来看,这些对抗性 CoT 是通过破坏正确的 CoT 来创建的,其方式模仿了人类的推理错误,例如逻辑失误和算术计算错误。在这两种情况下,当我们在上下文中提供 CoT 时,模型必须反思这些错误并修正它们,以得出正确的解。我们相信这些设置对于全面研究反思是必要的。
任务设计包括附加一个触发 Token,例如 "Wait,",以促进在整个任务解决过程中的持续推理。
该算法有两个变体。算法1和2分别创建情境反思和自我反思数据集。

测量反思
我们提出了一种自动化方法,使用对抗性数据集来测量模型的反思能力,该方法基于我们先前对反思的分类:
测量显式反思:为了识别显式反思的实例,我们开发了一个基于提示词的大语言模型(LLM)分类器。该分类器用于检测模型的输出是否明确承认并处理了所提供的对抗性上下文中的错误,无论模型最终是否得出了正确答案。
测量隐式反思:我们规定,在存在对抗性上下文的情况下,所有最终得出正确答案的模型生成过程均可归因于反思,即使其输出中并未包含与反思相关的 Token。我们认为,这与日常生活中描述人类元认知时对“反思”一词的理解是一致的。我们这种方法的一个推论是,根据其设计,那些生成了正确答案但未被显式分类器识别的实例,将被归类为隐式反思。
实验设置
为了全面研究反思,我们评估了跨越不同计算预算的部分预训练模型,这些模型在参数数量和训练 token 数量上都有所不同。
我们的研究包括两种类型的对抗性任务:(1)情境反思 (Situational-Reflection),其中对抗性思维链是使用前沿模型从现有数据集中系统地生成的;以及(2)自我反思 (Self-Reflection),其中对抗性思维链源自模型自身先前对原始任务实例的错误响应。
我们的评估还检查了模型输出是否展示了明确的反思性推理。
模型家族
OLMo-2
Qwen2.5
数据集
我们针对广泛的任务集对反思现象进行了评估,并基于 BIG-Bench Hard (BBH)、CruxEval、GSM8K、GSM8K-Platinum 和 TriviaQA 创建了六个对抗性数据集。
在我们的流程中,我们利用了 DeepSeek-V3(简称 DS-V3)、GPT-4o[^2] 和 SentenceTransformers 模型,并结合了多项自动化检查和人工核查,以确保我们数据集的质量和鲁棒性。
情境反思数据集:这些数据集的创建涉及一个多步骤流程:我们首先使用提示词引导一个大语言模型创建对抗性思维链(CoT)(另请参见算法1)。对于推理任务,原始任务可能将 CoT 作为数据集产物包含在内;若未包含,我们则使用如 GPT-4o 或 DS-V3 这样的前沿模型来生成 CoT。随后,利用正确的 CoT,通过引入会导致错误答案的故意错误,来构建对抗性 CoT。此外,流程最后还会进行检查,确保 CoT 不会暴露其误导意图。这些流程和提示词都经过精心设计以最大限度地减少错误,并且是针对特定数据集的,但其整体框架可以推广应用于任何领域和数据集。
自我反思数据集:这些数据集的创建方法是:在我们想要评估的基础任务上运行目标大语言模型,并收集模型未能正确解答的问题所对应的 CoT(另请参见算法2)。由于我们关注的是模型随着预训练进展其反思能力的变化,因此在自我反思数据集中,我们仅保留了那些在每个参数规模下、所有模型检查点均未能正确回答的问题,以确保在不同预训练检查点之间进行一致的比较。
评估

指标
如表3所示,对于情境反思和自我反思两种设置,Accuracy (准确率) 是模型正确解决的任务实例所占的比例。独立于 Accuracy,我们利用 Explicit Reflection Classifier (显式反思分类器) 来衡量 Explicit Reflection Rate (显式反思率),这是模型输出表现出显式反思的任务实例所占的比例,无论其是否正确。我们还报告了 Explicit Reflection Accuracy (显式反思准确率),即模型既正确解决任务又表现出显式反思的任务实例所占的比例。最后,Implicit Reflection Accuracy (隐式反思准确率) 是模型输出正确且未表现出显式反思的任务实例所占的比例。
此外,对于每个数据点,我们将 pre-training compute (预训练计算量) 报告为 $6nt$,其中 $n$ 和 $t$ 分别是参数数量和训练 Token 数量。
显式反思分类器
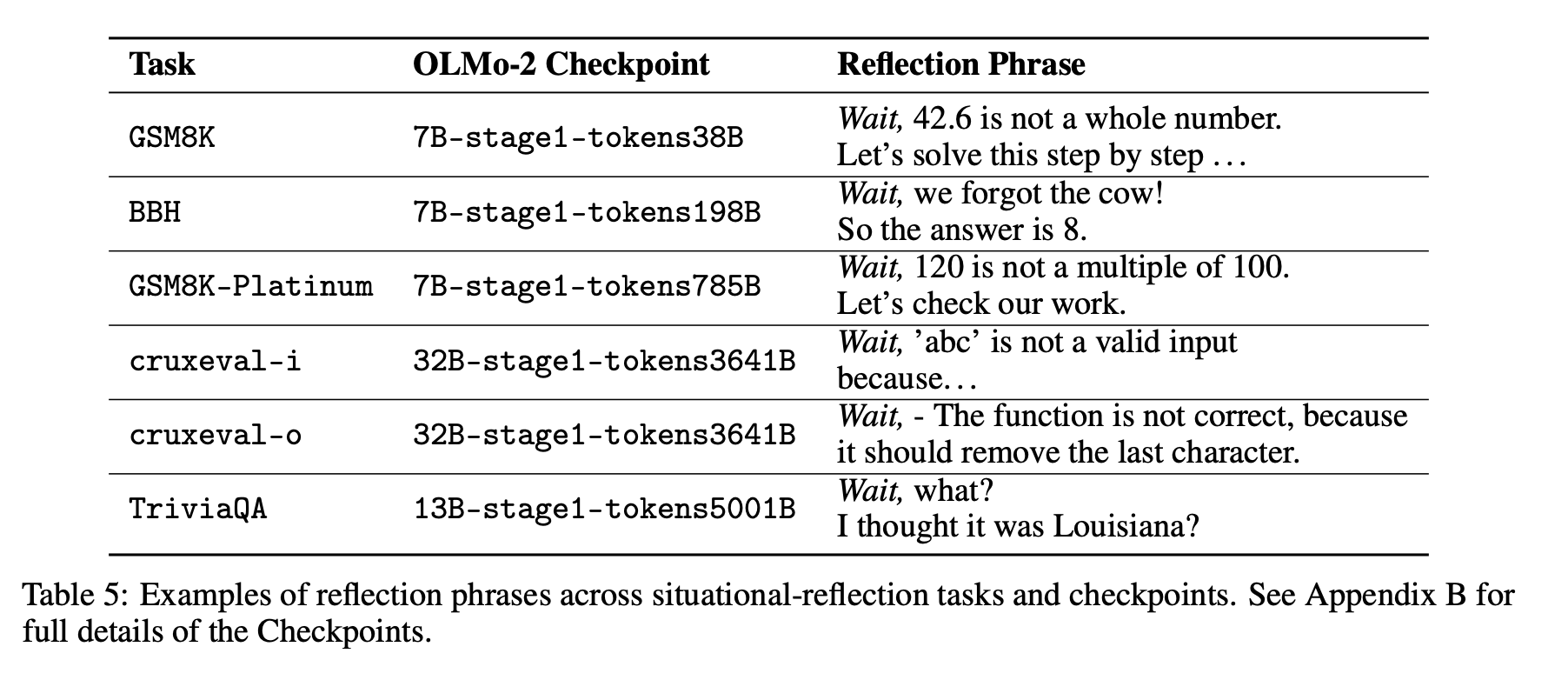
我们开发了一个基于提示词的分类器,用于判断模型输出是否展现出显式反思。我们向 DeepSeek-V3 提供了关于“反思”含义的描述以及两到四个显式反思的示例作为提示词。该分类器旨在检测的一些显式反思短语示例,展示于表5。
基础设施
我们的实验设置使用了 vLLM 推理框架来托管 OLMo-2 和 Qwen 模型。我们使用 SGLang 托管 DeepSeek-V3。我们使用一个 AMD MI300x 加速器集群和 Kubernetes 来向其中调度作业。
结果
为了全面地衡量跨领域的反思性推理能力,我们的分类器在 BBH、cruxeval-i、cruxeval-o、GSM8K、GSM8K-Platinum 和 TriviaQA 数据集上,针对情境反思 和自我反思 的设置,区分了显式反思和隐式反思。令我们惊讶的是,我们发现了强烈的反思现象,这种现象随着训练计算资源的增加而增强。此外,随着预训练的进行,模型从干扰因素中恢复的能力逐渐增强,显式反思的比例有所增加,并且显式反思对于从干扰因素中恢复的贡献也越来越大(示例参见表 5)。这些结果突显了预训练在培养模型反思能力方面所扮演的角色。
显式情境反思在所有模型中均表现突出

在表6中,一个令人鼓舞的发现是,除了cruxeval-i任务之外,对于所有其他任务,每一个OLMo-2预训练检查点都显示出能从情境混淆因素中恢复的迹象,无论是通过隐式还是显式的方式[^3]。这使得在240个数据集-检查点对中,有231个至少展示了一次情境反思的实例。然而,为了证实我们的假设——即模型会逐渐发展并运用显式反思——大多数恢复行为应归因于显式情境反思。本质上,我们期望观察到的是,随着预训练计算量的增加,以下情况的频率也随之增加:(a) 从情境混淆因素中成功恢复,(b) 对情境混淆因素进行显式反思,以及 (c) 通过显式反思从情境混淆因素中恢复。
各项指标与$\log(\text{预训练计算量})$之间的高度正相关皮尔逊相关性印证了(a)、(b)和(c)点。同时,我们也观察到隐式反思准确率与$\log(\text{预训练计算量})$之间的相关性普遍较低。综合来看,这些结果强调了随着预训练的深入,模型倾向于更成功地解决对抗性实例,并且在此过程中越来越倾向于使用显式反思。例如,GSM8K-Platinum任务的结果(如图3所示)表明,随着预训练量的增加,不同参数规模的模型都通过对错误进行显式反思来解决任务中的大部分实例。TriviaQA是一个例外情况,其性能的显著提升主要归因于隐式反思,这是因为该任务主要衡量知识获取能力,其中若干实例无需显式推理即可解决。
模型即使没有触发语也能反思;‘等等,’ 增强了显式性和准确性
为了理解 ‘等等,’-触发语的因果作用,我们研究了模型在 GSM8K-Platinum 数据集上使用处于两个极端情况的触发语时的表现。具体来说,我们研究了模型在没有触发语 ($A$) 和带有明确承认 ‘等等,我犯了个错误’ 的触发语 ($B$) 情况下的表现。我们选择 A 模式,目的是尽量减少对对抗性思维链 (CoT) 中错误的关注。相对地,我们选择 B 模式来强调思维链 (CoT) 中存在错误。图 4展示了这些结果。
结果首先证实了这样一个假设:即使没有触发语,随着预训练的进行,模型也能越来越成功地处理情境混淆因素。上文结果中 ‘等等,’ 的作用在这里得到了进一步阐明。我们看到,模型在此任务上的表现受限于 $A$ 和 $B$ 这两个极端情况。在场景 $A$ 中,模型通过隐式反思提高准确率;在场景 $B$ 中,模型依据设定进行显式反思,从而显著提高性能。‘等等,’-设置在隐式反思时表现得像 $A$,在显式反思时表现得像 $B$。有趣的是,如图 4所示,其性能可以分解为 $acc_{Wait} = e_{Wait} * acc_{B} + (1-e_{Wait}) * i\_acc_{A}$,其中 $e_{Wait}$ 是显式反思率,$i\_acc$ 是隐式反思准确率。
此外,我们看到性能的显著提升归因于 ‘等等,’-触发语。这是因为该触发语引发了显式反思,其比率随着预训练的增加而增加,并且它也达到了相应的 $B$-触发语模型所实现的性能——正如上面指出的,我们选择 $B$ 作为一种强调思维链 (CoT) 中存在错误的模式。换句话说,当模型在带有 ‘等等,’ 的对抗性思维链 (CoT) 条件下表现出显式反思时,其性能与明确告知模型思维链 (CoT) 包含错误时的性能相当。相反,当模型在带有 ‘等等,’ 的对抗性思维链 (CoT) 条件下但未表现出显式反思时,其性能则与仅在对抗性思维链 (CoT) 条件下的模式一致。这确立了通过 ‘等等,’ 进行显式反思以提高准确率的因果联系。
显式自我反思更难,但随着更多计算资源投入而进步
乍一看,表7中自我反思现象较为罕见,这可能被视为一个负面结果。然而,这可以通过以下事实来解释:在这种评估设置下,模型是在它们回答错误的任务实例上进行评估的——因此,根据设计,这些任务本身就特别困难。尽管如此,在大约64.2%的任务尝试中,模型确实展现出至少一定的自我纠正能力。
为了区分自我反思和自我纠正,我们在图5中绘制了模型生成的反思率,该比率独立于任务是否被解决。这些结果揭示了一个强烈的趋势:随着预训练的深入,模型在显式指出自身错误方面表现得更好。对于cruxeval-i任务,我们注意到随着预训练的增加,模型倾向于学习自我纠正。然而,它们能够进行自我反思的时间点要早得多。这表明自我反思能力的发展自然地先于自我纠正能力。
这些自我反思的萌芽如何在后训练阶段演变成复杂的自主推理能力,这是一个悬而未决的问题,我们留待未来的工作去探索。我们假设,必须存在一个预训练自我反思能力的关键阈值,一旦超过这个阈值,模型便极有可能发展成为具备测试时推理能力的系统。令我们惊讶的是,在从原始网络数据集中学习时,我们观察到了如此程度的显式自我反思。找出在预训练期间能够促进显式自我反思的数据分布,是我们工作的下一个自然的步骤。
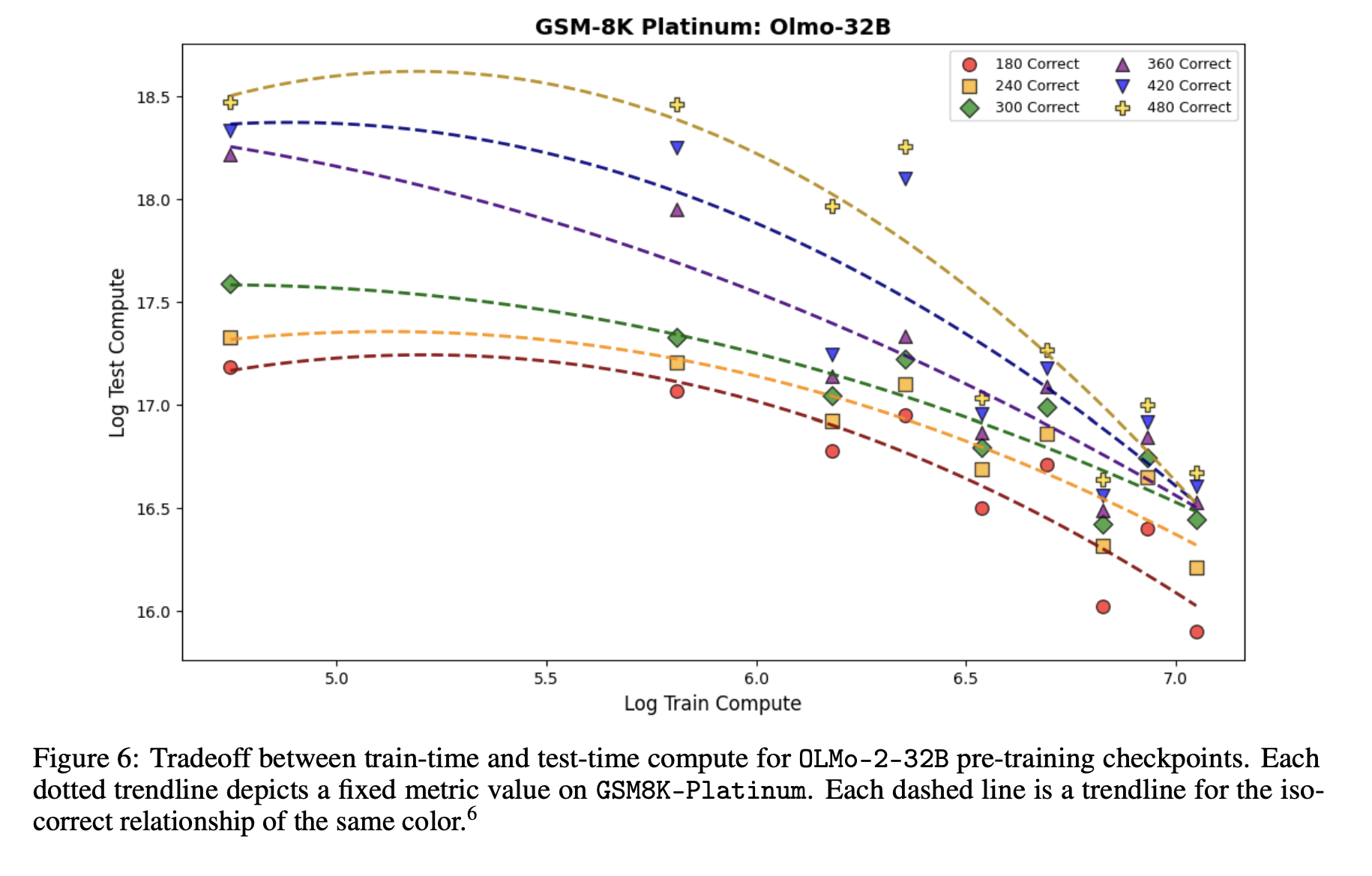
可以用训练时的计算量换取测试时的计算量
我们研究了增加训练时计算量投入与在下游任务上达到可比准确性所需的相应测试时计算量支出之间的权衡关系。我们通过将训练时计算量估计为 $6nt$ 来处理这个问题,其中 $n$ 和 $t$ 分别是参数数量和训练 Token 数量;并将测试时计算量估计为 $2nw$,其中 $w$ 代表为解决一定数量的对抗性问题而生成的词语数量。[^4]
我们首先指定一组要正确回答的目标对抗性问题数量。然后,我们为每个目标绘制一条曲线。我们针对前面介绍的 GSM8K-Platinum 对抗性数据集研究了这一点。我们通过在模型生成内容后附加触发词“Wait,”来遵循顺序测试时计算量扩展方法。实际上,我们引入了两个“Wait,”触发词,以使较弱的模型能够达到与较强模型相同的指标水平。这模仿了[某项研究/方法]中扩展测试时计算量的顺序方法。
正如我们在图6中看到的,随着训练时计算量的增加,OLMo-2-32B 检查点所需的测试时计算量会减少。这一结果进一步支持了我们的假设,即随着预训练的进行,模型的反思能力会变得更好,这意味着在给定准确性水平下需要更少的测试时计算量。
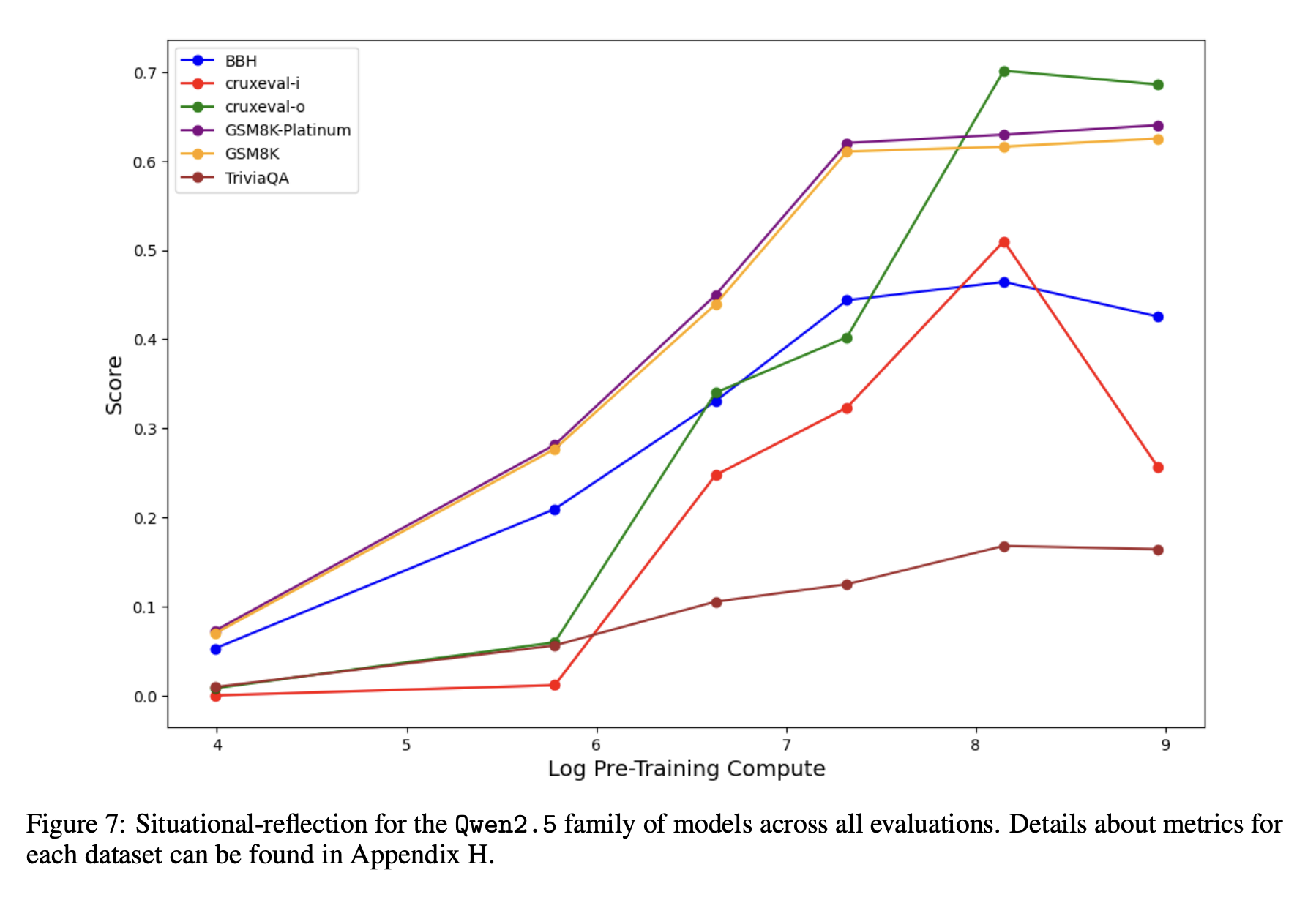
我们在更强的模型家族中是否观察到类似结果?
为了研究这些现象在不同模型家族中的表现,我们在图7中报告了 Qwen2.5 在我们的对抗性任务上的结果。与我们在 OLMo-2 上的结果一致,我们发现随着预训练计算量的增加——在此案例中,体现为参数数量的增加——模型在对抗性任务上的性能持续提高。这再次证明,仅凭预训练计算量的增加,模型就能越来越好地解决任务,即使在先前的推理中存在错误。
结论
本工作的目标是解决这个问题:“反思性推理在预训练期间是如何发展的?”,这与普遍认为反思能力是在训练后阶段通过强化学习出现的观点相反。我们提出并实现了一个全面的框架,用于在整个预训练阶段衡量反思能力。通过我们的对抗性数据集,针对情境反思和自我反思这两种设置,我们能够广泛地校准这些能力。我们确定,即使是用很少的训练浮点运算量训练的模型,例如使用 1980 亿个 token 训练的 OLMo-2-7B,也在数学、代码、语言和逻辑推理方面表现出反思能力。此外,随着在预训练上投入更多的计算资源,这些能力会进一步增强。