


摘要
强化学习(RL)已被广泛应用于大规模大语言模型(LLMs)的后训练阶段。最近,通过强化学习激励大语言模型推理能力的实践表明,适当的学习方法可以实现有效的推理时可扩展性。强化学习的一个关键挑战是在可验证问题或人为规则之外的各种领域中为大语言模型获取准确的奖励信号。在这项工作中,我们研究了如何通过增加推理计算来改进通用查询的奖励建模(RM),即**,并进一步研究如何通过适当的学习方法提高性能-计算扩展的有效性。
对于奖励建模方法,我们采用pointwise generative reward modeling(GRM),以便为不同输入类型提供灵活性,并具备推理时扩展的潜力。对于学习方法,我们提出了Self-Principled Critique Tuning(SPCT),通过在线强化学习在 GRM 中培养可扩展的奖励生成行为,以自适应地生成原则并准确地进行批判,从而产生了DeepSeek-GRM模型。此外,为了实现有效的推理时扩展,我们使用并行采样来扩展计算使用量,并引入了一个元奖励模型来指导投票过程以获得更好的扩展性能。实验表明,SPCT 显著提高了 GRM 的质量和可扩展性,在各种奖励建模基准测试中优于现有方法和模型,且没有严重的偏见,并且与训练时扩展相比可以实现更好的性能。DeepSeek-GRM 在某些任务中仍然面临挑战,我们相信这可以通过未来在通用奖励系统方面的努力来解决。这些模型将被发布并开源。

引言
我们能否设计一种旨在为通用奖励模型实现有效推理时间扩展的学习方法?
在这项工作中,我们研究了不同的[奖励模型方法],发现逐点生成式奖励建模(GRM)可以在纯语言表示内统一对单个、成对和多个响应的评分,从而克服了挑战(1)。我们探索发现,某些原则可以在适当的标准内指导生成式奖励模型的奖励生成过程,进而提高奖励质量,这启发了我们:奖励模型的推理时间可扩展性或许可以通过扩展高质量原则和准确批判的生成来实现。
基于这一初步认识,我们提出了一种新颖的[学习方法],自我原则化批判调优(SPCT),旨在培养生成式奖励模型中有效的推理时间可扩展行为。通过利用基于规则的在线强化学习,SPCT使生成式奖励模型能够学习根据输入查询和响应自适应地设定原则和批判,从而在通用领域产生更好的结果奖励(挑战(2))。随后,我们开发了DeepSeek-GRM-27B,该模型基于Gemma-2-27B,并使用SPCT进行了后训练。对于[推理时间扩展],我们通过多次采样来扩展计算资源的使用。通过并行采样,DeepSeek-GRM可以生成不同的原则集合以及相应的批判,然后通过投票决定最终奖励。通过更大规模的采样,DeepSeek-GRM能够基于多样性更高的原则进行更准确的判断,并输出粒度更精细的奖励,这解决了挑战(3)&(4)。此外,除了通过投票方式,我们还训练了一个元奖励模型以获得更好的扩展性能。实验证明,SPCT显著提高了生成式奖励模型的质量和可扩展性,在多个综合性奖励模型基准测试中表现优于现有方法和模型,且没有表现出严重的领域偏差。我们还将DeepSeek-GRM-27B的推理时间扩展性能与参数量高达671B的更大模型进行了比较,发现相较于通过增大模型规模进行训练时间扩展,我们的方法能实现更优的性能。尽管当前方法在效率和特定任务方面仍面临挑战,但我们相信,通过SPCT及后续的努力,具有增强可扩展性和效率的生成式奖励模型可以作为通用奖励系统的多功能接口,推动大语言模型后训练和推理领域的前沿发展。
总的来说,我们的主要贡献如下:
- 我们提出了一种名为 自洽原则批判调整(SPCT) 的新颖方法,旨在提升通用奖励模型有效的推理时可扩展性,并由此产生了 DeepSeek-GRM 模型。此外,我们还引入了一个元奖励模型(meta RM),以在投票机制之外有效提升 DeepSeek-GRM 的推理时扩展性能。
- 我们通过实验证明,相较于现有方法及若干强大的公开模型,SPCT 显著提升了通用奖励模型(GRM)的质量和推理时可扩展性。
- 我们亦将 SPCT 训练方案应用于更大规模的大语言模型(LLM),并发现就训练时间而言,推理时扩展的表现可能优于模型规模扩展。
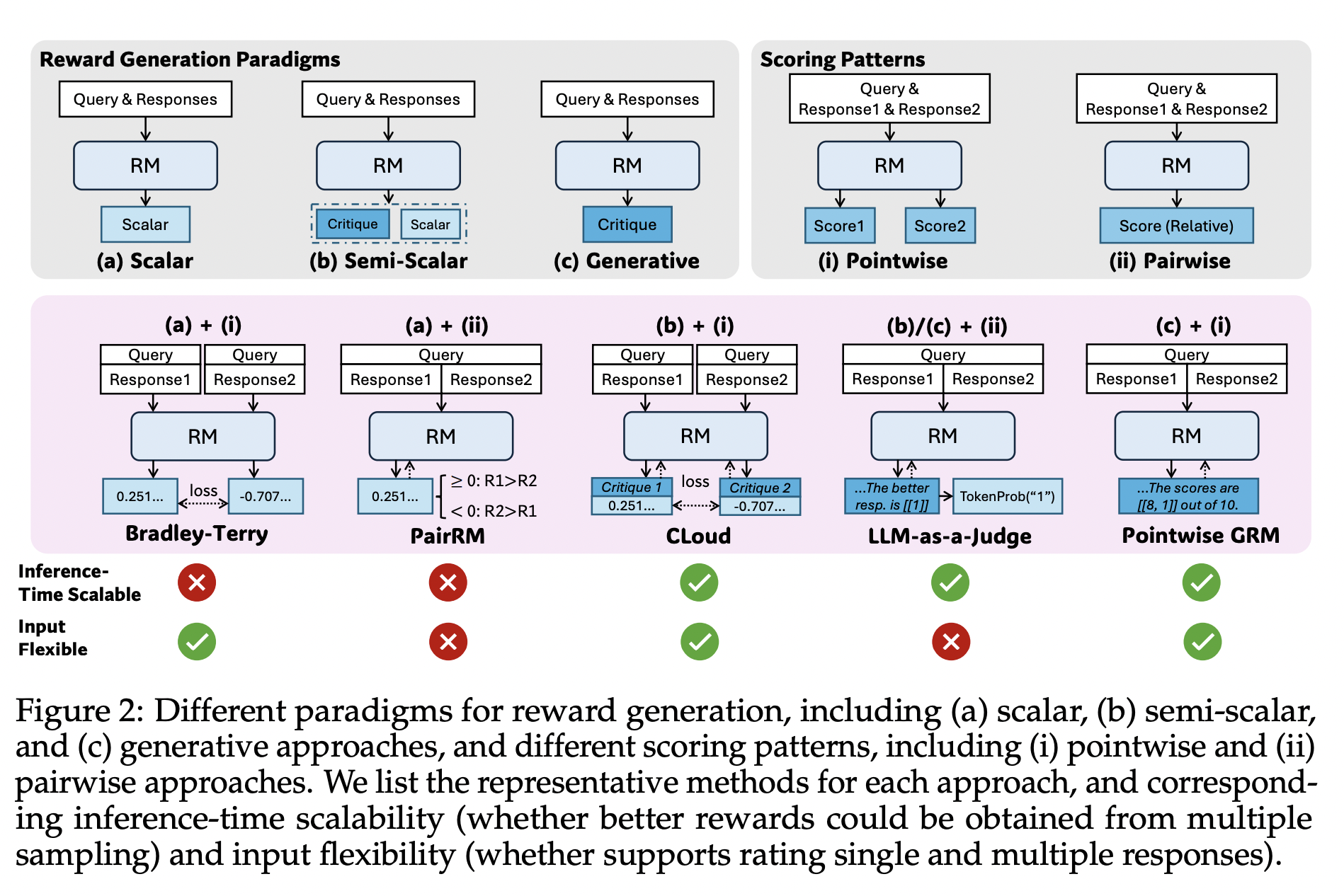
不同奖励模型(RM)方法的比较
如图2所示,奖励模型(RM)方法主要由奖励生成范式和评分模式决定,这从本质上影响了 RM 的推理时可扩展性和输入灵活性。对于奖励生成范式,我们区分三种主要方法:标量、半标量和生成式。标量方法为给定的查询和响应分配标量值,而半标量方法既生成文本判断(称为“评语”),也生成标量奖励值。生成式方法仅生成作为文本奖励的评语,奖励值可从中提取。对于评分模式,我们区分两种主要方法:逐点式和配对式。逐点式方法为每个响应分配一个独立的分数,而配对式方法则从所有候选响应中选择单个最佳响应。为了扩展推理时的计算使用,我们关注基于采样的方法,这些方法为相同的查询和响应生成多组奖励,然后聚合得到最终奖励。因此,RM 的推理时可扩展性取决于是否能通过多次采样获得不同的奖励,而标量 RM 在大多数情况下会因此失效,因为其奖励生成是不变的;输入灵活性则定义为 RM 是否支持对单个、成对以及多个响应进行评分,其中配对式 RM 几乎无法对单个响应评分,并且通常需要额外技术来处理多个响应。逐点式生成式奖励模型(GRM)的公式为:
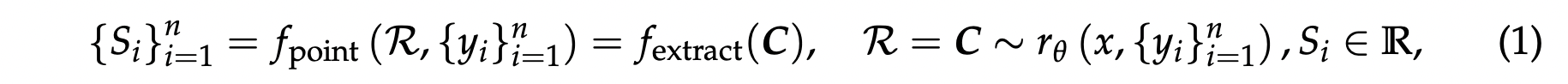
其中 $x$ 是查询,$y_i$ 是第 $i$ 个响应,$r_{\theta}$ 是由 $\theta$ 参数化的奖励函数,$\mathcal{R}$ 是奖励,$\boldsymbol{C}$ 是评价,$S_i$ 是 $y_i$ 的个体分数,而 $f_{\mathrm{extract}}(\cdot)$ 从生成结果中提取奖励。通常,奖励是离散的,并且在这项工作中,我们默认分配 $S_i \in \mathbb{N}, 1 \leq S_i \leq 10$。
Boosting Reward Quality with Principles
$$ \label{eq:principle-understand} \mathcal{R} = \boldsymbol{C} \sim r_{\theta}\left(x, \{y_i\}_{i=1}^n, \{p_i\}_{i=1}^m\right), $$其中 $\{p_i\}_{i=1}^m$ 代表所使用的原则。我们进行了一项初步实验,旨在检验恰当的原则对奖励质量的影响,实验采用了 Reward Bench 基准中的 Chat Hard 子集以及 PPE 基准中的 IFEval 子集。
我们使用 GPT-4o-2024-08-06 来生成原则,然后对每个样本进行四次逐点奖励。并且我们筛选了那些其相应奖励与真实值一致的原则。我们测试了不同的大语言模型,使用了它们自己生成的原则和经过筛选的原则,并将它们与没有原则指导的默认设置进行了比较。结果显示在表1中。我们发现,自生成的原则几乎不提高性能,但经过筛选的原则可以显著提升奖励质量。这表明,在正确调用的标准下,恰当的原则能更好地指导奖励生成。

自生成原则批判调优 (SPCT)
受初步结果的启发,我们为逐点 GRM 开发了一种新颖的方法,旨在学习生成能够有效指导批判生成的自适应、高质量原则,该方法被称为自生成原则批判调优 (SPCT)。如图3所示,SPCT 包含两个阶段:作为冷启动的[拒绝式微调],以及通过改进所生成的原则和批判来强化通用奖励生成的[基于规则的在线强化学习]。SPCT 同样能在推理时扩展阶段促进 GRM 展现这些行为。
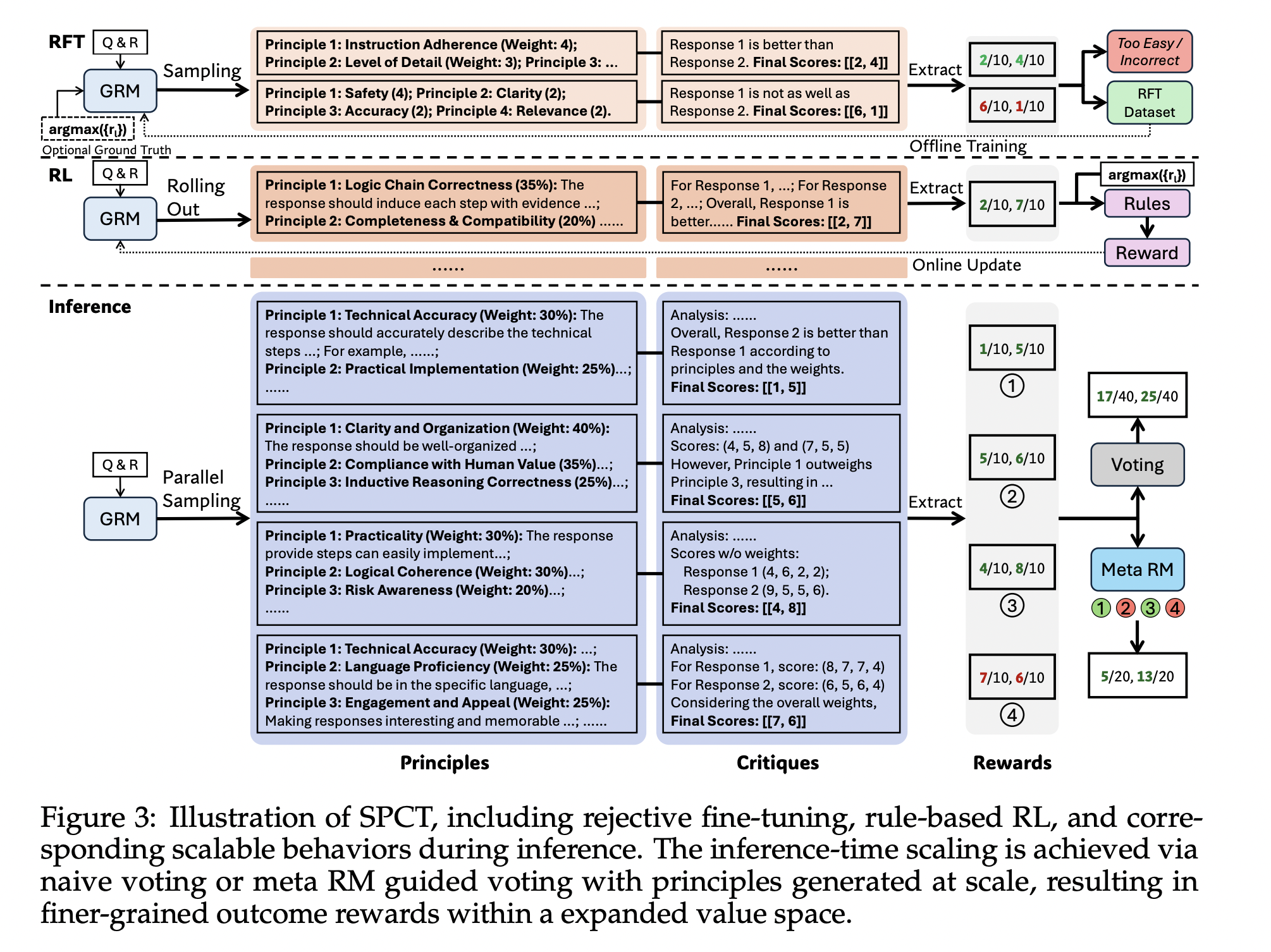
将原则从理解解耦至生成
根据初步实验,我们发现适当的原则可以在特定标准内指导奖励生成,这对于高质量的奖励至关重要。然而,为通用奖励模型(generalist RM)大规模地生成有效原则仍然具有挑战性。为应对此挑战,我们提议将原则从理解解耦至生成,即将原则视为奖励生成的一部分,而非一个预处理步骤。形式上,当原则被预先定义时,原则遵循方程式2来指导奖励的生成。生成式奖励模型(GRM)可以自行生成原则,然后基于这些原则生成评价,其形式化表示为
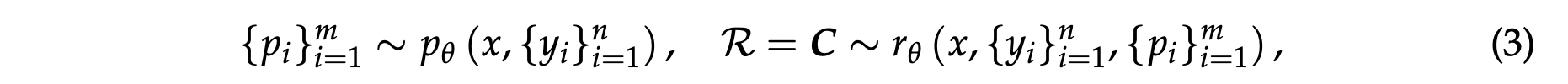
其中 $p_{\theta}$ 是由 $\theta$ 参数化的原则生成函数,它与奖励生成 $r_{\theta}$ 共享同一个模型。这种转变使得原则能够基于输入查询和响应生成,自适应地对齐奖励生成过程,并且原则和相应评论(critiques)的质量和粒度可以通过在 GRM 上进行后训练得到进一步提高。随着原则的大规模生成,GRM 可能在更合理的标准内以更细的粒度输出奖励,这对于推理时扩展(inference-time scaling)也至关重要。
基于规则的强化学习
为了同时优化 GRM 中的原则和批判生成,我们提出了 SPCT,该方法整合了[拒绝式微调]和[基于规则的强化学习]。前者用作冷启动。拒绝式微调(冷启动) 拒绝式微调阶段的核心思想是使 GRM 能够适应生成具有正确格式且适用于各种输入类型的原则和批判。与先前那些混合了用于单一、配对及多个响应的不同格式的奖励模型(Reward Model, RM)数据的工作不同,我们采用了逐点 GRM,以便用相同的格式为任意数量的响应灵活地生成奖励。在数据构建方面,除了通用的指令数据外,我们还利用预训练的 GRM,针对来自具有不同响应数量的 RM 数据中的查询及其响应,进行轨迹采样。对于每一个查询及其对应的响应,采样过程会执行 $N_{\mathrm{RFT}}$ 次。拒绝策略也是统一的:拒绝那些预测奖励与真实奖励(ground truth)不一致(即不正确)的轨迹,以及那些所有 $N_{\mathrm{RFT}}$ 次采样轨迹均预测正确(表明过于简单)的查询和响应组合。形式上,令 $r_i$ 表示对查询 $x$ 的第 $i$ 个响应 $y_i$ 的真实奖励,若预测的逐点奖励 $\{S_i\}_{i=1}^n$ 满足以下条件,则视为正确:
我们保证真实奖励 (ground truth rewards) 中只包含一个最大值,其条件如下:
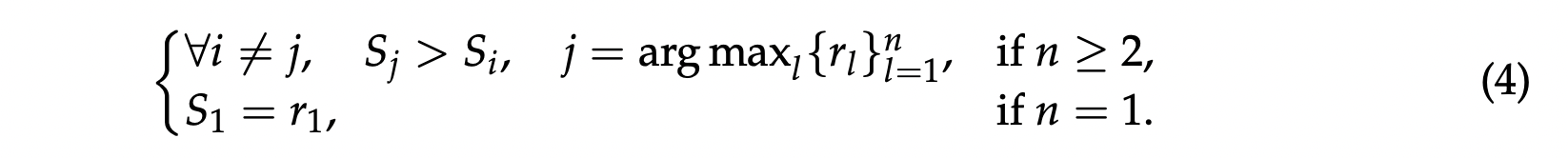
然而,与先前的工作类似,我们发现预训练的 GRM(生成式奖励模型)在有限的采样配额内,很难为一部分查询及其对应的响应生成正确的奖励。因此,除了非提示采样 (non-hinted sampling) 外,我们选择性地将 $\mathop{\mathrm{arg\,max}}_{l} \{r_l\}_{l=1}^n$ 附加到 GRM 的提示词 (prompt) 中,这种方法称为提示采样 (hinted sampling),期望预测的奖励能与真实奖励对齐。对于提示采样,每个查询和相应的响应仅被采样一次,并且只有在轨迹不正确时才会被拒绝。与以往研究不同的是,我们观察到提示采样的轨迹有时会“抄近路”跳过生成的评价 (critique),尤其是在推理任务中,这表明在线强化学习 (online RL) 对于 GRM 的必要性及其潜在益处。
基于规则的强化学习
GRM 通过基于规则的在线强化学习(RL)进行进一步微调。具体而言,我们使用 GRPO 的原始设置,并采用基于规则的结果奖励。在推演过程中,GRM 根据输入的查询和响应生成原则和评价,然后提取预测的奖励,并使用准确性规则与真实值进行比较。与 @deepseekai2025deepseekr1incentivizingreasoningcapability 不同,我们未使用格式奖励。而是应用了更大的 KL 惩罚系数,以确保格式并避免严重偏差。形式上,对于给定的查询 $x$ 和响应 $\{y_i\}_{i=1}^n$,第 $i$ 个输出 $o_i$ 的奖励 $r_i$ 定义如下:
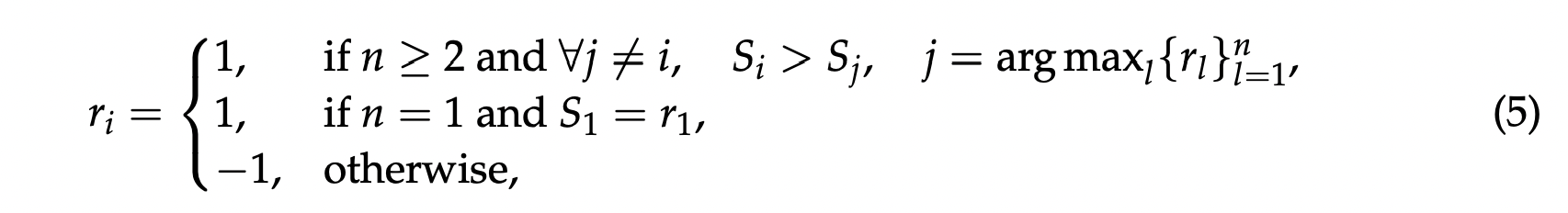
其中,逐点奖励 $\{S_i\}_{i=1}^n$ 是从 $o_i$ 中提取的。该奖励函数鼓励 GRM 利用在线优化的原则和评价来区分最佳响应,这有利于实现有效的推理时扩展。 奖励信号可以从任何偏好数据集和已标注的大语言模型响应中无缝地获取。
使用 SPCT 进行推理时扩展
为了利用更多的推理计算来进一步提升 DeepSeek-GRM 在通用奖励生成方面的性能,我们探索了基于采样的方法来实现有效的推理时可扩展性。
使用生成的奖励进行投票
逐点 GRM 的投票过程定义为对奖励求和:
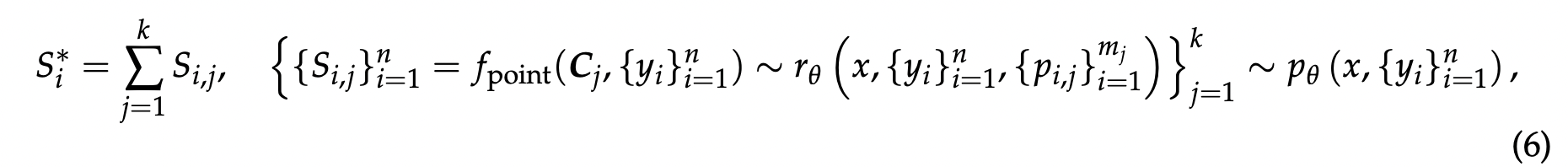
其中 $S_i^*$ 是第 $i$ 个响应的最终奖励($i=1,...,n$)。由于 $S_{i,j}$ 通常设置在一个小的离散范围内,例如 $\{1,...,10\}$,投票过程实际上将奖励空间扩大了 $k$ 倍,并使 GRM 能够生成大量原则,这有利于最终奖励的质量和粒度。一个直观的解释是,如果每个原则都可以被视为判断视角的代理,那么更多的原则可能更准确地反映真实分布,从而带来扩展效果。值得注意的是,为了避免位置偏差和保证多样性,响应在采样前会被打乱。
元奖励模型引导投票
DeepSeek-GRM 的投票过程需要多次采样,并且由于随机性或模型限制,一些生成的原则和评论可能存在偏见或质量低下。因此,我们训练了一个元奖励模型(meta RM)来指导投票过程。该元奖励模型是一个逐点标量奖励模型,训练用于识别 DeepSeek-GRM 生成的原则和评论的正确性,使用二元交叉熵损失,其中标签根据 Equation 4确定。数据集包含来自 RFT 阶段非提示采样的轨迹,以及从待引导的 DeepSeek-GRM 采样的轨迹,旨在既能提供足够的正负奖励,又能如 @chow2025inferenceaware 所建议的那样,减轻训练策略和推理策略之间的差距。引导投票很简单:元奖励模型为 $k$ 个采样奖励输出元奖励,最终结果由具有前 $k_{\mathrm{meta}} \leq k$ 个元奖励的奖励投票决定,从而过滤掉低质量样本。
实验设置
基准和评估指标 我们在不同领域的各种 RM 基准上评估不同方法的性能:*Reward Bench*、*PPE*、*RMB*、*ReaLMistake*。我们对每个基准使用标准的评估指标:在 Reward Bench、PPE 和 RMB 中,评估从一组响应中挑选最佳响应的准确率;对于 ReaLMistake,评估 ROC-AUC。为了处理多个响应的预测奖励出现并列得分的情况,我们打乱响应的顺序,并通过 $\mathop{\mathrm{arg\,max}}_{i} S_i$ 来确定最佳响应,其中 $S_i$ 是打乱顺序后第 $i$ 个响应的预测奖励。
方法实现 对于基线方法,我们基于 Gemma-2-27B 重新实现了 *LLM-as-a-Judge*、*DeepSeek-BTRM-27B*、*CLoud-Gemma-2-27B* 和 *DeepSeek-PairRM-27B*,并使用了与 DeepSeek-GRM 兼容的所有训练数据和设置。对于我们的方法,我们基于 Gemma-2-27B 实现了 *DeepSeek-GRM-27B-RFT*,并在不同规模的大语言模型上实现了 *DeepSeek-GRM*,包括 DeepSeek-V2-Lite (16B MoE)、Gemma-2-27B、DeepSeek-V2.5 (236B MoE) 和 DeepSeek-V3 (671B MoE)。元 RM (meta RM) 在 Gemma-2-27B 上进行训练。默认结果使用贪婪解码 (greedy decoding) 报告,推理时缩放 (inference-time scaling) 使用 $\mathrm{temperature}=0.5$。
结果与分析
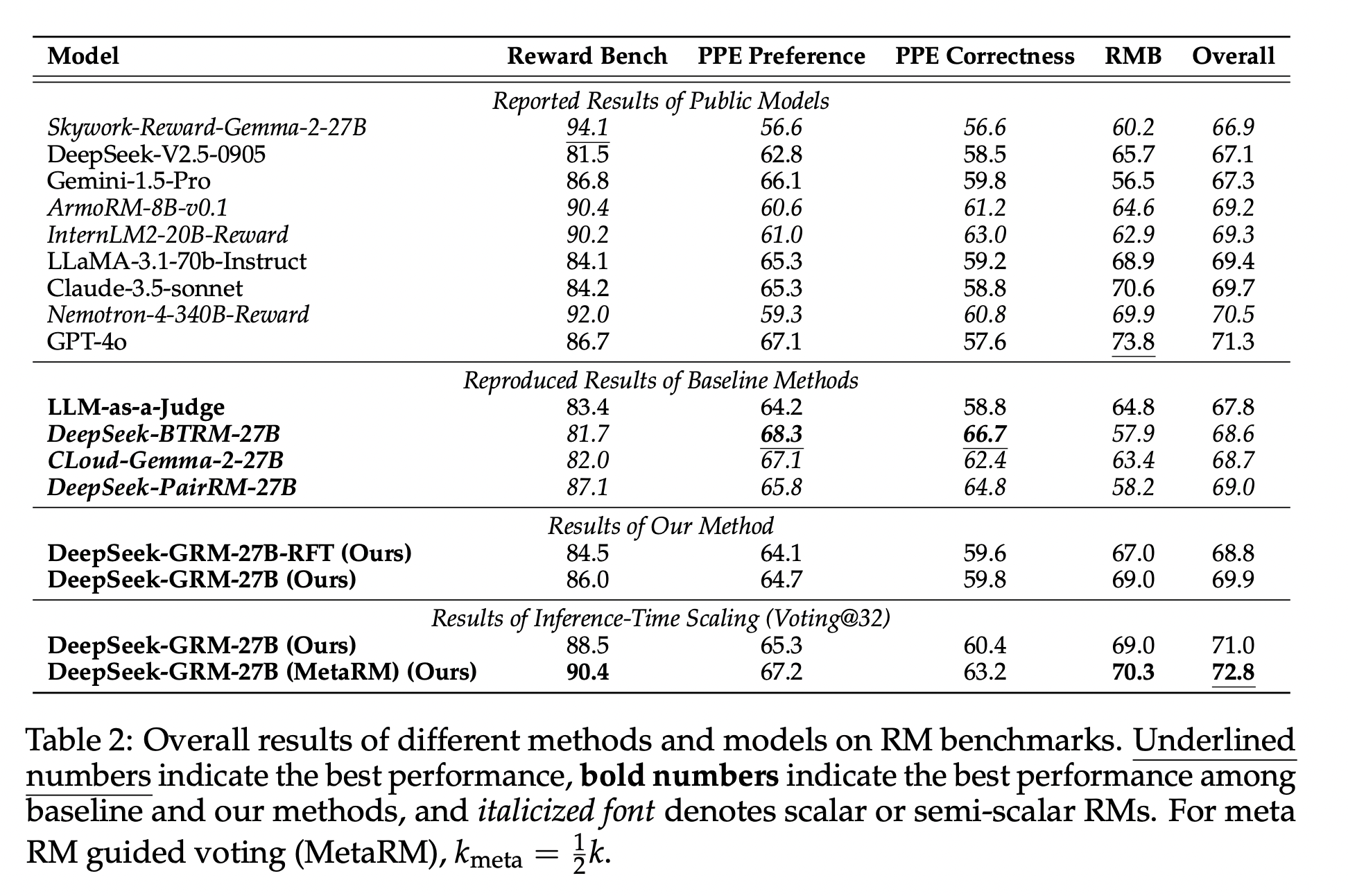
在 RM 基准测试上的性能 不同方法和模型在奖励模型(RM)基准测试上的总体结果如表2所示。我们将 DeepSeek-GRM-27B 的性能与已报告的公开模型结果以及基线方法的复现结果进行了比较。我们发现 DeepSeek-GRM-27B 在总体性能上优于基线方法,并且其性能与强大的公开 RM(例如 Nemotron-4-340B-Reward 和 GPT-4o)相当;通过推理时扩展,DeepSeek-GRM-27B 的性能可以进一步提升并达到最佳的总体结果。详细比较来看,标量 RM(DeepSeek-BTRM-27B, DeepSeek-PairRM-27B)和半标量 RM(CLoud-Gemma-2-27B)在不同基准测试上表现出有偏差的结果:它们在可验证任务(PPE 正确性)上的性能显著优于所有生成式奖励模型(GRM),但在其他不同的基准测试中则各有不足。尽管如此,大多数公开的标量 RM 也表现出严重的领域偏差。大语言模型(LLM)作为裁判(LLM-as-a-Judge)表现出与 DeepSeek-GRM-27B 相似的趋势,但性能略低,这可能是由于缺乏原则性指导所致。总之,SPCT 提升了 GRM 的通用奖励生成能力,并且与标量和半标量 RM 相比,其偏差显著减少。 推理时可扩展性 不同方法的推理时扩展结果如表3所示,整体趋势如图1所示。在使用最多 8 个样本的情况下,我们发现 DeepSeek-GRM-27B 相较于贪婪解码和采样结果,其性能提升幅度最大。DeepSeek-GRM-27B 进一步展现出通过增加推理计算量(最多 32 个样本)来提升性能的强大潜力。元 RM(meta RM)也证明了其在各个基准测试上为 DeepSeek-GRM 过滤低质量轨迹的有效性。通过 Token 概率进行投票,LLM 作为裁判也显示出显著的性能提升,这表明将 Token 概率作为定量权重有助于提高简单多数投票的可靠性。对于 CLoud-Gemma-2-27B,性能提升有限,主要原因是即使其生成的评判理由(critique)变化很大,标量奖励生成仍缺乏方差。总之,*SPCT 提高了 GRM 的推理时可扩展性,而元 RM 则进一步提升了整体的扩展性能*。
消融研究 表格4展示了所提出的 SPCT 不同组件的消融研究结果。令人惊讶的是,即使没有使用拒绝采样批判数据进行冷启动,经过通用指令调整的通用奖励模型 (GRMs) 在经历在线强化学习后性能仍然显著提高 ($66.1\rightarrow 68.7$)。此外,非提示采样似乎比提示采样更重要,这可能是因为提示采样轨迹中出现了捷径。这些结果表明了****在线训练对于通用奖励模型的重要性*。与先前的工作一致,我们确认通用指令数据对于通用奖励模型的性能至关重要。我们发现*原则生成对于 DeepSeek-GRM-27B 的贪婪解码和推理时扩展的性能都至关重要****。对于推理时扩展,元奖励模型引导投票在不同的 $k_{\mathrm{meta}}$ 下表现出鲁棒性。
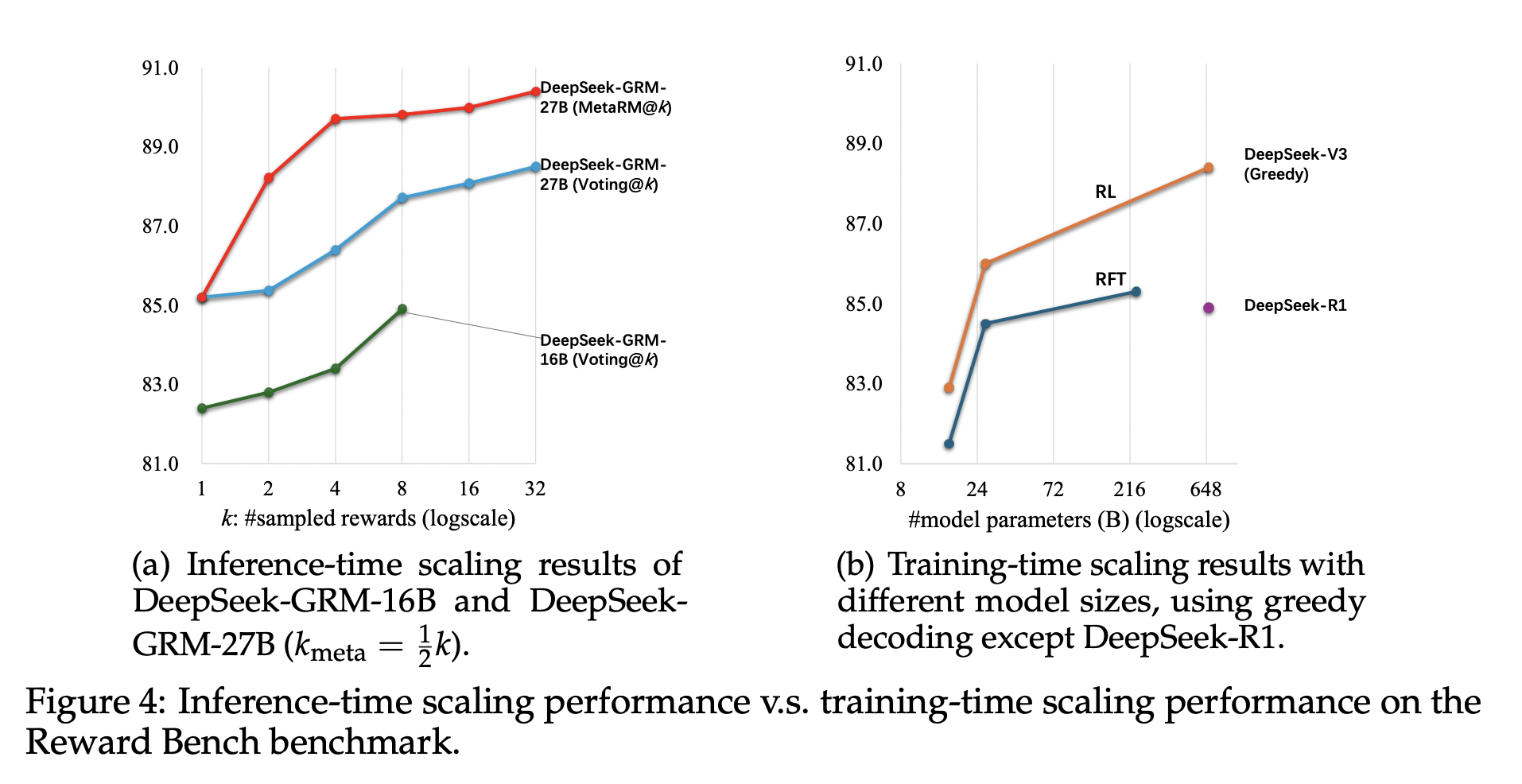
*扩展推理和训练成本* 我们通过使用不同规模的大语言模型进行后训练,进一步研究了 DeepSeek-GRM-27B 的推理时和训练时扩展性能。这些模型在 Reward Bench 上进行了测试,结果如图4 所示。我们发现,使用 DeepSeek-GRM-27B 的 32 个样本进行直接投票可以达到与 671B MoE 模型相当的性能,而元奖励模型引导投票使用 8 个样本即可达到最佳结果,这证明了****与扩展模型规模相比,DeepSeek-GRM-27B 推理时扩展的有效性****。此外,我们使用包含 300 个样本的下采样测试集测试了 DeepSeek-R1,发现其性能甚至不如 236B MoE RFT 模型,这表明为推理任务扩展长思维链并不能显著提高通用奖励模型的性能。