

摘要
移除建模约束和统一跨领域的架构一直是训练大型多模态模型取得最新进展的关键驱动因素。然而,大多数这些模型仍然依赖于许多单独训练的组件,例如特定模态的编码器和解码器。在这项工作中,我们进一步简化了图像和文本的联合生成建模。我们提出了一种 autoregressive decoder-only transformer—JetFormer—它被训练来直接最大化原始数据的似然,而不依赖于任何单独预训练的组件,并且能够理解和生成文本和图像。具体来说,我们利用归一化流模型来获得一个软Token图像表示,该表示与自回归多模态Transformer联合训练。归一化流模型在推理期间既充当感知任务的图像编码器,又充当图像生成任务的图像解码器。JetFormer实现了与最近基于VQVAE和VAE的基线模型相媲美的文本到图像生成质量。这些基线模型依赖于预训练的图像自动编码器,这些自动编码器使用包括感知损失在内的复杂损失混合进行训练。与此同时,JetFormer展示了强大的图像理解能力。据我们所知,JetFormer是第一个能够生成高保真图像并产生强大的对数似然边界的模型。
介绍
“痛苦的教训”一直是机器学习和人工智能研究近期进展背后的主要推动力。 它表明,能够有效利用大量计算资源和数据的一般用途方法,胜过领域专家设计的专用技术。 在此背景下,最突出的例子包括:仅使用 Transformer 解码器的模型,这些模型经过训练用于下一个 Token 预测,其性能优于特定任务的 NLP 系统;以及计算机视觉中的 Transformer 编码器,它们实现了比基于 CNN 的模型更好的质量。 这种趋势在当前将大语言模型 (LLM) 扩展到理解和生成多种模态(例如文本和图像)的尝试中也很明显。 文献中一个有效的范例是使用通过 (VQ)VAE 获得的离散 Token 来建模图像 Token。 这些方法的一个局限性在于,从图像到 Token 以及反之的转换是由一个单独的、冻结的、特定于模态且有损的编码器(和解码器)预先执行的。 因此,此图像编码器可能与手头的实际任务无关,从而限制了最终模型的性能。
为了获得一个能够生成多种模态,且不依赖于预训练(具有局限性)组件的通用架构,我们开发了一种新的生成模型:JetFormer。 它可以从头开始训练,并针对原始训练数据的对数似然进行端到端优化。 我们以文本和像素为例展示了这一点。 为此,我们将用于计算软 Token 图像表示的归一化流与仅解码器的 Transformer 以及软 Token 高斯混合损失相结合。 JetFormer 模型背后的关键洞察在于,强大的归一化流(我们称之为 “jet”,因此得名)可用于将图像编码成适合自回归建模的潜在表示。 直观地说,编码为像素的原始图像块具有非常复杂的结构,这使得直接自回归变得困难重重: 迄今为止,还没有令人信服的演示能够成功实现这一点。 同时,该流模型是无损的,并且可以与(多模态)自回归模型一起进行端到端训练。 在推理时,图像解码器可以随时使用,因为我们的流模型具有闭合形式的可逆性。
尽管我们仅优化对数似然,但值得注意的是,仅仅这样做并不能保证生成具有全局连贯性的图像。与绝大多数关于高保真图像生成的工作类似,我们引导模型专注于高层次的信息。为此,我们探索了两种方法。首先,我们引入了一种基于训练期间图像增强的创新技术。其主要思想是在训练期间添加高斯噪声,并在训练过程中逐渐降低噪声。直观地说,这促使模型在早期阶段优先考虑高层次的信息;即使训练期间的噪声curriculum 受到扩散模型的启发,但在技术层面上却截然不同,并且最终的模型在推理时不会执行渐进式图像去噪。
其次,我们探索了两种管理自然图像中冗余信息的方法。JetFormer 能够轻松地从自回归模型中排除冗余维度的子集。作为一种替代方案,我们探索了使用 PCA 来降低图像维度。我们对 ImageNet 类条件图像生成和网络规模的多模态生成进行了实验,从而证明了 JetFormer 的有效性,并且可以使用单个模型扩展到文本到图像生成和视觉语言理解。
总之,我们的贡献是:
- 我们提出了 JetFormer,一个由 Transformer 和归一化流组成的生成模型,可以从头开始训练,以端到端的方式联合建模文本和原始像素。
- 我们表明,基于噪声学习curriculum的图像增强可以显著提高此类基于似然性的模型的图像生成质量。
- 我们证明了我们提出的端到端模型在网络规模数据上训练时,与不太灵活的技术相比具有竞争力,并且可以生成图像和文本。
相关工作

在文献中,使用 CNN 或 Transformer 以自回归的方式生成自然图像作为离散值像素序列已被广泛探索。 虽然在对数似然方面取得了优异的结果,但这些模型的计算成本很高,并且无法很好地扩展到高图像分辨率。 一系列相关的模型是归一化流,即可逆模型,通过最大化对数似然来训练这些模型,以将图像像素映射到简单的先验。 这些模型的可扩展性更好,但获得的似然性低于自回归模型,并且即使对于低分辨率,在经验上也无法生成高保真图像。
使用 CNN 或 Transformer 以自回归方式生成离散值(子)像素序列的自然图像,已经在文献中得到广泛研究。虽然在对数似然方面取得了优异的结果,但这些模型的计算成本很高,并且难以扩展到高分辨率图像。一个相关的模型家族是归一化流,它是一种可逆模型,通过最大化对数似然来训练,将图像像素映射到简单的先验分布。这些模型具有更好的扩展性,但获得的似然性低于自回归模型,并且在实践中难以生成高保真图像,即使是低分辨率图像也是如此。
最近,一种可扩展的高保真图像生成技术应运而生:通过预训练的、冻结的 VQ-VAE 将高维图像像素空间压缩为低维离散 Token 序列,然后使用 Transformer 解码器对压缩序列进行建模。为了实现语义压缩,VQ-VAE 通常依赖于感知损失和 GAN 损失。此外,基于 VQ-VAE 的表示在密集预测任务中很常见,尤其是在联合建模多个模态时。GIVT 表明,通过直接对 VAE 潜在空间中的特征向量进行建模,而无需任何量化,可以将自编码器和自回归 Transformer 结合应用于连续值序列。在某种程度上相关的是, 探索了用于语音合成的软 Token。VQ-VAE 在视觉-语言模型 (VLM) 的上下文中也变得越来越流行。此类模型通常从头开始在网络规模的数据上进行训练,或者通过组合和微调预训练的视觉编码器和预训练的语言模型来构建,并且可以解决各种可以转化为文本输出的任务。为了使此类模型能够生成像素输出,一种简单的方法是使用 VQ-VAE Token 扩展文本词汇表。其他工作将 VLM 与(潜在)扩散模型相结合,以实现图像生成能力。JetFormer 与此类模型相关,但与之前的模型不同,它不依赖于任何预训练的 (VQ-)VAE 视觉编码器/解码器。
最近,通过预训练且冻结的 VQ-VAE 将高维图像像素空间压缩为低维离散 Token 序列,然后使用 Transformer 解码器对压缩序列进行建模,已经成为一种可扩展的高保真图像生成技术。 为了实现语义压缩,VQ-VAE 通常依赖于感知损失和 GAN 损失。 此外,基于 VQ-VAE 的表示在密集预测任务中很常见,特别是在联合建模多种模态时。 GIVT 表明,通过直接对 VAE 潜在空间中的特征向量进行建模,而无需任何量化,可以将自编码器和自回归 Transformer 结合应用于连续值序列。 在某种程度上相关的是,有人探索了用于语音合成的软 Token。 VQ-VAE 在视觉-语言模型 (VLMs) 的上下文中也越来越受欢迎。 此类模型通常要么从头开始在网络规模的数据上进行训练,要么通过组合和微调预训练的视觉编码器和预训练的语言模型来构建,并且可以解决可以转换为文本输出的各种任务。 为了使此类模型能够进行像素输出,一种简单的方法是用 VQ-VAE Token 扩展文本词汇表。 其他工作将 VLM 与(潜在)扩散模型相结合,以实现图像生成能力。 JetFormer 与此类模型相关,但与之前的模型不同,它不依赖于任何预训练的 (VQ-)VAE 视觉编码器/解码器。
方法
使用自回归 Transformer 对自然图像进行建模面临许多障碍。在像素空间中这样做是一种可行的方法,但它很快就会在计算上变得难以承受。即使是大小为 $256$$\times$$256$$\times$$3$ 的图像也需要预测/采样近 $200\,000$ 个 Token。或者,在 Patch 级别对图像进行建模以控制计算复杂性会带来其自身的挑战。每个 Patch 都是来自复杂分布的样本,并且在单个前向传递中生成其所有维度无法对像素交互进行建模。目前,克服这些问题最常见的方法是利用独立的图像编码器/Tokenizers(以及解码器/Detokenizers)模型,该模型将图像编码为一系列(通常是离散的)Token。这种图像编码器执行语义压缩,从而降低了计算负担。但是,这种类型的方法具有明显的缺点:人们需要容忍由于压缩而造成的精度损失,并致力于提前训练的图像编码器,该编码器可能不适合手头的建模任务。
$256\times256\times3$的图像将需要预测/采样近 $200\,000$ 个 Token。或者,在图像块级别对图像进行建模以控制计算复杂性也会带来自身的挑战。每个图像块都是来自复杂分布的样本,并且在单个前向传递中生成其所有维度无法对像素交互进行建模。目前,克服这些问题的最常见方法是利用独立的图像编码器/分词器(以及解码器/反分词器)模型,该模型将图像编码为(通常是离散的)Token序列。这种图像编码器执行语义压缩,从而减少了计算负担。然而,这种类型的方法存在显着的缺点:人们需要容忍由于压缩造成的精度损失,并致力于提前训练的图像编码器,该编码器可能不适合手头的建模任务。在本文中,我们克服了这两个问题,并提出了 JetFormer,这是一种生成式自回归仅解码器模型,能够对文本和图像进行建模,并直接从原始训练数据中学习。JetFormer 模型是端到端训练的,不依赖于任何有损的特定模态编码器/分词器。我们的模型建立在两个关键见解之上。
首先,我们使用连续的(也称为“软”)Token来表示图像。如 GIVT 所示,Transformer 解码器可以生成 VAE 编码器生成的高保真图像生成的软 Token 序列。具体来说,GIVT 用高斯混合模型 (GMM) 替换了分类预测头,该模型对软图像嵌入的对数似然进行建模。其次,我们使用归一化流模型来学习适合自回归建模的软 Token 图像表示,而不是 VAE(需要提前训练)。由于流模型在设计上是无损的,因此它们不会遭受表示崩溃,并且可以与 Transformer 模型同时训练,而无需辅助损失,从而消除了使用预训练编码器的必要性,并实现了从原始图像进行自回归 Transformer 的完全端到端学习。当然,上述两个见解可以与用于文本的标准 Transformer 相结合,形成一个简单而统一的多模态模型,能够从图像和文本数据中学习。
在本文中,我们克服了上述两个问题,并提出了一种名为 JetFormer 的生成式自回归解码器模型。该模型能够对文本和图像进行建模,并直接从原始训练数据中学习。JetFormer 模型采用端到端训练方式,无需依赖任何有损的、特定模态的编码器或分词器。我们的模型基于两个关键的洞察:首先,我们使用连续的(也称为“软”)Token 来表示图像。正如 GIVT 中所展示的,Transformer 解码器可以生成由 VAE 编码器产生的高保真图像生成的软 Token 序列。具体而言,GIVT 使用高斯混合模型 (GMM) 替换了分类预测头,该模型用于对软图像嵌入的对数似然进行建模。
其次,我们没有采用需要预先训练的 VAE,而是使用归一化流模型来学习一种适用于自回归建模的软 Token 图像表示。由于流模型在设计上是无损的,因此它们不会遭受表示崩溃,并且可以与 Transformer 模型同时训练,而无需额外的损失函数。这消除了使用预训练编码器的必要性,并实现了从原始图像进行自回归 Transformer 的完整端到端学习。自然地,上述两个洞察可以与标准的 Transformer 结合用于文本处理,从而形成一个简单且统一的多模态模型,使其能够从图像和文本数据中进行学习。
使用软 Token 和归一化流在像素空间中建模图像
如上所述,我们使用归一化流模型 $f(x)$ 对图像 $x$ 进行建模,该模型无损地将图像映射到一系列嵌入 $\{z_1, \dots, z_n\}$,我们也称之为“软 Token”。请注意,该流保留了输入维度的总数。然后,这些嵌入由深度自回归模型 $p$ 建模,其中输出使用 GMM 建模,如 GIVT 中提出的那样。然后,我们最大化图像对数似然下界 $L$:
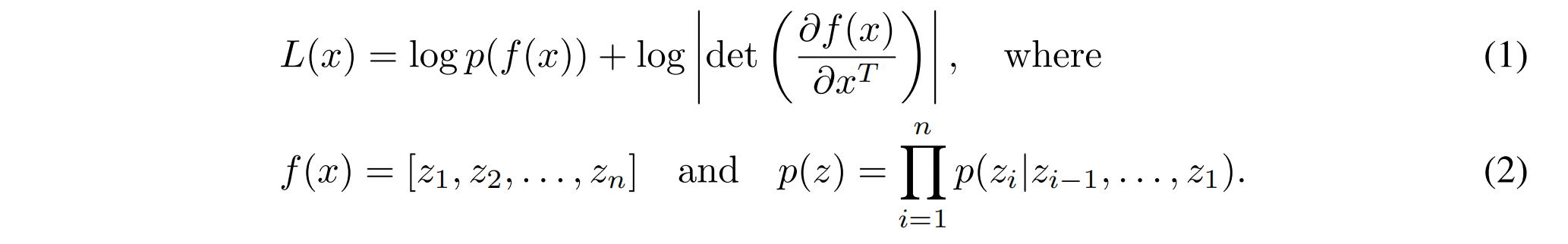
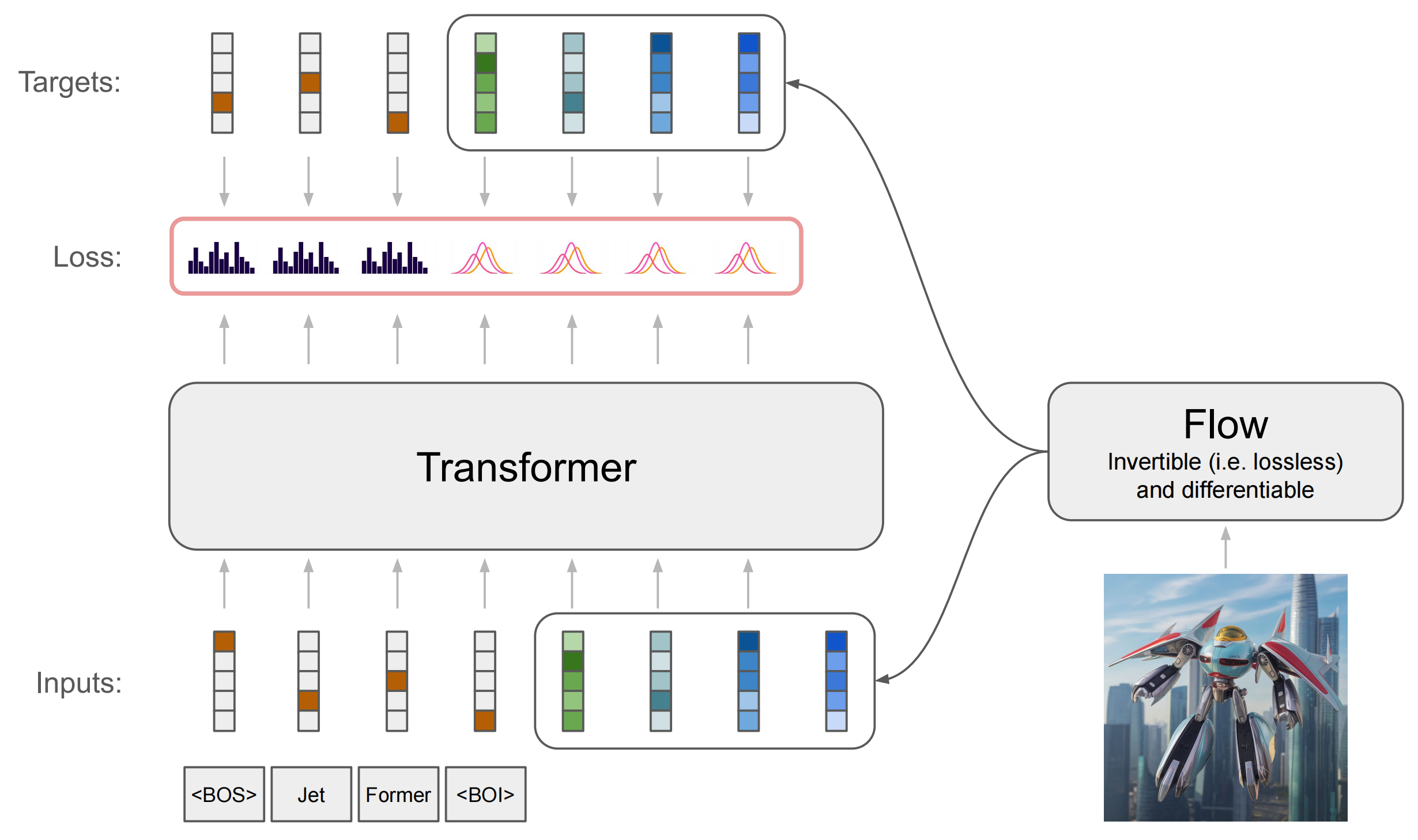
请注意,对数行列式项来自归一化流模型,是数据对数似然的一部分,具体请参见相关资料。此外,为了确保正确性,我们应用图像去量化,如相关文献中所述。这相当于向输入图像 $I$ 添加均匀噪声 $u$,使得 $x = I + u$,其中 $u \sim U[0, 1]$。这保证了我们优化的是离散图像对数似然的下界。为了清楚起见,我们指出 $p$ 和 $f$ 都具有可学习的参数,这些参数通过基于梯度的方法进行优化(通过教师强制进行训练的方式如图1所示)。
简单来说,用于图像的 JetFormer 是一种自回归模型,其输入和目标由流模型生成,该流模型会对输入图像进行重新编码。由于目标具有端到端的特性,因此流模型会被激励去学习一系列嵌入,从而使自回归建模尽可能高效。在推理过程中,自回归模型会生成一系列软 Token,然后需要使用流的逆过程将这些 Token 解码为图像。
提升自然图像的模型质量
虽然 JetFormer 可以直接使用,但我们发现一些建模方面的增强可以极大地提高生成图像的质量。 特别是,分解潜在维度、在采样期间使用无分类器引导以及一种新颖的噪声课程。
Factoring out redundant dimensions
自然图像是冗余的,本质上是低维信号,其低频分量在频谱中占主导地位。JetFormer 的设计能够以一种简单有效的方式利用这一观察结果,提高模型质量,同时减少计算负担。关键的观察结果是,并非可逆流的所有输出维度都需要通过自回归模型进一步处理。我们可以用高斯分布 $p_\mathcal{N}$ 对维度的一个子集(即通道的一个子集)进行建模,而用自回归 Transformer 对剩余的维度进行建模:
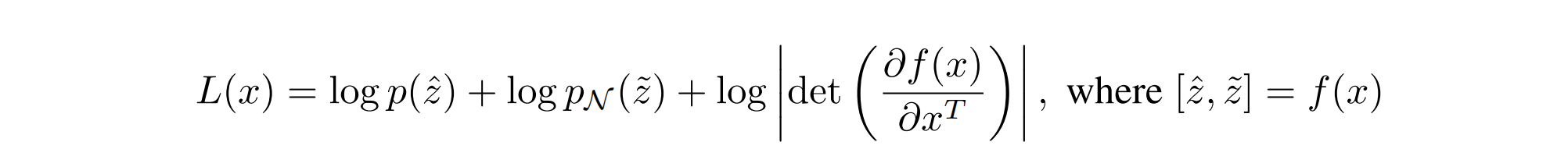
直观地说,我们期望冗余维度被“分解”为 $\tilde z$,因为它们不需要进一步的繁重处理。我们在实验部分和图6c中凭经验验证了我们的直觉。
作为对上述方法的有力补充,我们也考虑了一种更直接的方法来处理图像中的冗余。在将 $x$ 输入到 flow 模型之前,我们将其重塑为扁平化的图像块序列,并沿着通道维度应用一个可学习的、可逆的线性映射 $W$。我们希望这个映射能够学习将扁平化图像块的重要维度与冗余维度分离开来。为此,我们将它的输出 $xW^\top$ 的前 $d$ 个通道输入到归一化流中,并用高斯分布对剩余的通道进行建模。直观地说,考虑到在分解序列的一部分之前应用的变换 $W$ 的简单性,在训练时最小化负对数似然 (NLL) 将确保序列中难以建模的部分由 JetFormer 建模,而低级噪声将被映射到高斯先验。这与概率主成分分析 (PCA) 背后的推理类似。事实上,我们观察到模型学习到的变换非常接近于对图像块应用 PCA(参见图6d),并且我们观察到,当用 PCA 初始化 $W$ 并冻结它时,我们获得了类似的结果。
Classifier-free guidance
遵循扩散模型和自回归图像建模文献中的常见做法,我们采用无分类器引导(CFG),先前已证明其能显著提高样本质量。我们重用基于分布的变体,该变体通过拒绝采样实现,用于 GMM,无需修改。
RGB NOISE CURRICULUM DURING TRAINING
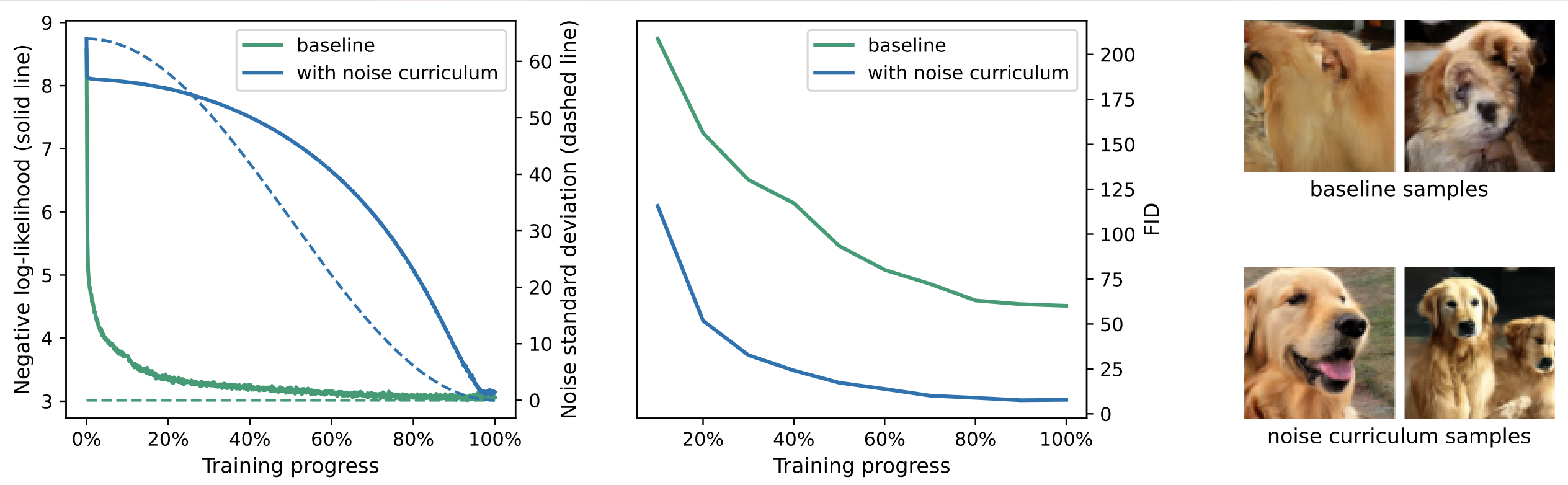
为了提高图像质量,通常会将数据显式地分解为语义上有意义的部分。一种方法是将 RGB 像素建模为颜色深度和/或分辨率不断增加的序列。类似地,向 RGB 像素添加噪声与降低颜色深度和有效分辨率密切相关。这促使人们将扩散模型解释为:去噪器根据预定义的噪声计划在不同的噪声水平下进行训练,从而学习由噪声计划所引导的像素空间中的分层表示。基于这种直觉,我们通过引入“噪声课程”来改变训练过程:在 JetFormer 训练期间添加高斯像素噪声。噪声在训练开始时最强,并逐渐衰减至零。我们对噪声标准差使用余弦衰减计划。 在训练的初期,当向图像添加强烈的(高方差)噪声时,JetFormer 学习建模粗略的图像信息(参见图6b)。随着训练的进行,模型逐渐学习更精细的细节,同时“记忆”先前学习的模式。在训练结束时,JetFormer 使用正确的训练分布。直观地说,这种方案优先考虑对高级图像结构的建模,而不会牺牲整体性能。重要的是,与扩散模型不同,噪声课程仅在训练期间充当数据增强。该模型不以噪声强度为条件,并且在推理时,图像不会逐渐去噪,而是以自回归的方式在归一化流的潜在空间中生成。
对于一个整数值的 RGB 图像 $I$,带噪声的图像通过 $\lfloor I + \sigma_t N(0, \mathrm{I}) \rfloor$ 获得,其中噪声尺度 $\sigma_t$ 是训练进度 $t \in [0, 1]$ 的函数,遵循余弦计划 ${\sigma_t = \sigma_0 \tfrac{1+\cos(t \pi)}{2}}$。噪声计划的形状在图3中可视化。
像素和文本的联合生成建模
我们探索使用 JetFormer 进行多模态生成建模,该模型能够在所有模态上执行判别和生成任务,尤其侧重于图像和文本。这类复杂的模型通常在图像和文本的交错序列上进行训练,并经常进行训练后的优化,从而实现少样本图像到文本(例如,图像描述)和文本到图像(例如,图像编辑)的能力。在此,我们沿用 的方法,将来自网络的图像-文本对作为更复杂的交错设置的替代,并且不涉及后续的训练步骤。虽然概念上较为简单,但这使我们能够探索视觉-语言理解任务,例如图像描述和 VQA,以及文本到图像的生成。将上一节中讨论的图像生成方法扩展到此设置非常直接:我们只需扩展 Transformer 主干网络,将生成软 Token 的能力扩展到对标准语言 Tokenizer 生成的语言 Token 进行建模,并使用单独的预测头和 softmax 函数。我们训练图像 Token 后接文本 Token 的序列,以及文本 Token 后接图像 Token 的序列,但仅将损失函数应用于序列的后半部分(模态)。我们使用各自的负对数似然,并使用权重来平衡两者。我们观察到,将损失函数应用于整个序列会导致较差的结果,这可能是因为预测图像前缀实际上意味着无条件地对网络图像进行建模,而这是一项极具挑战性的任务。我们期望对于交错序列而言,这种情况会有所改变,因为交错序列可能会提供更强的调节信号。
对于文本到图像的生成,文本前缀充当条件作用,图像生成过程如第3.1节所述。对于图像到文本的生成,归一化流充当图像编码器。该模型在生成和理解过程中使用相同的软 Token 空间。
实验
架构
我们依赖于来自 (Anonymous, 2024) 的简单、基于 Transformer 的设计来实现归一化流模型。这种设计使用仿射耦合层(预测元素级的缩放和偏移),该层由空间和通道方向的分裂函数组成,用于将激活值分成两部分,并使用堆叠的 ViT 块 应用于一半的激活值,以推断仿射变换。在这里,我们只使用通道方向的分裂,因为我们在初步实验中发现空间分裂并没有提高建模质量。我们将深度设置为 32 个耦合块,每个耦合块由 4 或 6 个宽度为 512 的 ViT 块堆叠而成,并具有 8 个注意力头。当输入完整图像时,此模型的(输入和输出)特征形状为 $(\frac{H}{p}, \frac{W}{p}, 3p^2)$,当在使用密集可逆映射或 PCA 降低维度后应用流时,特征形状为 $(\frac{H}{p}, \frac{W}{p}, d)$。对于图像大小 $H=W=256$ 和 patch 大小 $p=16$,这相当于 $256$$\times$$768$,在展平空间维度后,以及将维度降低到 $d=128$ 后,相当于 $256$$\times$$128$。
 对于潜在的自回归解码器骨干网络,我们依赖于 Gemma 架构。 我们考虑了 3 种不同的模型结构,参数量分别为 3.5 亿、7.5 亿和 13 亿,这些结构很大程度上受到了先前用于图像生成的解码器模型的启发。 对于 GMM 预测头,除非另有明确说明,否则我们将混合成分的数量设置为 $k=1024$,使用维度为 $d=128$ 的多元高斯分布,且具有对角协方差。 对于文本,我们使用 sentencepiece tokenizer,其词汇量大小为 32k,该 tokenizer 在 C4 语料库的英文部分上进行训练,由 提供。 我们将文本 Token 的最大数量设置为 64,但不显式地对填充 Token 进行建模(即,在训练期间,我们屏蔽掉与填充 Token 相对应的注意力元素,并调整 RoPE 位置以跳过它们)。 在训练用于类条件图像生成时,我们为每个类使用 16 个学习到的 Token 的前缀(而不是单个 Token),因为我们观察到这可以提高样本质量。
对于潜在的自回归解码器骨干网络,我们依赖于 Gemma 架构。 我们考虑了 3 种不同的模型结构,参数量分别为 3.5 亿、7.5 亿和 13 亿,这些结构很大程度上受到了先前用于图像生成的解码器模型的启发。 对于 GMM 预测头,除非另有明确说明,否则我们将混合成分的数量设置为 $k=1024$,使用维度为 $d=128$ 的多元高斯分布,且具有对角协方差。 对于文本,我们使用 sentencepiece tokenizer,其词汇量大小为 32k,该 tokenizer 在 C4 语料库的英文部分上进行训练,由 提供。 我们将文本 Token 的最大数量设置为 64,但不显式地对填充 Token 进行建模(即,在训练期间,我们屏蔽掉与填充 Token 相对应的注意力元素,并调整 RoPE 位置以跳过它们)。 在训练用于类条件图像生成时,我们为每个类使用 16 个学习到的 Token 的前缀(而不是单个 Token),因为我们观察到这可以提高样本质量。
Training recipe
我们通过教师强制训练方法,在离散文本和软 Token(flow 隐变量)的连接序列上训练潜在的仅解码器骨干网络,对于 NLL,根据 Token 的各自分布(文本 Token 为分类分布,软 Token 为 GMM)。对于每个示例,图像-文本序列或文本-图像序列是随机采样的。归一化流(或可学习的可逆 patch embedding)与 Transformer 骨干网络端到端地一起训练。这不需要任何专门的技术,因为 GMM 的 NLL 对于 GMM 参数以及它所评估的软 Token/特征都是可微的。当使用图像前缀训练 captioning 时(即对于图像-文本序列,其中归一化流用作视觉编码器),我们在预训练期间停止 flow 输出的梯度。我们没有观察到传递梯度时性能有所提高。我们使用 Adam 优化器,学习率为 $10^{-3}$,分离权重衰减为 $10^{-4}$,$\beta_2$ 参数为 $0.95$,并将梯度范数裁剪到 1.0。我们将批量大小设置为 4k。我们还在自注意力的输出处和 MLP 块应用概率为 0.1 的 dropout,我们发现这可以提高图像样本质量。对于类别条件图像生成和文本生成图像,我们都以 10% 的概率删除条件,并用学习到的 [NOLABEL] Token 替换它以进行 CFG。除非明确说明,否则我们将 RGB 噪声计划应用于 Section3.1中描述的输入图像,初始噪声标准差为 $\sigma_0 = 64$(对于范围 $[0, 255]$ 中的像素值)。我们衰减到 $0$ 用于 ImageNet 设置,衰减到 $3$ 用于多模态设置。受到基于 VAE 的 GIVT 的启发,对于每个示例,从 VAE 编码器(即近似后验)中采样一个 latent,这可能具有正则化效果,我们向 flow 隐变量添加标准差为 0.3 的高斯噪声。我们将图像 NLL 归一化为每像素比特数,这在图像生成建模文献中很常见,并将文本 NLL 的权重应用为 $0.0025$,这样每个 Token 的损失大小对于两种模态大致相同。
训练数据
为了训练类别条件图像生成模型,我们使用 ImageNet1k 数据集。对于多模态生成,我们依赖于 WebLI 数据集中的图像-文本对。在这两种情况下,我们都调整图像大小,使较短边为 256 像素,同时保持宽高比,并提取一个 $256$$\times$$256$ 的中心裁剪。除了前面描述的 RGB 噪声之外,我们不应用任何数据增强,除了在 ImageNet1k 上进行随机左右翻转。在 ImageNet1k 上,我们在消融实验中训练 100 个 epoch,否则训练 500 个 epoch。在 WebLI 上,我们为每个模态训练 10 亿个样本。因此,仅用于文本到图像模型的训练使用 10 亿个样本,而同时支持图像到文本(理解)任务的模型的训练总共使用 20 亿个样本。
评估和指标
根据扩散模型领域的文献,我们使用 ADM FID 评估套件(包含 50k 参考样本)以及精确率/召回率来评估 ImageNet1k 上的图像样本质量。 对于文本到图像的生成,我们采用常见的 MS-COCO FID-30k,为来自 30k 随机采样的 COCO 验证图像的标题生成图像,并根据来自完整 COCO 验证集的参考统计数据评估 FID。 我们报告这个指标,包括零样本学习和在 COCO 训练集上进行微调之后的结果。 作为图像理解任务,我们考虑 ImageNet 零样本学习分类,并进行微调以用于图像描述(报告 CIDEr 分数)和视觉问答(VQA,测量 VQAv2 准确率)。
类条件图像生成
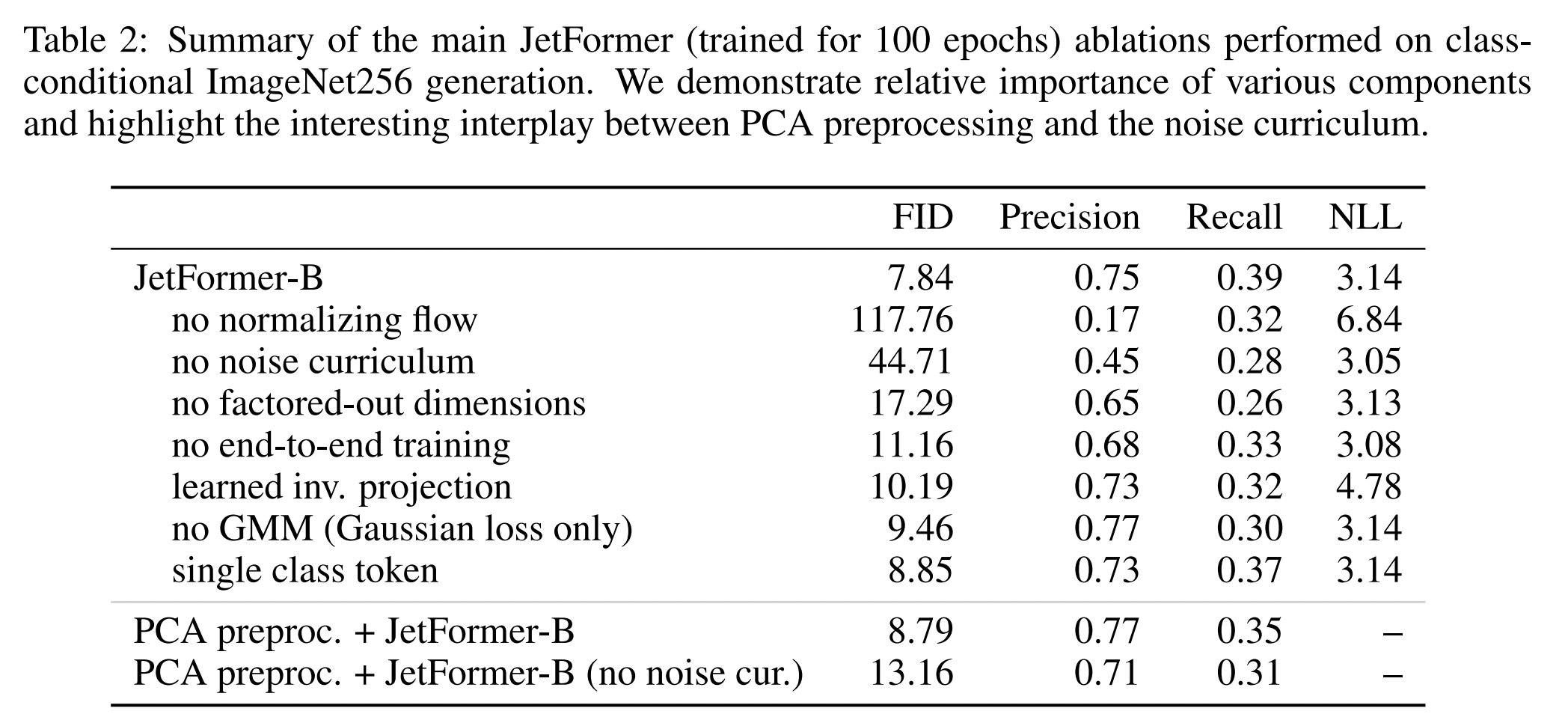
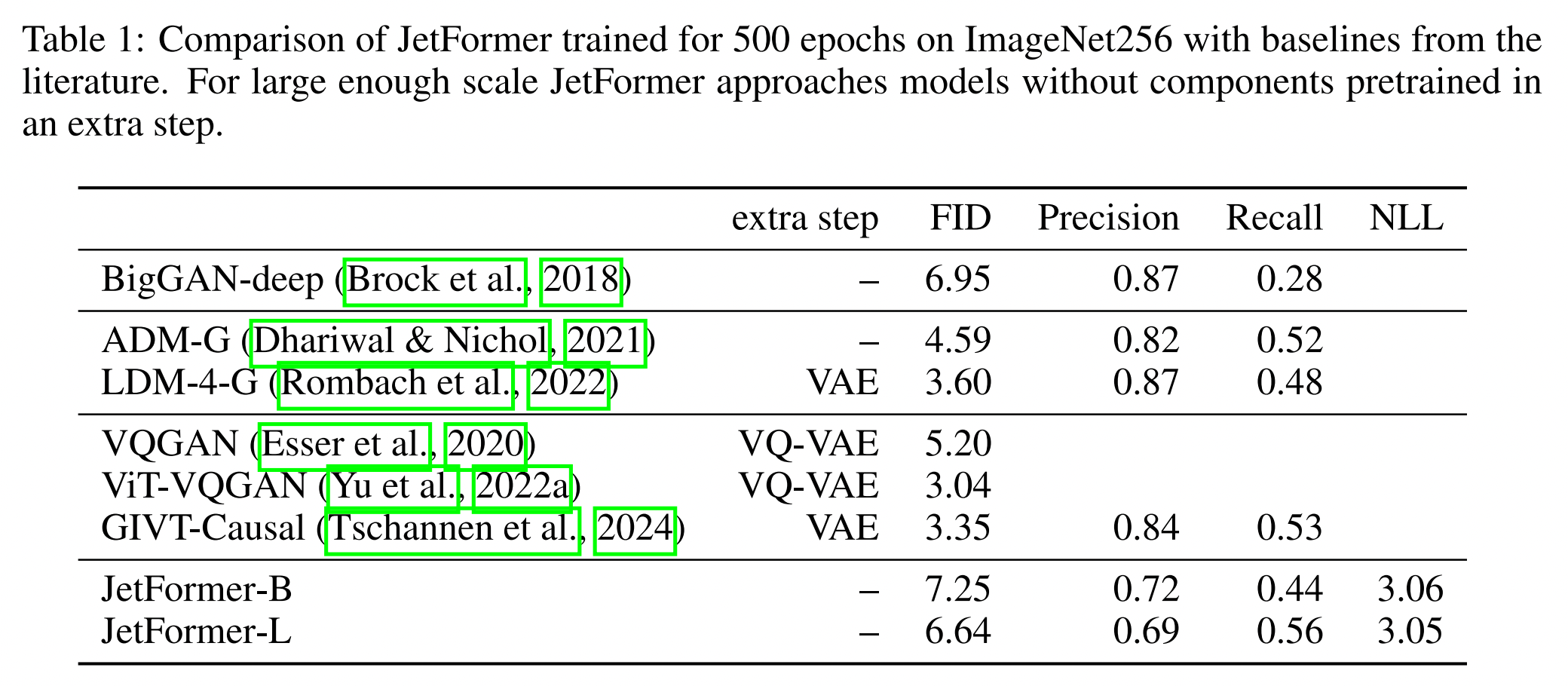
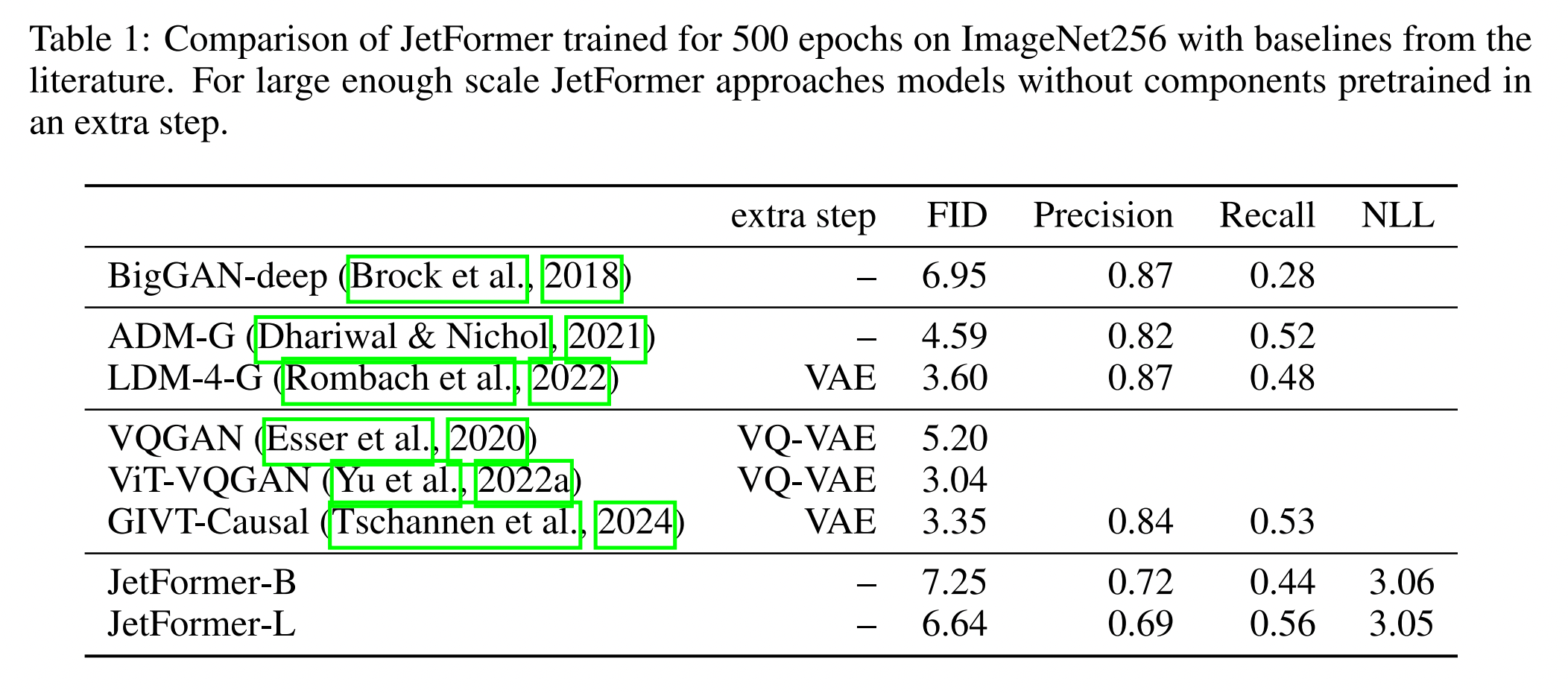
表1展示了 JetFormer 在 ImageNet 上以 $256$$\times$$256$ 图像分辨率训练得到的样本质量,以及文献中的一些基线模型。模型样本展示在图2。尽管 JetFormer 是一个显式的 NLL 模型,并且没有使用高级图像编码器,但我们的 JetFormer 模型与这些基线模型相比具有竞争力。有趣的是,JetFormer 具有 $0.56$ 的高召回率。我们假设这是因为我们的模型是一个显式的对数似然模型,因此不会受到模式崩溃的影响。表2展示了 JetFormer 关键设计选择的消融实验:
- 移除归一化流会导致性能的灾难性损失。这证实了我们的直觉,即使用流模型重新编码图像像素至关重要。
- 省略噪声课程同样会导致更差的结果。
- 我们还证实了在流模型之后不分解维度会导致质量下降。
- 首先训练归一化流,以最小化相对于高斯先验的负对数似然(NLL),然后在冻结的流模型的潜在表示上训练自回归 Transformer,会导致比端到端训练更低的样本质量。
- 在流模型之前使用可学习的线性映射分解维度会带来更好的结果,但性能不如流模型之后的分解。
- 将软 Token 损失的 GMM 分量数量从 1024 减少到 1 会导致相对较小的性能下降和召回率的显著下降,表明更多的混合成分能够更好地覆盖分布。
- 最后,使用单个类别 Token(而不是 16 个 Token)进行类别条件化会导致性能略有下降,这可能是因为条件信号较弱。有趣的是,我们观察到在 PCA 变换后对图像进行建模会导致结果略微变差。然而,在存在 PCA 的情况下,噪声课程的重要性有所降低。这突出了在图像中优先考虑重要的高级信息的重要性,如果视觉质量是最终目标。这也表明,手动预处理可能会降低对各种建模技巧的需求,但也表明,如果方法得当,完整的端到端建模仍然更胜一筹。
噪声学习策略的影响
我们已经试验了不同程度的初始噪声,并且通常发现对于 $256$ $\times$ $256$ 图像,在训练期间将标准差为 $64$ 的初始噪声衰减至 $0$ 对于 ImageNet 设置来说是最好的。初始噪声水平为 $128$、$64$、$32$ 和 $0$ 分别导致 FID (Frechet Inception Distance) 为 $8.62$、$7.84$、$8.59$ 和 $44.71$。对于多模态设置,我们观察到将噪声标准差衰减至 $3$(因此留下少量噪声)可以提高 FID (Frechet Inception Distance)。
在图3中,我们展示了初始标准差为 $64$ 的噪声学习策略的效果。首先,我们观察到,与无噪声基线相比,最终的 NLL (负对数似然) 没有受到显着影响。然而,正如预期的那样,由于强噪声,训练的初始阶段具有更差的 NLL (负对数似然)。其次,我们证明了启用噪声学习策略后,FID (Frechet Inception Distance) 显着提高。这也可以通过来自无噪声模型和具有噪声的模型的最终样本来证明。后者更加强调高级图像结构。
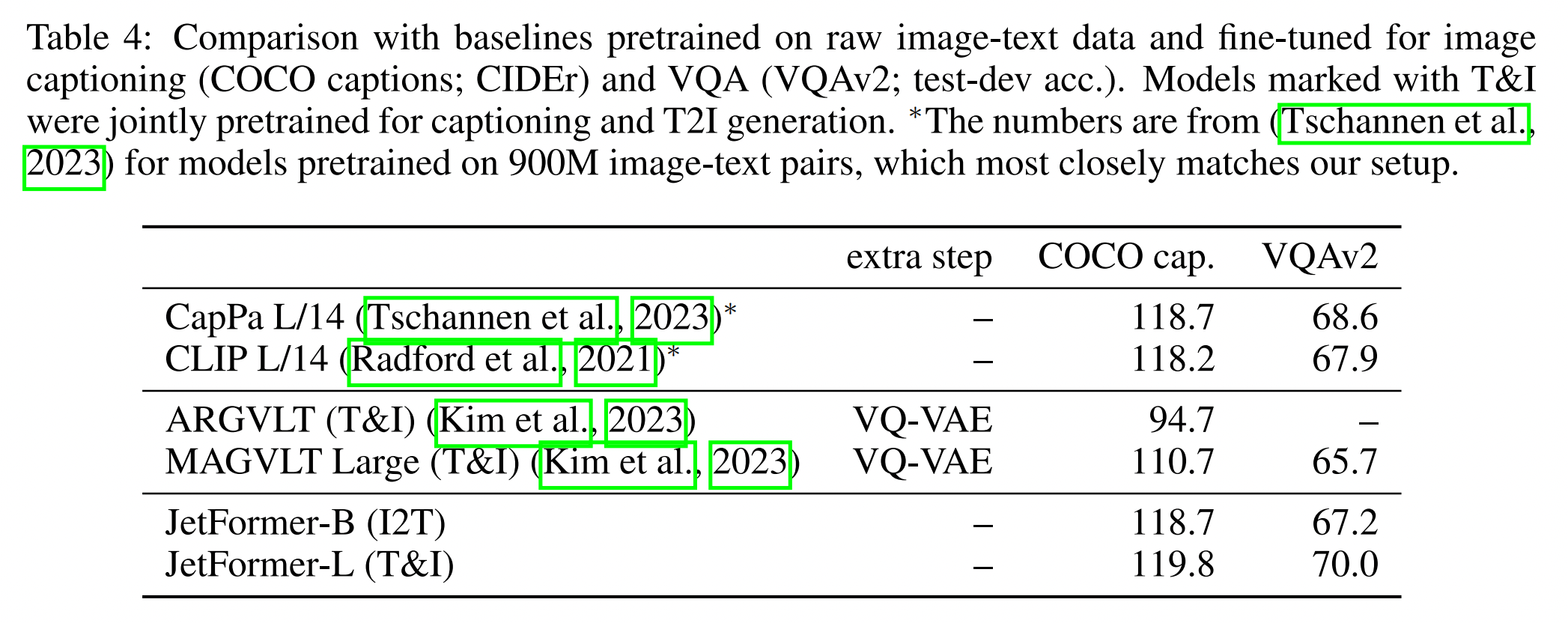
多模态生成与理解

结论
在本文中,我们介绍了 JetFormer,这是一种新型的生成模型,它结合了归一化流和具有软 Token 的自回归模型。据我们所知,它是第一个图像模型,能够合成高分辨率图像,并为原始图像提供显式(且具有竞争力)的 NLL 边界。JetFormer 是一个完全端到端可训练的模型(没有预先训练的组件),这意味着它可以完全针对手头的任务进行定制,而不会受到外部和冻结组件的限制。能够计算 NLL 也是我们模型的一个重要特征。NLL 是一个与压缩能力密切相关的有形分数,可用于比较不同建模类别的各种生成模型或用于爬山算法。此外,通过测量 NLL 分数,可以确保不存在模式崩溃,因为模式崩溃会导致保留数据上的 NLL 恶化。
我们注意到,目前形式的 JetFormer 也存在一些局限性。其样本的视觉质量落后于利用预训练潜在表示的最先进的扩散模型。此外,JetFormer 的完全端到端性质也带来了更高的计算要求。然而,鉴于 JetFormer 的简单设计,我们相信它可以很好地扩展,从而使端到端训练的优势能够充分实现。