

摘要
大语言模型 (LLM) 在解决复杂的推理任务方面表现出了卓越的性能,这得益于诸如思维链 (CoT) 提示等机制,该机制强调冗长、逐步的推理过程。然而,人类通常采用一种更为高效的策略:起草简洁的中间想法,仅捕捉必要的关键信息。在这项工作中,我们提出了一种新颖的范式——Chain of Draft (CoD),它受到人类认知过程的启发,旨在让大语言模型在解决任务时生成最小化但信息丰富的中间推理输出。通过减少冗余信息并专注于关键见解,CoD 在准确性方面能够与 CoT 相媲美甚至超越 CoT,同时仅消耗 7.6% 的 Token,从而显著降低了各种推理任务的成本和延迟。
介绍
OpenAI o1 和 DeepSeek R1 等推理模型的最新进展,已推动大语言模型 (LLM) 借助思维链 (CoT) 等技术,在复杂任务上达到前所未有的性能。这种范式鼓励模型将问题分解为逐步探索的过程,模仿人类的结构化推理方式。 尽管这种方法非常有效,但它在推理阶段需要消耗大量的计算资源,导致输出冗长且延迟较高。 这种冗长性与人类解决问题的方式形成了鲜明对比:我们通常依赖简洁的草稿或速记笔记来捕捉关键见解,避免不必要的详细阐述。 受此差异的启发,我们提出了一种名为 Chain of Draft (CoD) 的新型提示词策略。 该策略通过优先考虑效率和极简主义,使模型推理过程更贴近人类的思维模式。 与冗长的中间步骤不同,Chain of Draft 鼓励大语言模型在每个步骤中生成简洁且信息密集的输出。 这种方法可以在不牺牲准确性的前提下,降低延迟和计算成本,从而使大语言模型更适用于对效率有较高要求的实际应用。
草稿链背后的直觉源于人类外化思考的方式。在解决复杂任务时——无论是解决数学问题、撰写文章还是编写代码——我们通常只记录下有助于我们取得进展的关键信息。通过模仿这种行为,大语言模型可以专注于推进解决方案,避免冗长的推理过程带来的额外开销。
为了评估草稿链的有效性,我们对各种需要多步骤推理的基准测试进行了实验,包括算术推理、常识推理和符号推理。实验结果表明,与标准的思维链方法相比,这种极简方法在保持甚至提高准确性的同时,显著降低了 Token 消耗量和延迟。
本文的贡献主要体现在以下三个方面:
- 我们提出了一种受人类认知过程启发的简洁推理提示策略,即草稿链。
- 我们通过实验验证了草稿链可以在不牺牲准确性的前提下,显著降低延迟和成本。
- 我们探讨了草稿链对大语言模型的设计、部署和实际应用的影响。
相关工作
最近,涌现出各种推理语言模型,包括 OpenAI 的 o1、阿里巴巴的 QwQ 和 DeepSeek 的 R1,它们在解决复杂任务方面表现出显著的改进。这些模型利用结构化推理方法来增强鲁棒性和问题解决能力。“思维链”(Chain-of-Thought,CoT)推理的概念为大语言模型(LLM)中的推理建立了一种基础方法。在此基础上,出现了更复杂的拓扑结构,如树和图,使大语言模型能够解决日益复杂的问题。其他增强功能包括自洽性 CoT,它结合了验证和反思机制来增强推理可靠性;以及 ReAct,它将工具使用集成到推理过程中,允许大语言模型访问外部资源和知识。这些创新共同扩展了大语言模型在各种应用中的推理能力。
虽然结构化推理能够显著提升大语言模型解决复杂问题的能力,但同时也大幅增加了得出最终答案前的 Token 消耗。这使得结构化推理难以应用于对成本和延迟都较为敏感的场景。此外,模型常常缺乏对任务复杂度的感知,即使面对简单任务也容易过度思考,造成不必要的资源浪费。诸如流式传输等技术,旨在通过逐步提供部分输出来降低感知延迟,而非等待生成完整的输出序列。然而,这种方法无法完全缓解整体延迟或计算成本,并且通常不适用于思维链推理,因为中间步骤往往不适合直接呈现给最终用户。
@skeleton_of_thought 提出了 Skeleton-of-Thought (SoT),这是一种首先引导大语言模型 (LLM) 生成答案的骨架轮廓,然后并行解码以减少延迟的方法。 虽然 SoT 有助于降低延迟,但它并没有降低计算成本,并且仅限于可以有效并行化的问题。 @draft_n_verify 采取了不同的方法,它首先通过选择性地跳过中间层,以较低的质量但更高的速度生成草稿 Token,然后在单个前向传递中验证草稿。 我们的方法 CoD 可以与这些方法结合使用,以进一步减少延迟。
@latent-cot 提出了 Coconut,旨在训练大语言模型 (LLM) 在连续潜在空间中进行推理,而不是像传统方法那样在自然语言空间中进行推理,它使用大语言模型的最终隐藏状态来表示推理过程。 虽然 Coconut 降低了延迟和计算成本,但它在诸如 GSM8k 等复杂任务中的准确性有所降低。 此外,它失去了自然语言推理的可解释性,并且不能应用于像 GPT 和 Claude 这样的黑盒模型。
与我们的工作最接近的是简明思维 (CCoT) 和 token 预算感知 LLM 推理 (TALE)。CCoT 建议为推理步骤使用固定的全局 token 预算。然而,不同的任务可能需要不同的预算,以实现性能和成本之间的最佳平衡。此外,大语言模型 (LLM) 可能无法遵守不切实际的预算,通常会生成远超预期的 token。@budget 通过基于推理复杂性动态估计不同问题的全局 token 预算来扩展了这个想法。然而,这种方法需要额外的 LLM 调用来估计预算,这会增加延迟。此外,它假设模型可以准确预测请求的复杂性,从而限制了其在更复杂的任务中的适用性,在这些任务中,推理过程可能需要反思、自我纠正或外部知识检索。相比之下,我们的方法采用每步预算,允许无限的推理步骤,这使其更适应各种结构化推理技术。
Chain-of-Draft 提示
思维链 (CoT) 提示策略已在各种任务中展示出显著的有效性,尤其是在那些需要复杂多步骤推理的任务中。然而,大语言模型 (LLM) 经常产生过于冗长的推理步骤,在得出最终答案之前消耗大量的 Token。相比之下,人类在解决涉及多步骤推理的复杂问题(例如数学或逻辑难题)时,往往会采取更简洁的方法。人类通常只记下必要的中间结果——最少的草稿——以促进他们的思考过程,而不是详细阐述每一个细节。受这种自然倾向的启发,我们提出了一种名为 Chain-of-Draft (CoD) 的新型提示策略。这种方法旨在通过限制每个推理步骤中使用的字数来减少冗长,仅关注推进所需的必要计算或转换。为了说明标准提示、思维链提示和我们提出的 Chain-of-Draft 提示之间的区别,请考虑以下简单的算术问题:

另一方面,“思维链 (Chain-of-Thought)” 提示方法提供了一个详细的推理过程。虽然这种回复是准确且易于理解的,但它包含了关于 Jason、Denny 和棒棒糖的不必要细节,这些细节与解决这个数学问题无关。这种冗余的信息会增加 Token 数量,并导致更长的回复延迟。

相比之下,“Chain-of-Draft” 提示方法将推理过程精简为最简化的抽象表达。它将推理过程提炼为一个简洁的等式,只关注得出解决方案所必需的基本数学运算。通过去除不相关的上下文细节,“Chain-of-Draft” 显著减少了 Token 数量,同时保持了透明度和正确性。
实验
在实证实验中,我们遵循原始 CoT 论文,在 3 个类别的任务上进行评估:算术推理、常识推理和符号推理。我们选择了具有代表性的任务,在这些任务中,原始 CoT 显著提高了相对于没有推理的基线的准确性。具体而言,我们选择 GSM8k 用于算术推理;来自 BIG-bench 的日期理解和体育理解用于常识推理;以及 CoT 论文中介绍的抛硬币任务用于符号推理。
实验设置
我们比较了三种不同的提示词策略:CoT、CoD 和标准提示词(作为基线)。
我们使用标准的少样本学习提示词,其中模型被给予输入-输出对作为上下文示例。要求大语言模型直接返回最终答案,无需任何推理或解释。
我们遵循 CoT 论文附录中提供的完全相同的少样本学习示例,但最终答案放在四个井号 (####) 之后,以便更稳定地提取答案。
在 CoD 中,我们也要求模型逐步思考。但是,要求模型将每个推理步骤限制为最多五个单词。请注意,我们不以任何方式强制执行这种限制,这只是一个促进简短推理步骤的通用指南。对于每个少样本学习示例,我们还包括作者手动编写的草稿链 (Chain of Draft)。
每种提示词策略的完整系统提示词如下所示。

我们使用两个最受欢迎的旗舰模型评估了每个任务:OpenAI 的 GPT-4o (gpt-4o-2024-08-06) 和 Anthropic 的 Claude 3.5 Sonnet (claude-3-5-sonnet-20240620)。
算术推理
我们首先考虑衡量大语言模型算术推理能力的数学问题。GSM8k 已经成为评估语言模型算术推理能力的首选基准,它提供了一个包含 8,500 个不同的小学水平数学问题的综合数据集。每个问题都配有详细的逐步解决方案,强调算术、几何、代数和逻辑推理技能。
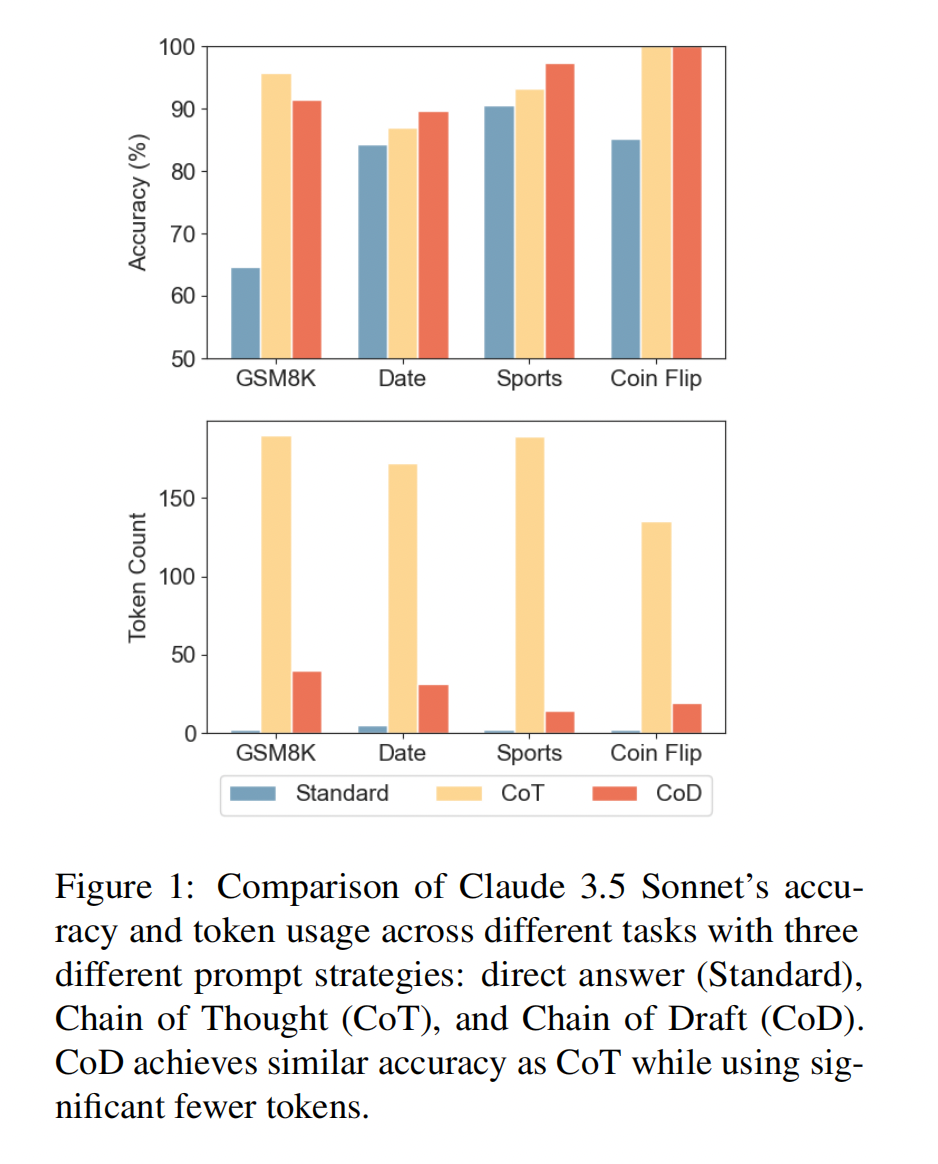
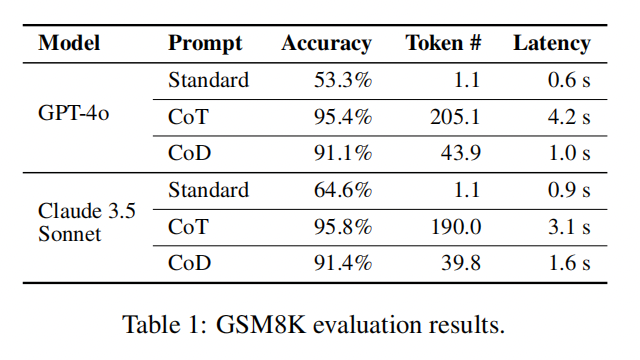
评估结果如表1所示。该数据集对 GPT-4o 和 Claude 3.5 Sonnet 在使用标准提示词时提出了重大挑战,分别产生了 53.3% 和 64.6% 的准确率。然而,通过应用思维链 (CoT),两种模型都超过了 95% 的准确率,尽管代价是每个响应生成大约 200 个 Token。相比之下,chain-of-draft 方法使两种模型都达到了 91% 的准确率,同时每个响应仅需要约 40 个 Token,从而将平均输出 Token 数量减少了 80%,并将平均延迟分别减少了 76.2% 和 48.4%。
常识推理
我们评估了来自 BIG-bench 的日期理解和体育理解任务,以证明 CoD 在常识推理中的有效性。为了保持一致性,我们使用与算术推理评估中使用的相同的系统提示词。
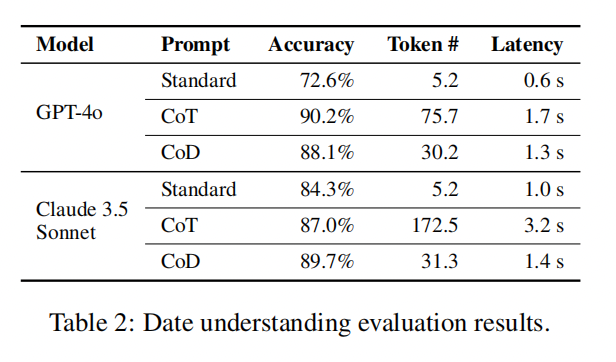
评估结果如表2所示,CoD 通过生成比 CoT 少得多的 Token,显著降低了延迟和成本。此外,在各种情况下,CoD 在准确性方面优于 CoT。值得注意的是,思维链提示词导致 Claude 3.5 Sonnet 的响应过于冗长,尤其是在体育理解任务中,CoD 将平均输出 Token 从 189.4 减少到 14.3,降幅达 92.4%。
符号推理
最初的 CoT 论文介绍了一个抛硬币的任务,该任务要求大语言模型预测一系列抛硬币操作后,硬币的哪一面会朝上。由于原始数据集未公开,我们按照其设计思路,合成了包含 250 个样本的测试集。具体而言,我们依据 NameDataset,在美国地区最常用的前 1000 个名字中随机选取了 4 个名字,并随机决定是否为每个名字执行抛硬币操作。以下是一个评估数据的示例:
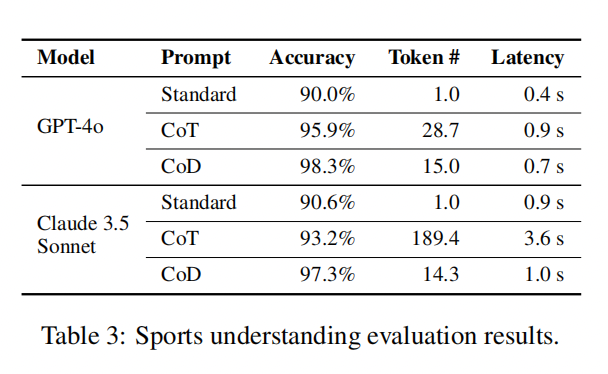
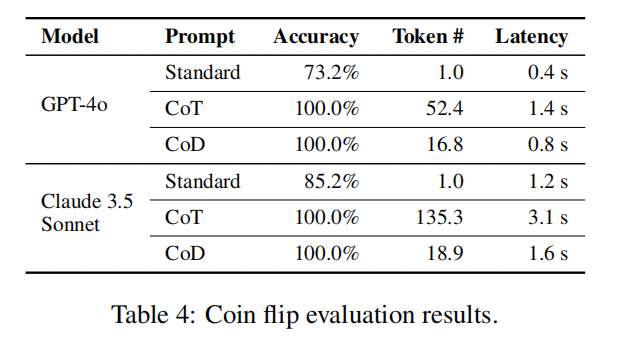
表3展示了 GPT-4o 和 Claude 3.5 Sonnet 的评估结果。在使用标准提示词的情况下,它们的准确率分别为 73.2 % 和 85.2 %。然而,通过 CoT 和 CoD 方法,两者的准确率均达到了完美的 100 %。此外,与 CoT 相比,CoD 显著降低了 Token 的使用量,GPT-4o 降低了 68 %,Claude 3.5 Sonnet 降低了 86 %。
我们需要多少个词
在之前的实验中,我们指示大语言模型(LLM)将推理步骤限制在最多 5 个词。在本节中,我们将对最佳词数限制进行消融研究。
不同模型尺寸上的 CoD 表现
为了理解 CoD 在不同尺寸模型上的表现,我们还使用 Llama 3.1 的 8B、70B 和 405B 模型评估了 GSM8K。
讨论
在大语言模型 (LLM) 的推理能力研究中,延迟问题经常被忽视。然而,对于许多实时应用而言,在保持高质量响应的同时,低延迟至关重要。本文提出了一种名为“草稿链 (CoD)”的新方法,它在实现与标准思维链 (Chain-of-Thought) 提示策略相当甚至更高准确率的同时,显著降低了推理所需的延迟。与传统方法通常涉及冗长的推理步骤不同,CoD 利用简洁的推理草稿来加速响应生成,且不牺牲正确性。此外,CoD 还具有显著的成本优势。通过压缩推理步骤,它减少了少样本学习 (few-shot) 提示所需的输入 Token 数量,并缩短了输出 Token 长度,从而直接降低计算成本。这种 Token 效率使得 CoD 在对成本敏感的场景中尤其具有吸引力,例如大规模部署大语言模型 (LLM) 或具有严格预算约束的应用。
CoD 证明了大语言模型中有效的推理并不一定需要冗长的输出,它提供了一种替代方案,即在保持推理深度的同时,最大限度地减少冗余。未来的工作可以探索将 CoD 与其他降低延迟的方法相结合,例如自适应并行推理或多通道验证,以进一步优化在不同应用领域中的性能。此外,CoD 紧凑推理背后的原理可以启发新的策略,通过使用紧凑推理数据进行训练来改进推理模型,同时保持大语言模型的可解释性和效率,从而帮助弥合推理研究驱动的改进与现实世界系统的实际需求之间的差距。