
GPT-4.5正式发布,作为"研究预览版"面向OpenAI Pro会员(200美元/月)及持有API密钥的开发者开放。
目前定价体系极为高昂:输入Token每百万75美元,输出Token每百万150美元。作为对比,o1模型价格为15/60美元,GPT-4o仅需2.50/10美元。
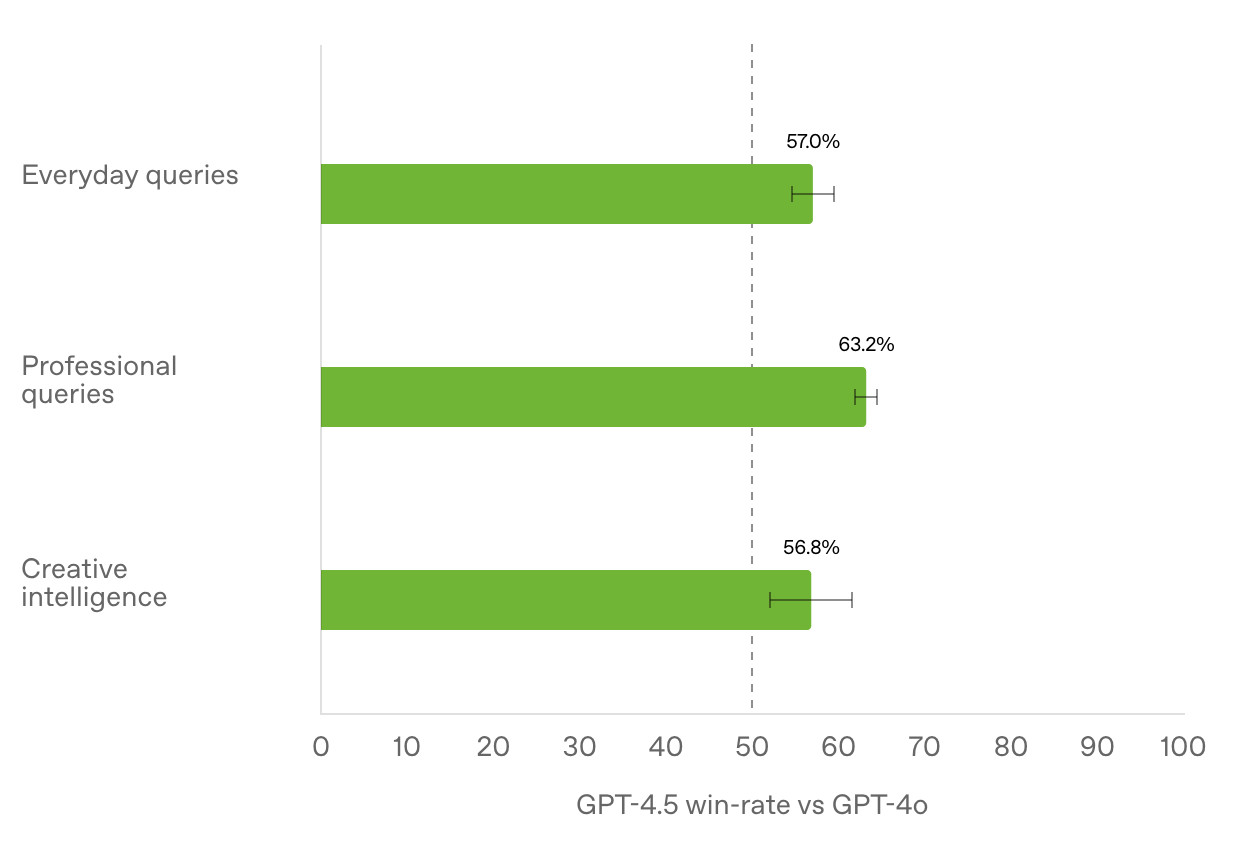
官方公布的胜率对比图表显示,GPT-4.5在不同查询类别中相对GPT-4o的胜率介于56.8%-63.2%:
在SimpleQA幻觉率测试中,该模型降至37.1%——较GPT-4o(61.8%)和o3-mini(80.3%)显著优化,但与o1(44%)相比提升有限。编码基准测试成绩与o3-mini基本持平。
OpenAI对模型前景持审慎态度:
鉴于GPT-4.5作为超大规模计算密集型模型,其使用成本高于GPT-4o且不具备替代性,我们正在评估是否长期维持其API服务,以平衡现有能力支持与未来模型研发。
Andrej Karpathy指出相较GPT-4训练成本增加10倍的情况下改进幅度有限:
每个 0.5 版本号大致对应 10 倍预训练算力。回顾历史:GPT-1 几乎无法生成连贯文本,GPT-2 是个混乱的玩具,GPT-2.5 被直接跳过升级到 GPT-3(后者更加有趣),GPT-3.5 跨越了产品化门槛并引发 OpenAI 的"ChatGPT 时刻",而 GPT-4 虽感知更好但提升微妙。记得在黑客马拉松中,我们曾费力寻找能体现 GPT-4 明显优于 3.5 的具体提示案例——这类案例确实存在,但明确且具说服力的"完胜"示例却难以寻觅。这种提升如同潮水托起所有船只:措辞更富创意,提示的细微理解更精准,类比更合理,幽默感更佳,冷门领域知识更完善,幻觉频率略降。整体氛围提升约 20%。带着这种预期,我测试了已接触数日的 GPT-4.5(其预训练算力是 GPT-4 的 10 倍),却仿佛重演两年前场景:所有方面都有提升,但这种进步依旧难以具体量化。尽管如此,作为通过简单预训练更大模型就能"免费"获得能力提升的又一次定性测量,这仍令人极度兴奋。
需特别说明,GPT-4.5 仅通过预训练、监督微调和 RLHF 训练,尚未成为推理型模型。因此在需要关键推理的领域(数学、编程等),本次发布并未推进模型能力。这些领域仍需基于旧版基础模型(如 GPT-4 级别)进行强化学习训练来培养思维能力。当前该领域标杆仍是完整版 o1 系统。预计 OpenAI 将在 GPT-4.5 基础上继续强化学习训练以提升推理能力。
但我们确实预期非重度推理任务会有改进——这些任务更多涉及情商(而非智商),受限于世界知识、创造力、类比能力、综合理解力和幽默感等维度。这正是我在氛围测试中最关注的部分。
关于OpenAI GPT-4.5 System Card的部分摘录
我们正式发布OpenAI GPT-4.5的研究预览版,这是目前规模最大、知识储备最丰富的模型。该模型基于GPT-4o构建,通过扩展预训练规模,其设计比专注STEM领域推理的模型更具通用性。==我们采用新型监督技术结合监督微调(SFT)和基于人类反馈的强化学习(RLHF)等传统方法进行训练,这些方法与GPT-4o的训练策略相似==。部署前进行的全面安全评估表明,相较于现有模型,其安全风险未见显著增加。
初期测试显示,与GPT-4.5的交互更加自然。凭借更广泛的知识库、更强的用户意图对齐能力以及提升的情感智能,该模型在写作、编程和解决实际问题等任务中表现优异,且==产生幻觉的概率更低==。我们以研究预览版形式发布GPT-4.5,旨在深入理解其优势与局限。我们持续探索其能力边界,并期待用户开发出超乎预期的应用场景。
本系统说明书遵循OpenAI安全流程和准备框架,详细阐述了GPT-4.5的构建训练过程、能力评估体系与安全强化措施。
2 模型数据与训练
推进无监督学习前沿
我们通过扩展两大范式提升AI能力:==无监督学习与思维链推理==。扩展思维链推理( Scaling chain-of-thought reasoning)使模型具备"先思考后应答"的能力,可处理复杂STEM问题或逻辑难题。而无监督学习范式的扩展( scaling unsupervised learning)则能提高世界模型的准确性,降低幻觉率,增强联想思维能力。==GPT-4.5正是我们在无监督学习范式扩展道路上的最新里程碑==。
新型对齐技术促进人机协作随着模型规模扩大及其解决问题的广度复杂度提升,增强模型对人类需求与意图的理解变得至关重要。针对GPT-4.5,我们开发了新型可扩展对齐技术,==可利用小模型衍生的数据训练更强大的模型==。这些技术显著提升了GPT-4.5的可控性、细微语义理解能力和自然对话水平。内部测试反馈显示,GPT-4.5具有温润、直觉化的交互特质。面对情感类诉求时,能精准把握提供建议、化解负面情绪或单纯倾听的时机。
GPT-4.5还展现出更强大的审美直觉和创造力,在辅助用户进行创意写作与设计方面表现卓越。该模型的预训练和后训练采用了多样化数据集,包括公开数据、来自数据合作伙伴的专有数据,以及内部开发的自定义数据集,这些数据共同铸就了模型强大的对话能力与世界观认知。
我们的数据处理管线包含严格的质量过滤机制以控制风险。通过先进的数据过滤流程,最大限度减少训练过程中对个人信息的处理。同时结合Moderation API和安全分类器的双重防护,有效阻止有害内容的使用。