

ICLR2025 oral
摘要
虽然大语言模型 (LLM) 在生成任务中表现出色,但如果未应用进一步的representation finetuning,其仅解码器架构通常会限制它们作为嵌入模型的潜力。这是否与它们作为通用模型的声明相矛盾?为了回答这个问题,我们仔细研究了混合专家模型 (MoE) LLM。我们的研究表明,MoE LLM 中的专家路由器可以作为开箱即用的嵌入模型,在各种以嵌入为中心的任务中表现出良好的性能,而无需任何微调。此外,我们广泛的分析表明,MoE 路由权重 (RW) 与 LLM 的隐藏状态 (HS) 互补,而隐藏状态是一种广泛使用的嵌入。与 HS 相比,我们发现 RW 对提示词的选择更具鲁棒性,并且侧重于高级语义。受此分析的启发,我们提出了 [MoEE],它结合了 RW 和 HS,与单独使用两者相比,实现了更好的性能。我们对它们的组合和提示策略的探索揭示了一些新的见解,例如,RW 和 HS 相似度的加权和优于它们连接后的相似度。我们的实验在来自大规模文本嵌入基准 (MTEB) 的 6 个嵌入任务和 20 个数据集上进行。结果表明,[MoEE] 在不进行进一步微调的情况下,为基于 LLM 的嵌入带来了显着改进。
介绍
混合专家模型 (MoE) 作为一种多功能的架构,最初在 1990 年代开发,可以通过将任务分配给专门的专家来提高模型泛化能力并降低推理成本。 随着时间的推移,MoE 在自然语言处理和计算机视觉等领域越来越突出,尤其是在大语言模型 (LLM) 的开发中越来越受到关注。 MoE 的一个关键组成部分是动态路由器,它可以智能地将每个输入分配给最相关的专家。 这使得 MoE 能够根据每个输入的独特特征来定制其计算,从而优化效率和准确性。 然而,最近的大多数 LLM 和 MoE LLM 都是建立在仅解码器架构之上的,该架构经过训练用于自回归的下一个 Token 预测。 虽然在生成任务方面表现出色,但它们的最终或中间隐藏状态 (HS) 并非旨在捕获输入 Token 的关键特征并涵盖其所有信息。 相反,HS 可能会偏向于下一个输出 Token 的信息。 尽管提取最后一个 Token 的隐藏状态 (HS) 作为嵌入是一种常见的经验做法,但它甚至可能比专门为嵌入任务训练的较小编码器模型表现得更差。 以分类为例,语义略有不同的输入可能与相同的标签相关联,因此旨在预测标签的最后一个 HS 可能会忽略输入差异。 尽管专门针对表征学习的额外微调可以大大增强 LLM 作为嵌入模型的能力,但考虑到嵌入任务的广泛应用,这提出了预训练的 LLM 是否可以被称为通用人工智能的问题。
我们能否直接从大语言模型中提取高质量的嵌入,而无需额外的训练?在本文中,当我们研究 MoE 大语言模型时,我们发现这个问题的答案是肯定的。我们的主要发现是,MoE 中的路由器可以作为现成的嵌入模型,并且生成的路由权重 (RW) 为广泛使用的 HS 作为嵌入提供补充信息。 与 HS 专注于来自输入的最终预测结果相比,RW 反映了 MoE 在大语言模型的每一层上对输入进行中间推理选择。因此,作为路由机制的副产品,RW 完善了 HS 中缺失的输入信息。作为证据,我们对 RW 和 HS 的比较分析表明,它们揭示了不同的输入聚类结构和主题,而 RW 捕获了输入的基础主题和语义结构。此外,我们对 HS 或 RW 失败的嵌入任务实例进行了错误分析。如图2所示,一个嵌入成功而另一个嵌入失败的案例比例超过 $50\%$,表明如果结合 RW 和 HS,则有很大的改进空间。受此分析的启发,我们首次尝试结合 RW 和 MoE 大语言模型中广泛使用的 HS,从而产生一种无需训练、上下文丰富且整体的嵌入,称为 “MoE Embedding ([MoEE])",它在嵌入任务中表现出色。具体来说,我们尝试了各种组合策略,发现虽然简单地连接 RW 和 HS(表示为 MoEE)可以改进它们中的任何一个,但分别在 RW 和 HS 上计算的两个相似度的加权和(表示为 MoEE)通常可以获得最佳结果。相似度的加权和避免了两种不同类型嵌入之间的融合和对齐,同时允许我们平衡依赖于输出的信息与输入敏感的特征,从而优化各种任务的性能。

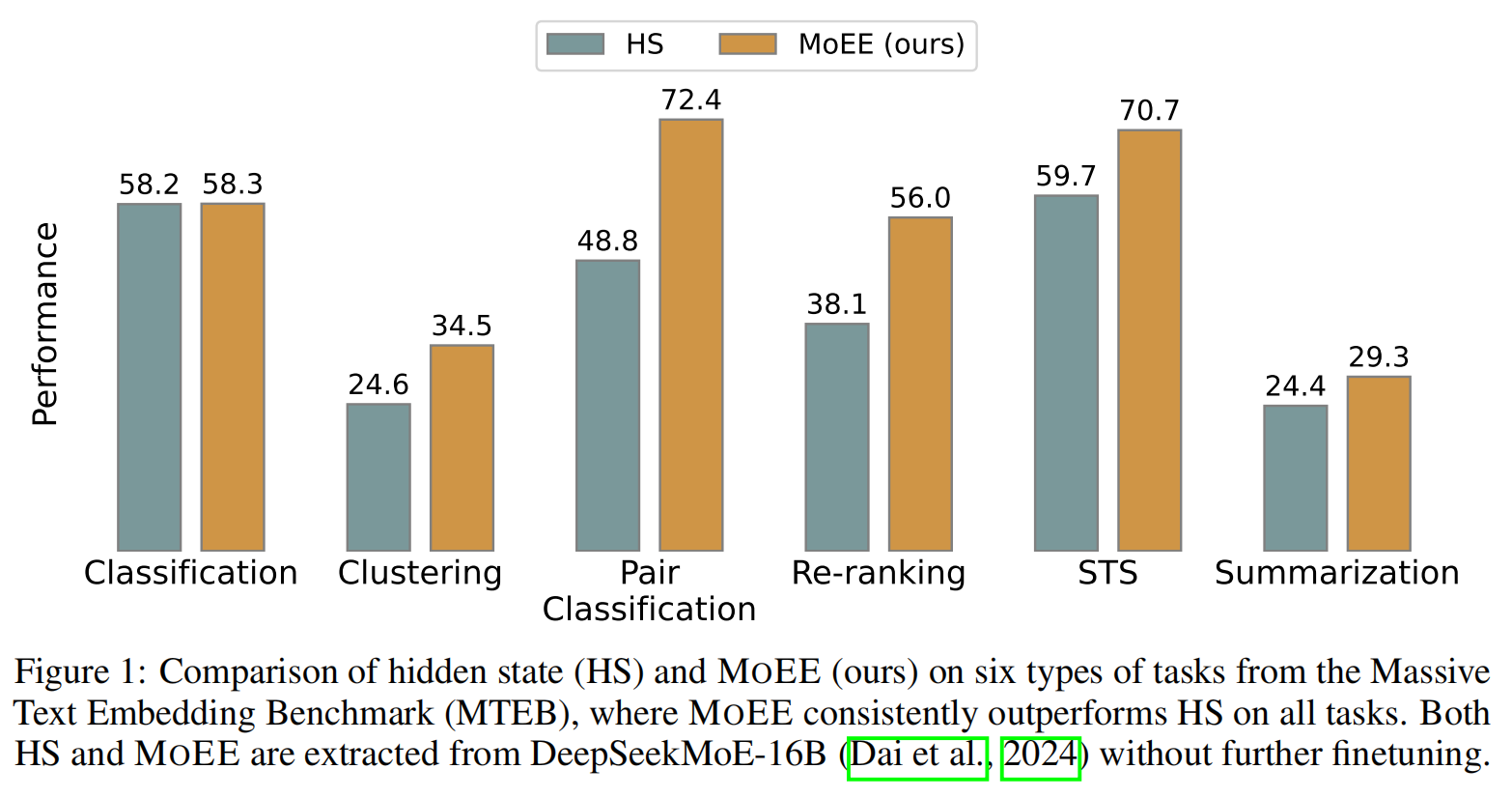
我们对 [MoEE] 进行了扩展评估,并将其与 Massive Text Embedding Benchmark (MTEB) 上的基准线进行了比较。MTEB 涵盖了广泛的任务,旨在测试嵌入的质量。[MoEE] 始终优于仅从 HS 或 MoE 的 RW (Routing Weights,路由权重) 导出的嵌入,如图1所示。 特别是,MoEE 在需要深入理解输入的任务中取得了显著的提升,例如语义文本相似度、分类和聚类。 除非特别说明,本文中的结果均在 DeepSeekMoE-16B 上进行。
混合专家嵌入 ([MoEE])
我们的方法利用预训练的、仅解码器的大语言模型(LLM)配备的 MoE 模块的动态路由机制,生成富含信息且对输入敏感的嵌入表示。本节将详细介绍我们方法论中的关键步骤,包括嵌入提取、跨层专家路由以及嵌入的最终整合。所有这些步骤均通过预训练模型实现,无需任何额外的训练。
MoE 路由权重 (RW) 作为嵌入
我们的方法利用了嵌入在预训练的、仅解码器的大语言模型中的 MoE 模型的动态路由能力。这些 MoE 模块跨多个层运行,使模型能够专门处理不同深度的输入的各个方面。在第 $l$ 层,每个 MoE 模型由 $N^{(l)}$ 个专家组成,表示为 $E_i^{(l)}$,其中 $i = 1, 2, \dots, N^{(l)}$。每个专家都是一个专门的子网络,专注于该层特定输入特征,从而可以更精细地理解输入通过网络时的信息。然而,这种架构的真正优势在于动态路由机制,该机制由门控函数 $\mathbf{g}^{(l)}(\mathbf{H}^{(l)}) \in \mathbb{R}^{N^{(l)}}$ 控制,该函数确定哪些专家将根据输入在每一层被激活。
$$ \sum_{i=1}^{N^{(l)}} g^{(l)}_i(\mathbf{H}^{(l)}) E_i^{(l)}(\mathbf{H}^{(l)}) $$$$ g^{(l)}_i(\mathbf{H}^{(l)}) = \frac{\exp(z^{(l)}_i(\mathbf{H}^{(l)}))}{\sum_{j=1}^{N^{(l)}} \exp(z^{(l)}_j(\mathbf{H}^{(l)}) )} $$$$ \mathbf{e}_{\text{RW}} = [\mathbf{g}^{(1)}(\mathbf{H}^{(1)}); \mathbf{g}^{(2)}(\mathbf{H}^{(2)}); \dots; \mathbf{g}^{(L)}(\mathbf{H}^{(L)})] \in \mathbb{R}^{\sum_{l=1}^{L} N^{(l)}} $$这个嵌入捕捉了输入如何通过所有层中不同的专家进行路由,从而提供了模型与输入交互的整体视图。重要的是,它反映了模型决策过程的完整深度,使其成为下游任务的强大表示,在这些任务中,输入的多样化语义和结构特征至关重要。
路由权重与隐藏状态的比较与互补分析

在本节中,我们将研究从 MoE 模型生成的路由权重 (RW) 嵌入和隐藏状态 (HS) 嵌入如何捕获输入数据的不同方面。理解这些嵌入所扮演的不同角色对于确定它们如何相互补充至关重要。虽然来自预训练大语言模型 (LLM) 的 HS 嵌入提供了对句子的广泛且上下文驱动的表示,但它们可能会忽略 RW 嵌入可以通过 MoE 的动态路由捕获的细微的、token 特定的信息。这种区别表明 RW 和 HS 可能在不同的上下文中表现出色,并可能编码互补信息。为了探索这一点,我们首先使用 k-means 聚类分析它们的聚类行为,并执行相关性分析以量化它们各自聚类结构之间的差异。然后,我们利用 BERTopic 框架来检查与每个聚类相关联的主题,从而深入了解嵌入捕获主题内容的能力。最后,我们评估它们在识别语义相似的文本对方面的性能,进一步证实它们的互补性质。
RW 和 HS 嵌入表现出不同的聚类行为,并编码不同的主题。我们的分析表明,RW 和 HS 嵌入的聚类结果存在显著差异。如表1所示,聚类指标显示中等程度的重叠(AMI 和 NMI 均为 0.29),但 Jaccard 相似度较低,仅为 0.06,且簇之间的精确匹配[^1]仅为 45.54%,这突显了每种方法构建数据的独特方式。这种聚类行为的差异进一步体现在嵌入所捕获的主题中。如图3所示,词云显示 RW 和 HS 嵌入的簇侧重于不同的主题,突出了这两种方法如何捕获输入数据的不同方面。
RW 和 HS 嵌入的互补性。 先前的分析表明,RW 和 HS 嵌入能够捕获输入数据的不同侧面。为了验证这一假设并量化它们的互补性,我们需要考察这两种嵌入之间的关联。我们通过使用 STS12 数据集进行 Spearman 相关性分析来实现这一点。该数据集包含 6,216 个句子对。对于每一对句子,我们从 RW 和 HS 生成嵌入,并计算句子之间的相似度,以评估每种嵌入捕获语义关系的能力。为了确保观察到的任何差异并非由提示词变化引起,我们采用了九个不同的提示词(如表2所示)。如图4所示,值得注意的是,在所有比较中,RW 和 HS 嵌入之间的相关性最低,平均值为 0.51。这种低相关性表明 RW 和 HS 捕获了很大程度上不相关的数据方面,从而印证了它们的互补性。误差分析(图2)和实验结果提供了进一步的证据来支持这种互补性。
提出的 MoE Embedding ([MoEE])
在对路由权重 (RW) 和隐藏状态 (HS) Embedding 进行分析的基础上,我们提出了我们的方法 [MoEE],它结合了 RW 和 HS,形成一种更全面的 Embedding 表示。 我们介绍了以下两种组合方法。
$$ \mathbf{e}_{\text{final}} = [\mathbf{e}_{\text{HS}}; \mathbf{e}_{\text{RW}}] \in \mathbb{R}^{d_{\text{HS}} + d_{\text{RW}}} $$其中 $d_{\text{HS}}$ 是隐藏状态 Embedding 的维度,而 $d_{\text{RW}}$ 是路由权重 Embedding 的维度。 这种方法保留了每个组件捕获的不同信息,同时允许下游任务利用组合表示。
$$ \text{sim}_{\text{HS}} = \text{cosine\_similarity}(\mathbf{e}_{\text{HS}}(s_1), \mathbf{e}_{\text{HS}}(s_2)),\\ \text{sim}_{\text{RW}} = \text{cosine\_similarity}(\mathbf{e}_{\text{RW}}(s_1), \mathbf{e}_{\text{RW}}(s_2)) $$$$ \text{sim}_{\text{final}} = \text{sim}_{\text{HS}} + \alpha \cdot \text{sim}_{\text{RW}}, $$其中 $\alpha$ 用作超参数,以控制 RW 的贡献。最后,我们计算预测的相似度分数 $\text{sim}_{\text{final}}$ 与真实相似度之间的等级相关性(例如,Spearman 等级相关性)。这个框架可以一致地应用于其他任务,并根据任务的特定需求调整加权求和的方式。
评估设置
我们在 MTEB 的一个子集任务上评估我们的方法,这些任务代表了广泛的自然语言处理挑战。这些任务涵盖了句子嵌入的典型下游应用,包括分类、聚类、配对分类、重排序、检索、语义文本相似度 (STS) 和摘要。为了确保一致和公平的比较,我们遵循 MTEB 提供的评估框架,并使用来自 @muennighoff2022mteb 的特定于任务的指标:分类的准确率、聚类的 V-Measure、配对分类的平均精度、重排序的平均精度均值、检索的 nDCG 以及 STS 和摘要的 Spearman 相关性。我们的实验使用了三个 MoE 模型:
- DeepSeekMoE-16B:28 层,每层 64 个专家。
- Qwen1.5-MoE-A2.7B:24 层,每层包含 60 个专家。
- OLMoE-1B-7B:16 层,每层 64 个专家。所有模型都使用逐 token 路由,但 [MoEE] 使用最后一个 token 的路由权重,该权重始终优于所有 token 的平均值。支持此选择的消融研究在第 4.3{reference-type=“ref” reference=“sec:abs”} 节中提供。 基线 我们的目标是从MoE 大语言模型中提取高级嵌入,通过结合隐藏状态(HS)和路由权重(RW),无需进一步训练。为了证明[MoEE]的有效性,我们将其与单独的RW和HS进行比较,以及与几种需要训练的自监督和监督方法进行比较。我们还评估了不同提示词策略下的性能,特别是比较了没有提示词和使用PromptEOL的方法。
主要结果
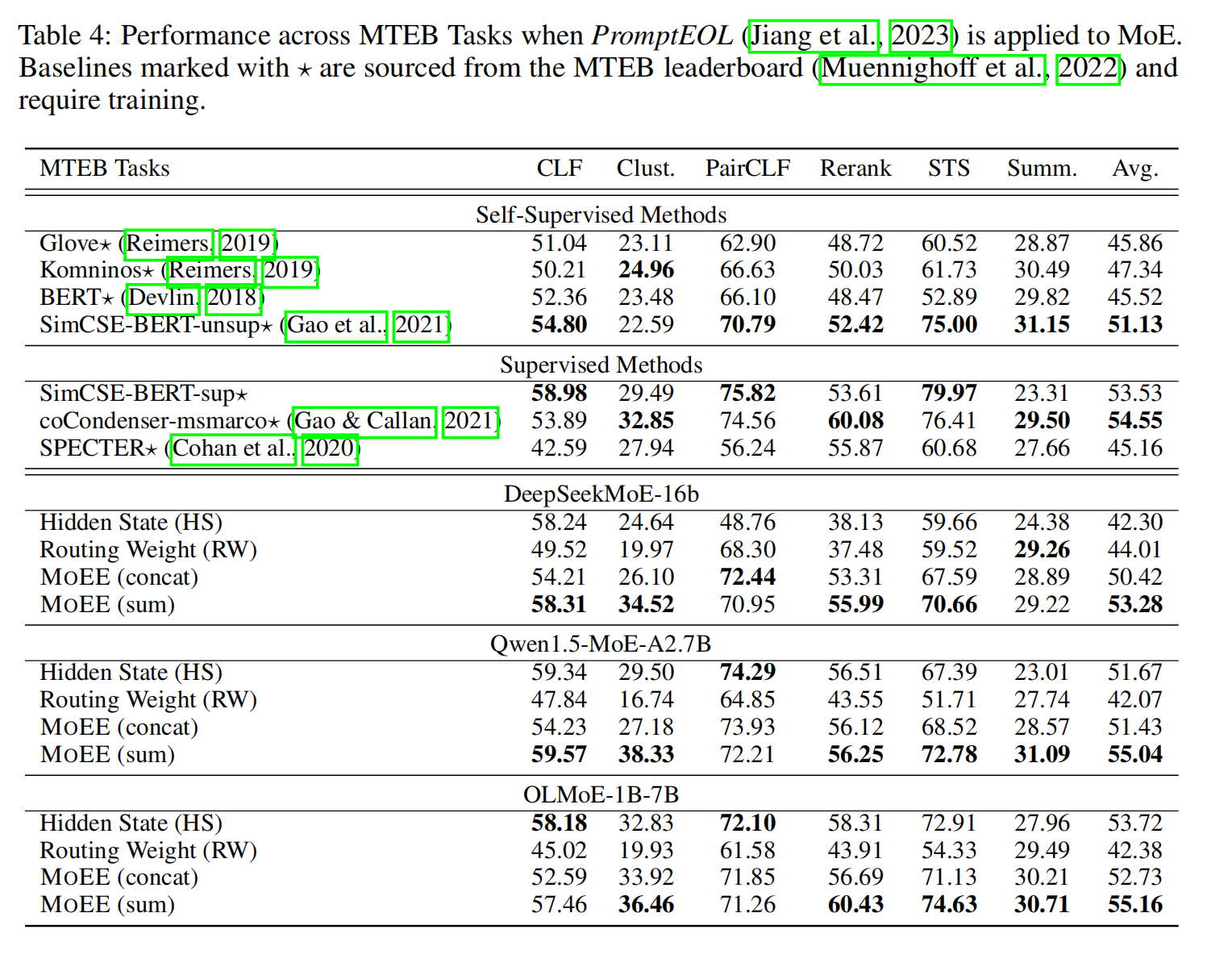
我们的方法在各种 MTEB 任务中表现出持续的性能提升,如表3和 4所示。[MoEE] 将路由权重与隐藏状态相结合,在大多数情况下始终优于独立的两种方法(RW 和 HS),突显了这两个组件的互补性。对于在没有提示词的情况下评估的任务,结果表明 MoEE 在各种模型中实现了最高的平均性能,在分类、重排序和 STS 等任务中取得了显著的改进。具体来说,DeepSeekMoE 从 35.36 (HS) 显著提升至 43.30 (MoEE),提升幅度达 22.45%。这种模式在 Qwen1.5-MoE 和 OLMoE 中也成立,其中 MoEE 相对于两种单独的方法都取得了持续的收益。当引入 PromptEOL 时(表4),我们观察到更大的性能提升,DeepSeekMoE 提升了 25.96%。在所有模型中,MoEE 再次取得了最佳结果,OLMoE 实现了最高的总体平均分 55.16,Qwen1.5-MoE 紧随其后,为 55.04。虽然 [MoEE] 在分类任务中相对于 HS 表现出略微的提升,但这是预期的,因为最后一层 HS 更符合输出特定的特征,这更有利于分类。
尽管 [MoEE] 最初的表现不如无提示的自监督和监督学习方法,但引入 PromptEOL 后,情况发生了显著改变。如表4所示,[MoEE] 已经超越了 SimCSE 和 coCondenser 等监督学习方法,并且在无需额外训练的情况下实现了更卓越的性能。 这充分体现了它的有效性和效率。
消融研究
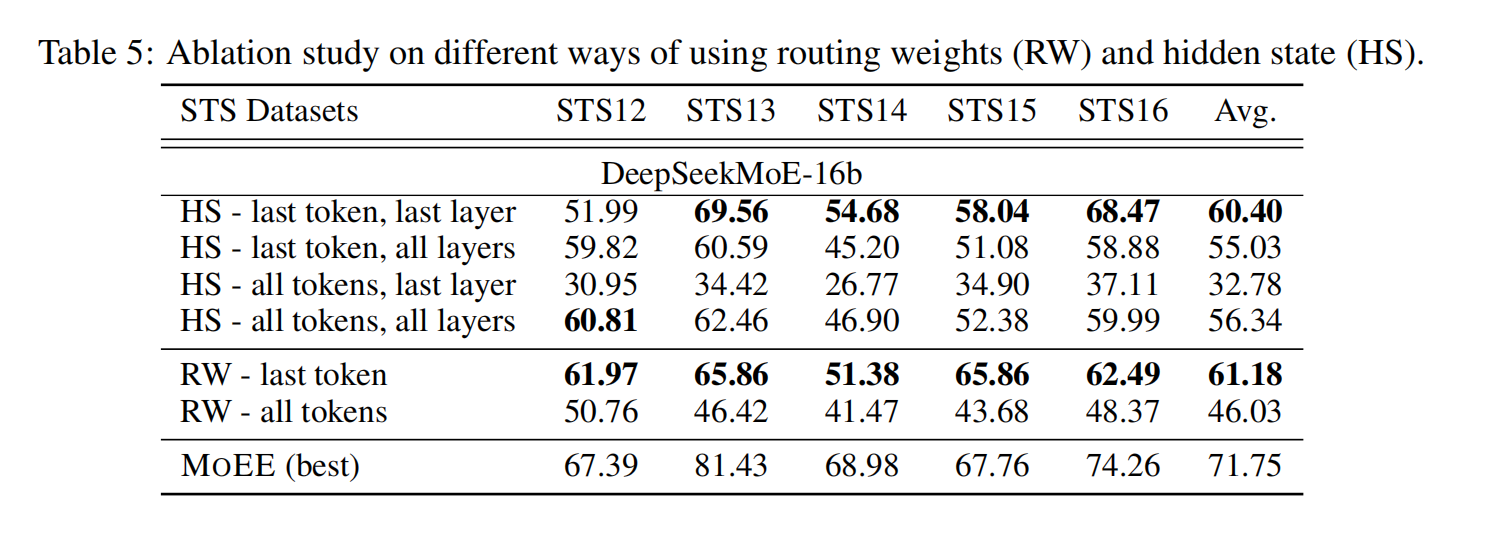
RW 整合了所有层的路由决策,捕获了多个深度的信息。相比之下,仅来自最后一层的 HS 可能会错过重要的中间细节。因此,我们评估了使用来自所有层的隐藏状态 (HS - last token, all layers),看看它是否可以与 RW 相匹配,RW 自然地利用了多层信息。我们还评估了仅使用最后一个 Token 与在所有 Token 上进行平均的影响。虽然最后一个 Token 通常会浓缩关键的序列信息,但在所有 Token 上进行平均池化可能会通过纳入每个 Token 的贡献来提供更广泛的视角。因此,我们将 HS - last token 与 HS - all tokens 进行比较,并将 RW - last token 与 RW - all tokens 进行比较。对于多层或多 Token 的情况,应用平均池化。
我们的结果表明,无论是来自 HS 还是 RW,专注于最后一个 Token 始终能提供最佳性能。这表明最后一个 Token 捕获了最关键的语义信息,而跨 Token 或层的池化会引入噪声。值得注意的是,RW 的表现优于 HS,这突显了 RW 在捕获细微且动态的信息方面的卓越能力,而 HS 无法单独复制这些信息。
使用不同提示词的 RW 和 HS 的稳定性比较
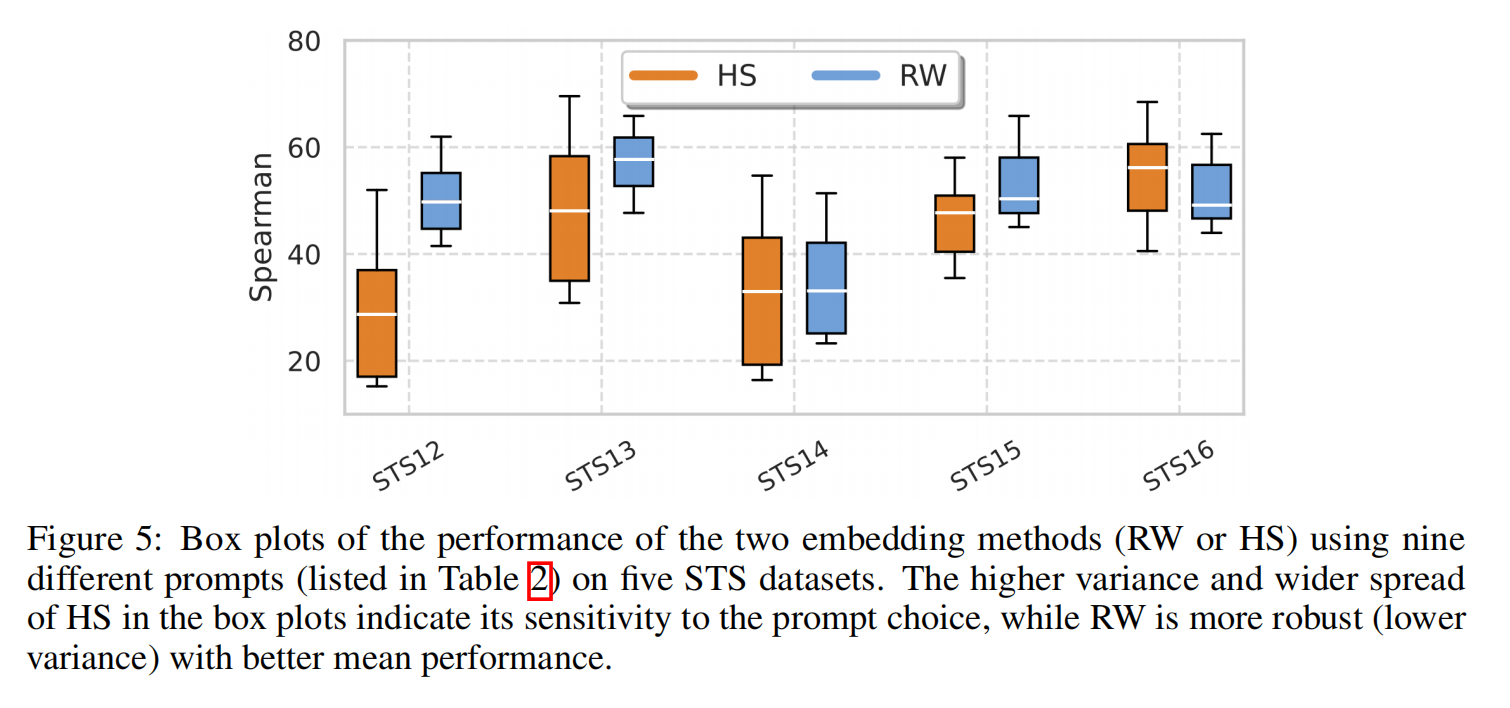
提示词通常用于提升嵌入模型在各种下游任务中的性能,如PromptEOL的改进结果所示(表3)与没有提示词的情况相比(表4)。然而,这些提示词的有效性可能有所不同,一个方法的鲁棒性取决于其处理这些变化的能力。为了评估RW和HS对提示词的敏感性,我们使用表2中列出的9个不同的提示词,测量它们在STS12-16数据集上的Spearman相关系数。然后,我们计算每个数据集的这些得分的平均值和方差,以衡量在不同提示词条件下性能的波动情况,以及这些方法在面对提示词变化时是否保持稳定。图5突出了两种方法的性能方差。HS表现出明显更高的方差,尤其是在STS12、STS13和STS14等数据集中,表明其性能高度依赖于所使用的特定提示词。这表明 HS对提示词的构建方式更加敏感,导致结果不一致,从而可能影响其在更广泛应用中的可靠性。
相比之下,RW 表现出更大的稳定性,在所有数据集中都具有始终较低的方差和更窄的箱线图,表明其对提示词选择具有更强的鲁棒性。在图4中,RW 在不同提示词之间也实现了更高的平均相关性 0.63,突显了其在不同提示词之间保持稳定性能的能力。这使得 [MoEE] 成为在预期提示词存在可变性的任务中,一个更可靠的选择。