摘要
我们提出了一种==蒸馏缩放定律,该定律基于计算预算及其在学生模型和教师模型之间的分配,来估计蒸馏模型的性能==。 我们的发现降低了大规模使用蒸馏的风险;现在可以进行教师模型和学生模型的计算分配,以最大限度地提高学生模型的性能。 我们提供了计算最优的蒸馏方案,适用于以下两种情况:1) 教师模型已存在;2) 教师模型需要训练。 如果需要蒸馏多个学生模型,或者已经存在教师模型,那么在计算量达到一定水平之前,蒸馏的表现优于监督预训练,而该计算水平会随着学生模型大小的增长而可预测地增长。 如果只需要蒸馏一个学生模型,并且教师模型也需要训练,那么应该改为进行监督学习。 此外,我们还提供了对大规模蒸馏研究的见解,这些见解加深了我们对蒸馏的理解,并为实验设计提供了信息。

介绍
对缩放定律的研究表明,如果先前训练的[lms]遵循计算最优的训练范式,它们可以表现得更加出色。这种范式旨在确定在给定的计算预算下,能够产生最佳性能模型的模型大小和训练 Token 数量。 许多后续研究都遵循了计算最优训练方法。 计算最优模型的大小随着计算量的增长而增长,这导致推理成本增加,从而使得它们更难被有效利用。 实际上,这意味着计算最优模型速度慢、服务成本高昂、消耗更多电池电量、提高了学术研究的门槛,并且会产生显著的碳排放。 随着推理量高达每天数十亿 Token,lm的推理成本通常远高于其预训练成本,并且在测试时计算量扩展的时代,这一成本还将进一步增加。
不可持续的推理成本催生了一种替代的训练范式,即过拟合训练,在这种范式中,所使用的训练数据量远超计算最优状态下的数据量,从而能够训练出小型且性能强大的模型。当以模型的整个生命周期而非仅仅预训练成本来衡量计算量时,过拟合训练的模型能更好地满足计算最优性。由于监督学习的扩展法则遵循模型大小和训练数据的幂律关系,因此性能的边际效益递减出现得比计算最优情况下要早得多。为了达到合理的性能水平,这些模型需要在数万亿的 Token 上进行训练,这既昂贵又耗时。我们力求找到一种模型,它能在更低的训练成本下达到小型过拟合训练模型的性能水平。一个常用的备选方案是知识蒸馏,即由一个性能强大的教师 [lm]为一个较小的学生 [lm]模型生成训练目标。当知识蒸馏被用于 [lm]预训练时,我们称之为知识蒸馏预训练。关于为什么知识蒸馏有效,存在多种解释,从暗知识迁移(即信息蕴含在不正确类别的概率比率中),到作为一种正则化手段,或是降低学习过程中的噪声等等。尽管对于知识蒸馏有效的原因尚未达成共识,但在 Gemma 和 Gemini、Minitron 和 AFM 系列的 [lms]模型中,知识蒸馏预训练在预训练损失和下游评估方面,都产生了比监督预训练更强大的模型。然而,与此同时,@DBLP:conf/icml/Liu0ILTFXCSKLC24 报告称,知识蒸馏产生的模型比监督预训练产生的模型能力更弱。
鉴于大量计算资源正被用于 [lms]的蒸馏预训练,至关重要的是要了解如何合理分配这些资源,以尽可能地训练出性能最佳的模型。同时,我们也需要了解,在相同资源条件下,蒸馏预训练相比于监督预训练是否具有优势。为了填补这一知识空白,我们对蒸馏方法进行了广泛的对照研究,学生模型和教师模型的参数规模从 1.43 亿到 126 亿不等,训练数据量从数十亿 Token 扩展到最多 5120 亿 Token。通过这些实验,我们得出了蒸馏缩放定律,该定律将学生模型的性能估计为关于资源的函数(包括教师模型、学生模型的大小以及用于蒸馏的数据量)。该定律解决了在特定资源约束下,蒸馏方法在生成具有期望能力的模型时,是否有效的问题。我们的研究发现:
- 大小为 $N_S$ 的学生模型,在从大小为 $N_T$ 的教师模型蒸馏得到的 $D_S$ 个 Token 上进行蒸馏时,其交叉熵可以使用我们的蒸馏缩放定律进行预测。
- 教师模型的大小 $N_T$ 和教师模型训练所用的 Token 数量 $D_T$,仅通过它们所决定的教师模型交叉熵 $L_T=L_T(N_T,D_T)$ 来影响学生模型的交叉熵。
- 教师交叉熵对学生损失的影响遵循幂律,该幂律根据学生和教师的相对学习能力在两种行为之间转换,反映了知识蒸馏中的一种称为能力差距的现象,即更强的教师模型反而会产生更差的学生模型。我们的参数化解决了关于能力差距的悬而未决的问题,表明它是教师模型和学生模型之间学习能力(包括假设空间和优化能力)的差距,而不仅仅是它们相对大小的差距,后者只是一种特殊情况。我们的结果表明,当两个学习过程都获得足够的数据或计算资源时,知识蒸馏无法产生比监督学习更低的模型的交叉熵。然而,如果以下两个条件都成立,则知识蒸馏比监督学习更有效:
- 用于学生的总计算量或 Token 数量不大于我们的缩放定律给出的取决于学生模型规模的阈值。
- 教师模型已经存在,或者要训练的教师模型除了单一知识蒸馏之外还有其他用途。
我们希望我们提供的定律和分析将指导社区生产出更强大的模型,并降低推理成本和生命周期计算成本。
背景
在模型扩展时,预测模型性能至关重要,因为它使我们能够理解:i) 增加可用计算资源 ($C$) 的价值;以及 ii) 如何分配这些计算资源,通常是在模型参数 ($N$) 和数据 ($D$) 之间,以实现具有所需属性的模型。这些属性可能包括充分预测数据分布(以交叉熵 ($L$) 衡量),或者在感兴趣的下游任务上达到一定水平的性能。幸运的是,交叉熵 是可预测的,大量的经验和理论证据表明,$L$ 遵循参数 $N$ 和数据 $D$(以 Token 衡量)的幂律:
$$ \begin{aligned}
\underbrace{L(N,D)}\text{模型交叉熵}= \underbrace{E}{\text{不可约误差}}
- \underbrace{\left(\frac{A}{N^\alpha}+\frac{B}{D^\beta}\right)^\gamma}_{\text{模型模仿数据的能力}},
\label{eq:supervised-scaling-law}
\end{aligned} $$
其中 $\{E,A,B,\alpha,\beta,amma\}$ 是特定于任务的正系数[^1],从 $n$ 个训练运行 $\{(N_i,D_i,L_i)\}_{i=1}^n$ 估计得出。
运行方案的选择至关重要;并非所有实验都能识别公式1的系数。 可以使用计算最优模型,其大小参数$N^*$和训练 Token 数量$D^*$在计算约束$C$下给出最低的交叉熵:
$$ N^*,D^*=\mathop{\mathrm{arg\,min}}_{N,D}L(N,D)\;\,\mathrm{s.t.}\;\,\mathrm{FLOPs}(N,D)=C. $$这很有吸引力,因为在总实验预算下,计算最优模型能提供最大的损失变化范围。 然而,计算最优模型具有恒定的 Token 参数比率$M\equiv D/N=\mathrm{const.}$,这减少了一个自由度。 为了可靠地识别缩放系数,@DBLP:journals/corr/abs-2203-15556 采用了两种训练策略:
- (固定模型,可变数据) 对于固定的模型族,训练 Token 的数量是可变的。
- (等计算量配置) 模型大小和训练 Token 数量都根据总计算量约束进行调整。
来自两种策略的数据随后被合并以进行拟合本文的目标是预测通过知识蒸馏产生的学生的交叉熵 $L_S$。这将帮助我们评估增加知识蒸馏计算量的价值,更重要的是,在给定的计算预算下,哪种知识蒸馏方法能够以最低的交叉熵生成特定大小的学生模型。
符号
对于一个序列 $x$,$x^{(i:j)}=(x^{(i)},x^{(i+1)},\ldots,$ $x^{(j)})$ 返回该序列的一个切片,而 $x^{(
语言建模
我们专注于 [lm]{acronym-label=“lm” acronym-form=“singular+short”} 设置,其中训练目标是对 Token 序列 $x$ 的概率进行建模,Token $x_i$ 来自词汇表 $V=\{1,2,\ldots,V\}$。设 $f:V^*\times \Theta\rightarrow \mathbb R^V$ 是一个由 $theta \in\Theta$ 参数化的下一个 Token 分类器,其输出定义了给定上下文 $x^{( $$
\hat p(x^{(i)}=a|x^{(<i)};\theta) =\sigma_a (f(x^{(<i)}\theta))
\mathcal{L}_{\text{NTP}}(x^{(i)},z^{(i)}) & =
-\sum_{a=1}^V e(x^{(i)})_a\log \sigma_a(z^{(i)}),
\label{eq:ntp-cross-entropy}
\end{aligned} $$ 其中 $e(i)$ 是第 $i$ 个基向量。通常也使用以下 Token 级别的 Z 损失来提高训练稳定性
$$ \begin{aligned}
\mathcal{L}_Z(z^{(i)})
=||\log Z(z^{(i)})||_2^2
=\left|\left|\log \sum_{a=1}^V\exp(z_a^{(i)})\right|\right|_2^2.
\end{aligned} $$
蒸馏
在蒸馏中,一个具有预测的下一个 Token 分布 $\hat p_T(x^{(i)}|x^{(
$$ \begin{aligned}
\mathcal{L}_{\text{KD}}(z_T^{(i)},z_S^{(i)}) & =
-\tau^2
\sum_{a=1}^V \sigma_a
\left(\frac{z_T^{(i)}}{\tau}\right)
\log \sigma_a\left(\frac{z_S^{(i)}}{\tau}\right),
\end{aligned} $$ 并且等价于优化教师和学生预测之间的 KL 散度 [kld]。$\tau>0$ 是蒸馏温度。将损失结合在一起,得到学生总的 Token 级别损失:
$$ \begin{aligned}
\mathcal{L}_{S} & (x^{(i)},z_T^{(i)},z_S^{(i)})=
(1-\lambda),\mathcal{L}_{\text{NTP}}(x^{(i)},z_S^{(i)})\nonumber
\ & +\lambda,\mathcal{L}{\text{KD}}(z_T^{(i)},z_S^{(i)}) +\lambda_Z,\mathcal{L}{Z}(z_S^{(i)}).
\label{eqn:kd_and_nll_full_loss}
\end{aligned} $$
蒸馏缩放定律
实验设置
所有模型均基于 @DBLP:journals/corr/abs-2407-21075,并采用解耦权重衰减 @DBLP:conf/iclr/LoshchilovH19 进行正则化。同时,为了简化实验设置,我们采用了 [mup]的简化版本,[mup]简化了缩放律的实验设置,因为它允许跨不同大小的模型迁移学习率超参数。模型参数规模从 143M 到 12.6B 不等,我们允许教师模型小于或大于学生模型。模型使用多头注意力机制 (MHA),并使用 RMSNorm 进行预归一化。所有模型均采用长度为 4096 的序列进行训练,并使用 [rope]。所有实验均使用 C4 数据集的英文子集。在所有知识蒸馏训练中,教师模型和学生模型使用不同的数据集划分。除了最大的模型外,所有 Chinchilla 最优模型都不会重复使用数据。由于我们的目标是了解教师模型在知识蒸馏过程中的作用,因此我们采用纯知识蒸馏的方式进行实验($\lambda=1$,,以避免数据本身带来的干扰,正如 @DBLP:conf/nips/StantonIKAW21 中所做的那样。我们验证了当 $\lambda=1$ 时,实验结果与最优 $\lambda^*$ 在统计上是相似的。类似地,所有实验都使用蒸馏温度($\tau=1$),因为我们发现这样可以训练出性能最佳的学生模型。
蒸馏缩放定律实验
在这里,我们讨论产生用于拟合我们的蒸馏缩放定律的数据的实验。
蒸馏缩放定律将估计学生交叉熵 $L_S$[^3],它通常取决于学生参数 $N_S$,蒸馏的 Token 数量 $D_S$,教师参数 $N_T$ 和教师训练 Token 数量 $N_T$:$L_S\approx L_S(N_S,D_S,N_T,D_T)$。正如在2{reference-type=“ref+Label” reference=“sec:background”}中讨论的,只有某些数据组合支持可靠地识别缩放定律系数。我们结合了三个实验协议来生成用于我们的蒸馏缩放定律拟合的数据。
固定 $M$ 教师/学生等计算量 (IsoFLOPs)
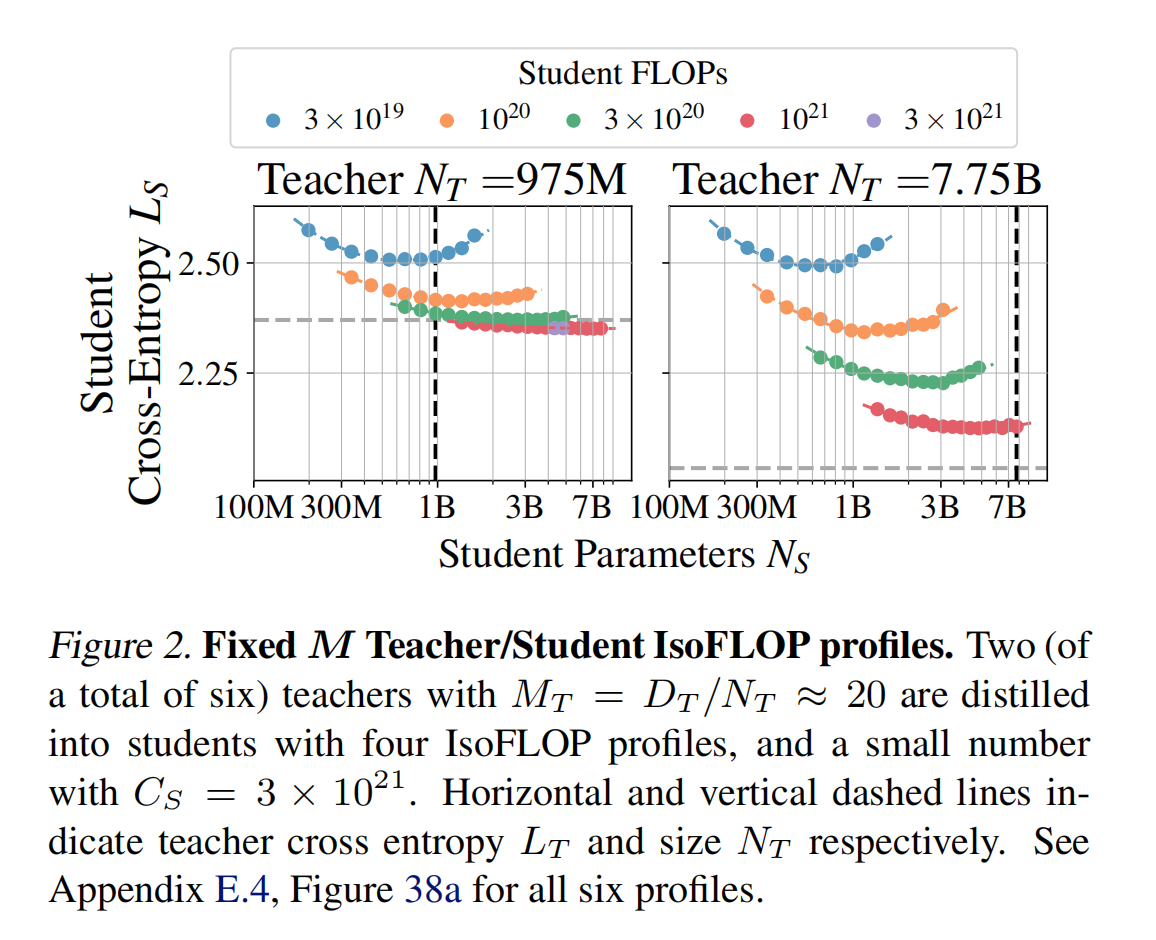
为了简化实验流程,我们做出以下假设:在一个教师 $(N_T,D_T)$信号下训练学生($N_S$, $D_S$) 也应该存在幂律行为。为了正确识别这些系数,应该执行类似于 中描述的Chinchilla protocol。但是,我们不能只为一个教师这样做,因为学生规模和 Token 对下游性能的影响可能因不同的教师而异,就像缩放定律对于不同的领域和数据集是不同的。对于蒸馏,我们预计情况就是这样,不同的教师会产生不同的学生。为了在计算预算内产生最广泛的教师范围,我们训练了六个 (Chinchilla) 最优 ($M_T=D_T/N_T\approx 20$) 教师,参数范围从 1.98 亿到 77.5 亿。[^4] 对于每个教师,我们将其提炼成具有四个等计算量 (IsoFLOP) 配置文件的学生,仅考虑标准训练成本。生成的学生交叉熵在图2中。我们注意到,在某些情况下,学生能够胜过教师,即表现出由弱到强的泛化能力 (weak-to-strong-generalization),并在中进一步研究。
IsoFLOP 教师/固定 $M$ 学生
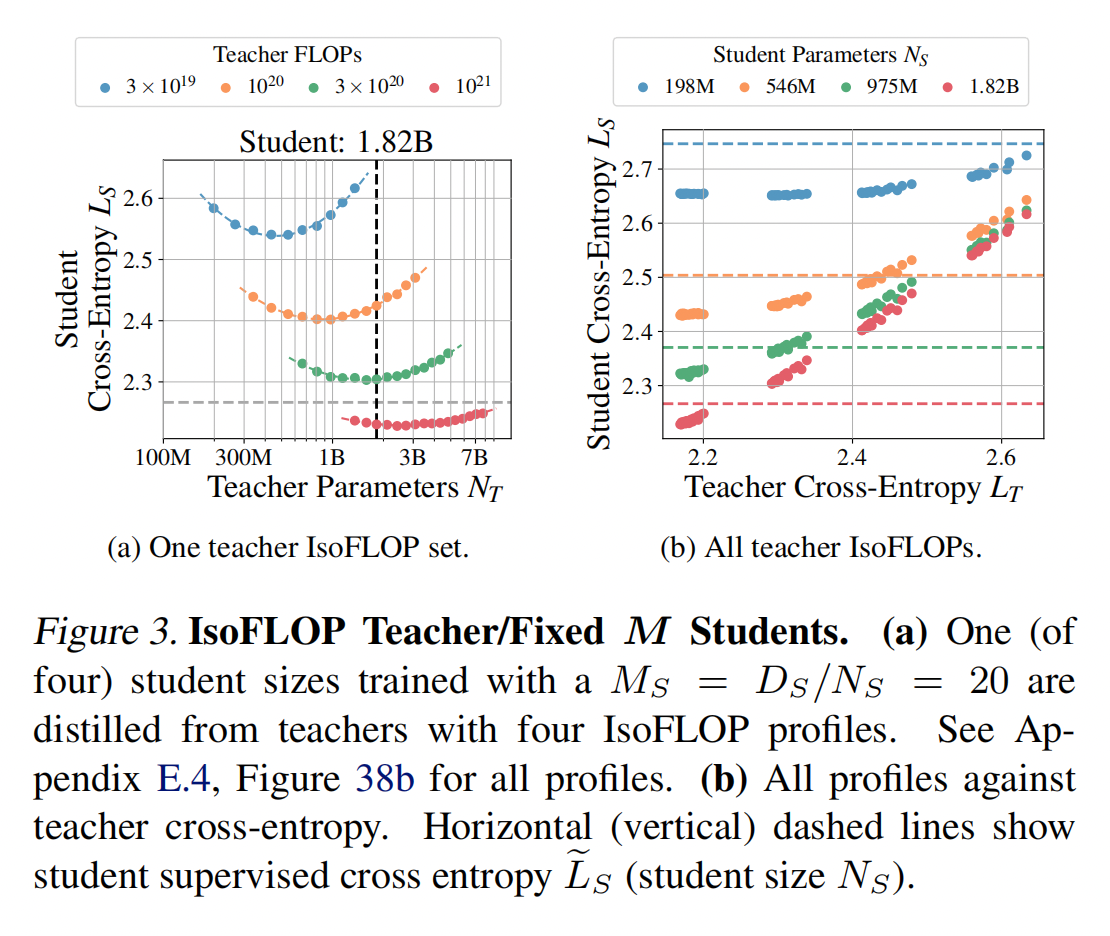
固定-$M$ 教师 IsoFLOP 学生协议不足以识别 $N_T$ 和 $D_T$ 独立地 如何影响学生交叉熵。 为了确保我们的实验能够检测到这种影响,我们进行了实验,其中学生 ($N_S$, $D_S$) 是固定的,并根据计算约束(即教师 IsoFLOP)改变 $N_T$ 和 $D_T$。 我们根据四个 IsoFLOP 配置文件,将知识提炼到四个 Chinchilla 最优 ($M_S=D_S/N_S\approx 20$) 的学生模型中,这些学生模型的参数范围从 1.98 亿到 18.2 亿。 得到的学生交叉熵在 3中。
固定 $M$ 教师/固定 $M$ 学生
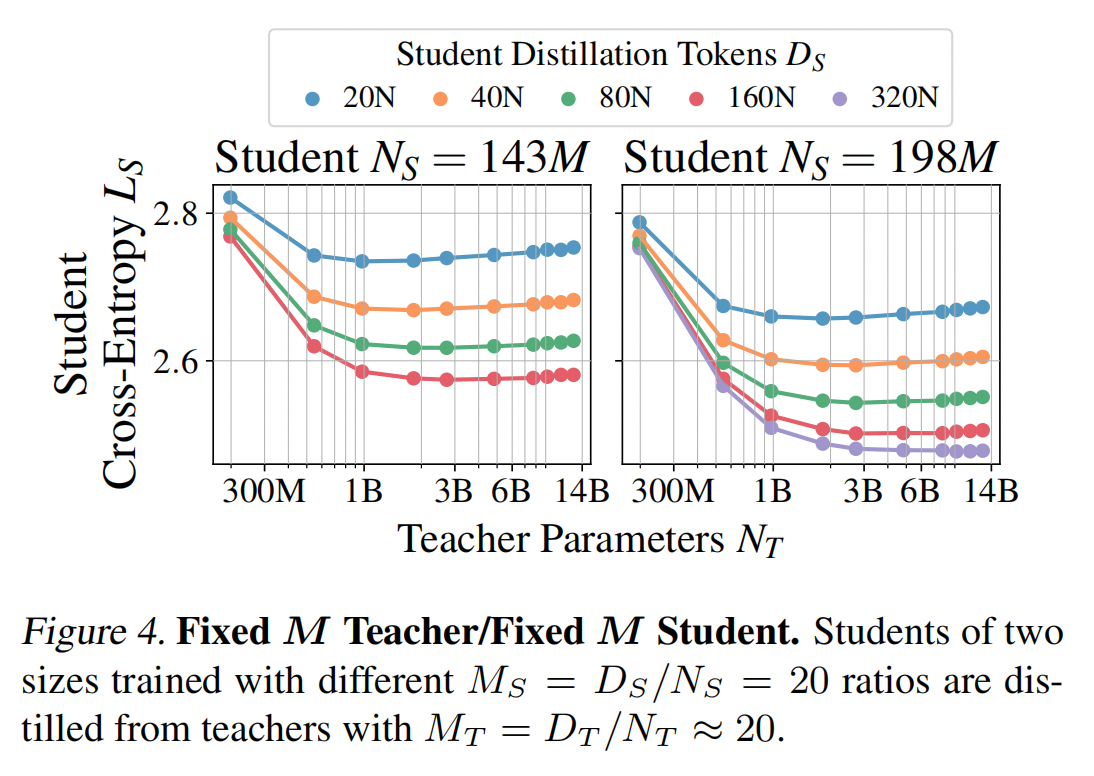
最后,虽然对于拟合我们的蒸馏缩放定律并非必要,但观察学生交叉熵如何在尽可能大的范围内变化仍然具有指导意义。 为了实现这一点,我们训练了固定-$M$ 教师和固定-$M$ 学生的组合。 其中包含十个教师,其 $M_T\approx 20$,以及五种不同尺寸的学生,每个学生至少有四个 $M_S$ 的选择。 其中两个学生的交叉熵结果如图 4所示。
容量差距
在图4中,我们观察到容量差距,即提高教师模型性能并不总是能提高学生模型性能,甚至最终会降低学生模型性能。容量差距在知识蒸馏中经常被观察到。教师模型和学生模型之间的[kld]在所有情况下都是教师模型能力的一个递增函数,这意味着随着教师模型提高自身性能,学生模型发现教师模型更难建模,最终阻止学生模型利用教师模型的提升。
蒸馏缩放定律函数形式
我们需要确定蒸馏缩放定律的函数形式。首先,我们观察到来自教师模型规模 $N_T$ 和预训练 Token 数量 $D_T$ 的贡献由教师模型的交叉熵损失 $L_T$ 概括。这可以从图1和3b中看出,其中包含 3的 IsoFLOP 教师模型/固定 $M$ 学生模型,但仅观察到作为 $L_T$ 函数的平滑依赖性。接下来,蒸馏缩放定律应反映以下属性:
- 具有无限能力的学生应该能够模拟任何教师:$\lim_{N_S,D_S\to\infty}L_S(N_S,D_S,L_T)\rightarrow L_T$。
- 随机的教师模型产生随机学生,独立于这些学生的能力如何:$\lim_{L_T\to\infty}L_S(N_S,D_S,L_T)\rightarrow L_T$。
- 存在性能差距:使教师模型过于强大最终会降低学生模型的性能。
两个幂律区域之间的过渡:i) 学生是比老师更强的学习者,以及 ii) 学生是比老师更弱的学习者,可以用一个断裂的幂律来描述。总而言之,我们提出学生交叉熵遵循 $L_T$ 中的断裂幂律,以及 $N_S$ 和 $D_S$ 中的幂律:
$$ \begin{aligned} \underbrace{L_S(N_S,D_S,L_T)}_{\text{学生交叉熵}},
=\underbrace{L_T}_{\text{老师交叉熵}} \qquad \quad\nonumber \+ \underbrace{\frac1{L_T^{c_0}}
\left(1+\left(\frac{L_T}{\widetilde{L}S d_1}\right)^{1/{f_1}}\right)^{-c_1f_1} \left(\frac{A}{N_S^{\alpha^\prime}}+\frac{B}{D_S^{\beta^\prime}}\right)^{\gamma^\prime}}{\text{学生模仿老师的能力}}
\end{aligned} $$
其中 $\{c_0,c_1,d_1,f_1,\alpha^\prime,\beta^\prime,amma^\prime\}$ 是正系数,在 4.2 中产生的数据上进行拟合。 我们可以很容易地验证蒸馏缩放定律的前两个性质。对于第三个性质,回想一下,$\widetilde{L}_S=L(N_S,D_S)$ 是学生在监督学习方式下训练所能达到的交叉熵,并且可以从监督缩放定律中确定。容量差距行为源于学生和教师算法学习容量之比的转变;当 $L_T/\widetilde{L}_S \equiv L(N_T,D_T)/L(N_S,D_S) = d_1$ 时,这可以解释为衡量教师和学生在参考任务上的相对学习能力。
蒸馏缩放定律参数拟合
我们使用教师模型 $(N_T, D_T)$ 来拟合我们的监督缩放定律,并使用所有数据来拟合我们的蒸馏缩放定律。我们的监督和蒸馏缩放定律以 $\lesssim1\%$ 的相对预测误差水平拟合观测结果,包括从较弱模型外推到较强模型时(参见图5b)。

作为进一步的验证,我们确认对于固定的模型大小,在无限数据情况下,知识蒸馏的结果与在无限数据上进行监督学习的结果一致。
蒸馏缩放定律的应用
在这里,我们应用我们的蒸馏缩放定律,并研究感兴趣的场景。通常,蒸馏预训练中的资源包括计算预算或包含多个 Token 的数据集。对于蒸馏过程,计算成本可以近似为 $$ \hspace{-.2cm} \mathrm{FLOPs}\approx
\underbrace{3F(N_S)D_S}{\substack{\mathrm{Student}\\mathrm{Training}}} +F(N_T)(\underbrace{\delta_T^{\mathrm{Lgt}}D_S}{\substack{\mathrm{Teacher}\\mathrm{Logits}}} + \underbrace{\delta_T^{\mathrm{Pre}}3D_T}_{\substack{\mathrm{Teacher}\\mathrm{Training}}}) \label{eq:distillation-compute} $$ 其中,$\delta_T^{\mathrm{Lgt}},\delta_T^{\mathrm{Pre}}\in[0,1]$ 表示是否考虑学生目标[^5]的教师 Logit 推理成本,以及总计算预算中的教师预训练成本。$F(N)$ 是具有 $N$ 个参数的模型在一次前向传递中执行的 [flops]数量。通常使用 $F(N)\approx 2N$,由此得出监督学习的计算量 $\mathrm{FLOPs}\approx 6ND$。我们不能直接使用 $2N$ 这个近似值,原因在于:i) 使用非嵌入参数 $N$ 会导致系统性误差;ii) 我们关注的是具有较大上下文长度的小模型,在这种情况下,注意力机制对 FLOPs 的贡献非常显著。为了解决这些问题,我们推导出一个简单的表达式 $F(N)\approx 2N(1+c_1N^{-1/3}+c_2N^{-2/3})$,用于固定纵横比的模型 ,并建议缩放社区考虑采用这种超参数设置。
固定 Token 或计算量(最佳情况)
为了更好地理解知识蒸馏在什么情况下可能(以及可能不)有益,我们提出一个问题:与监督学习相比,知识蒸馏在最佳情况下能做得多好? 我们将图2和3的数据叠加到蒸馏交叉熵 $L_S$ 的轮廓线上,并与具有相同资源的监督模型 $\widetilde L_S$ 进行比较 (6)。
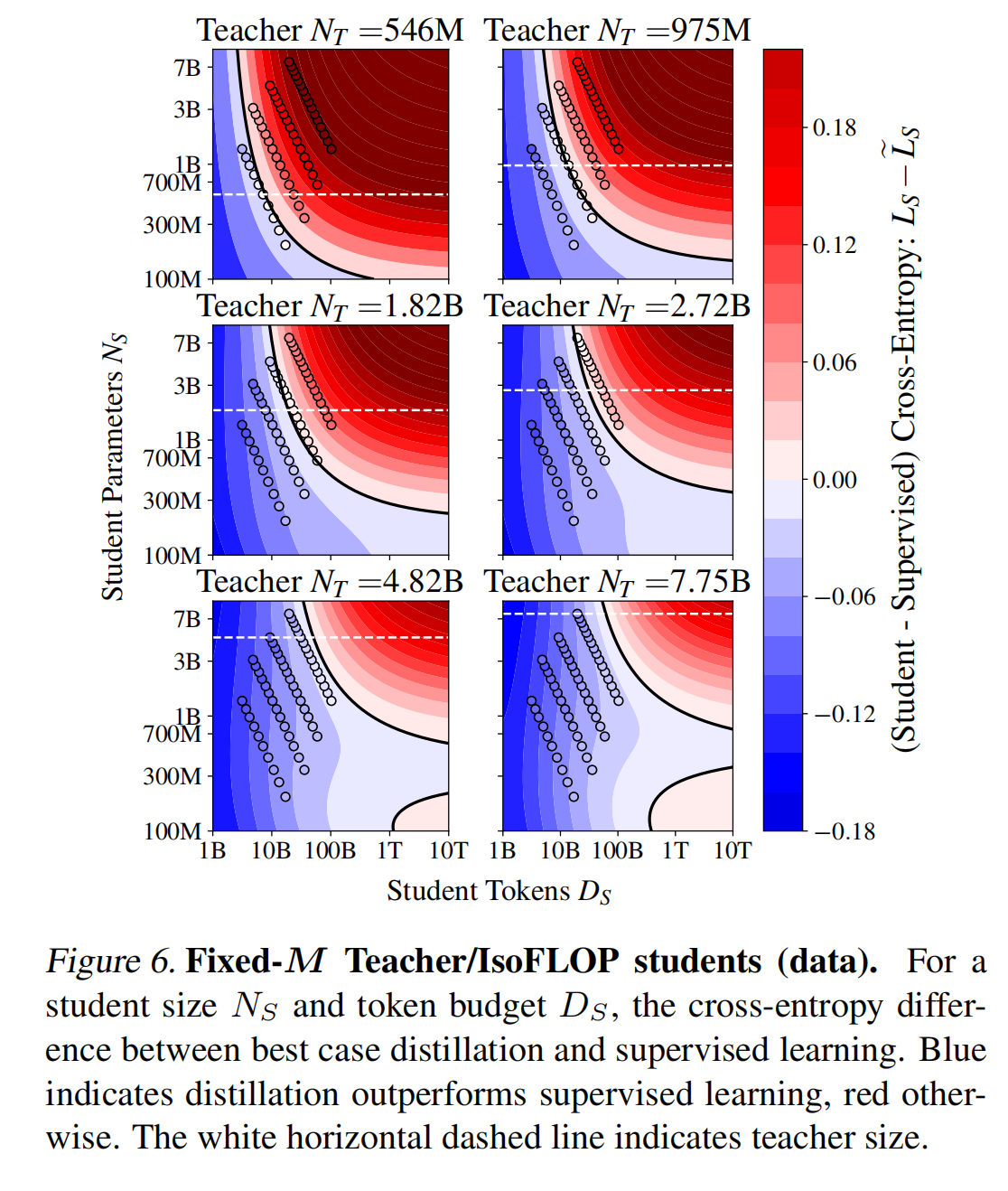
在拥有充足的学生计算资源或 Token 的前提下,监督学习始终优于知识蒸馏。
对于适中的 Token 预算,知识蒸馏更具优势;然而,当拥有大量 Token 时,监督学习的表现将超越知识蒸馏。这是符合预期的;在大数据体制下,监督学习能够找到受模型大小 $N$ 限制的最优解,而知识蒸馏仅能为最优教师模型 $L_T^*$ 找到此解,否则将受到知识蒸馏过程的制约。这一发现似乎与 @DBLP:conf/cvpr/BeyerZRMA022 的耐心教师理论相悖。
固定 Token 或计算量(教师推理)
接下来,我们关注一个常见的场景:计划进行知识蒸馏,并尝试在现有的一组教师模型 $\{(L_T^{(i)},N_T^{(i)})\}_{i=1}^n$ 中做出选择。更大的教师模型可能提供更好的学习信号(更低的交叉熵),但由于教师 logits 的成本,使用起来也会更昂贵,从而导致一种权衡。给定目标学生模型大小 $N_S$ 和预算 $D_S$ 或 $C_{\mathrm{Total}}$,唯一的自由度是教师模型的选择。
对于固定的数据预算,随着学生模型规模的增加,教师交叉熵应以幂律形式降低
这里,$N_T$ 的计算成本无关紧要,因为我们考虑的是 Token 预算。不同蒸馏 Token 预算下的学生交叉熵如图 7 所示。
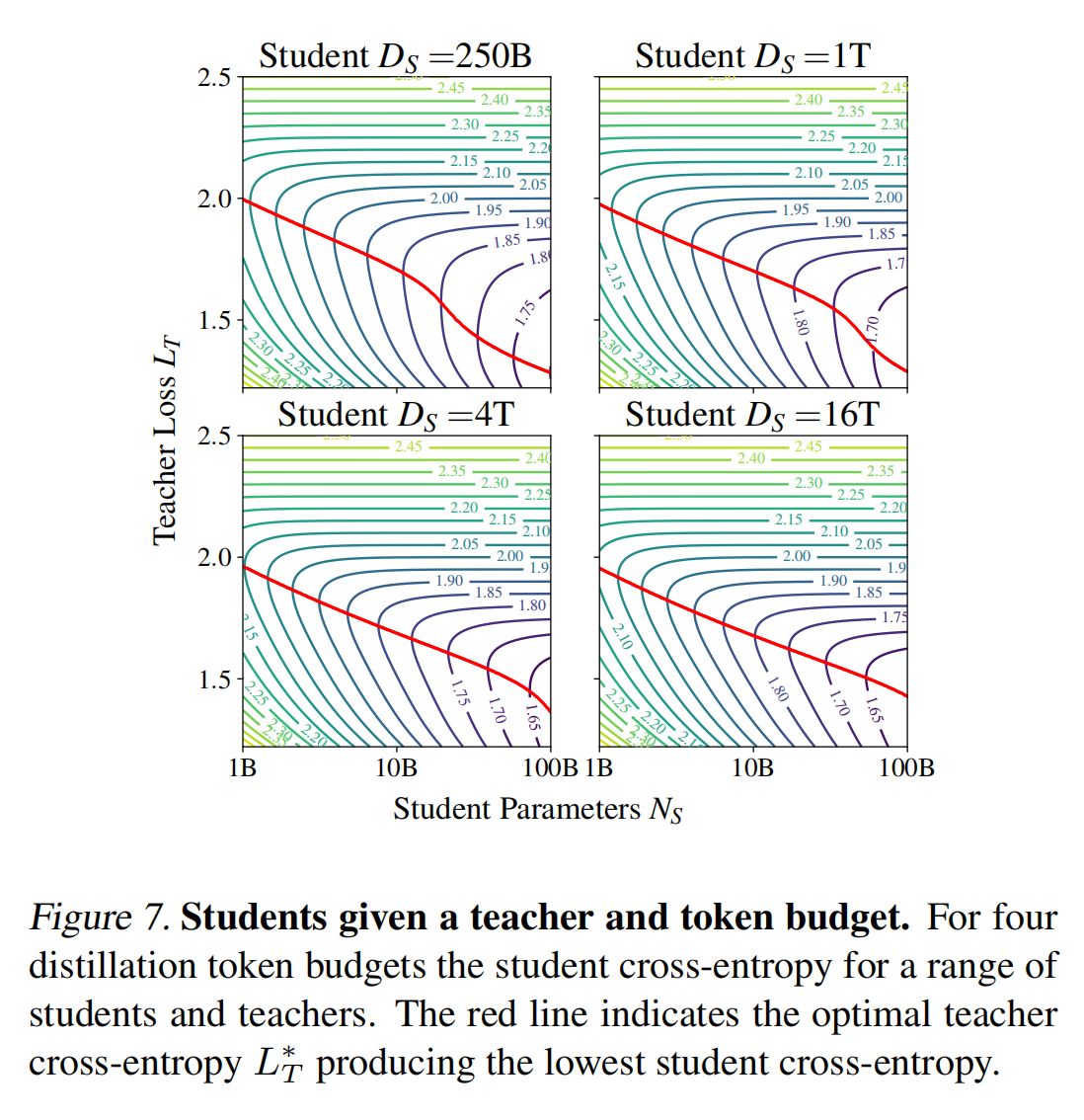
对于不同学生规模,同时改变 Token数量 的等效图,请参见 。我们看到,最佳教师损失 $L_T^*$ (红线) 随着学生规模 $N_S$ 的增大而以幂律形式减小,直到 $L_S$ 与 $L_T^*$ 相匹配。此时,$L_T^*$ 中会出现拐点,导致教师损失随着 $N_S$ 的增大而加速减小。这推广了 @DBLP:journals/corr/abs-2311-07052 的观察结果,即“最佳教师规模在不同的模型架构和数据规模下,几乎始终遵循与学生规模的线性缩放”,这是在我们发现的教师计算最优情况下的一个特例。请注意,我们的研究结果始终表明,教师交叉熵损失 $L_T$ 决定了学生交叉熵损失 $L_S$,而不是 $N_T$ 本身(这导致给定的 $L_T$)。
计算最优蒸馏
我们将 @DBLP:journals/corr/abs-2203-15556 的分析扩展到蒸馏,给出计算最优蒸馏,确定如何在给定计算预算 $C$ 的情况下,以最低的交叉熵生成所需大小为 $N_S$ 的学生模型。
$$ \begin{aligned}
D_S^,N_T^,D_T^*=\mathop{\mathrm{arg,min}}_{D_S,N_T,D_T}&L_S(N_S,D_S,N_T,D_T)\nonumber \
\mathrm{s.t.} \quad \mathrm{FLOPs}&=C,
\label{eq:distillation-optimal}
\end{aligned}
$$
为了展示将教师模型推理纳入计算约束的最佳和最坏情况,我们考虑 all scenarios中提出的所有场景。我们还将与最优的监督性能进行比较。为了找到上式中的最小值,我们使用 SciPy 中的 [slsqp]执行约束数值最小化。
在足够的计算预算下,监督学习始终与最佳蒸馏相匹配,并且随着学生模型规模的增长,两者相交点更倾向于监督学习。
在8中,我们看到监督学习在一定的总计算预算下始终与最佳情况的蒸馏设置相匹配,正如渐近分析所预期的那样。当监督学习比蒸馏更可取时,计算转换点会随着学生模型规模的增加而增加。我们还观察到,较小的模型更可能从监督预训练中受益,而较大的模型更可能从蒸馏中受益。
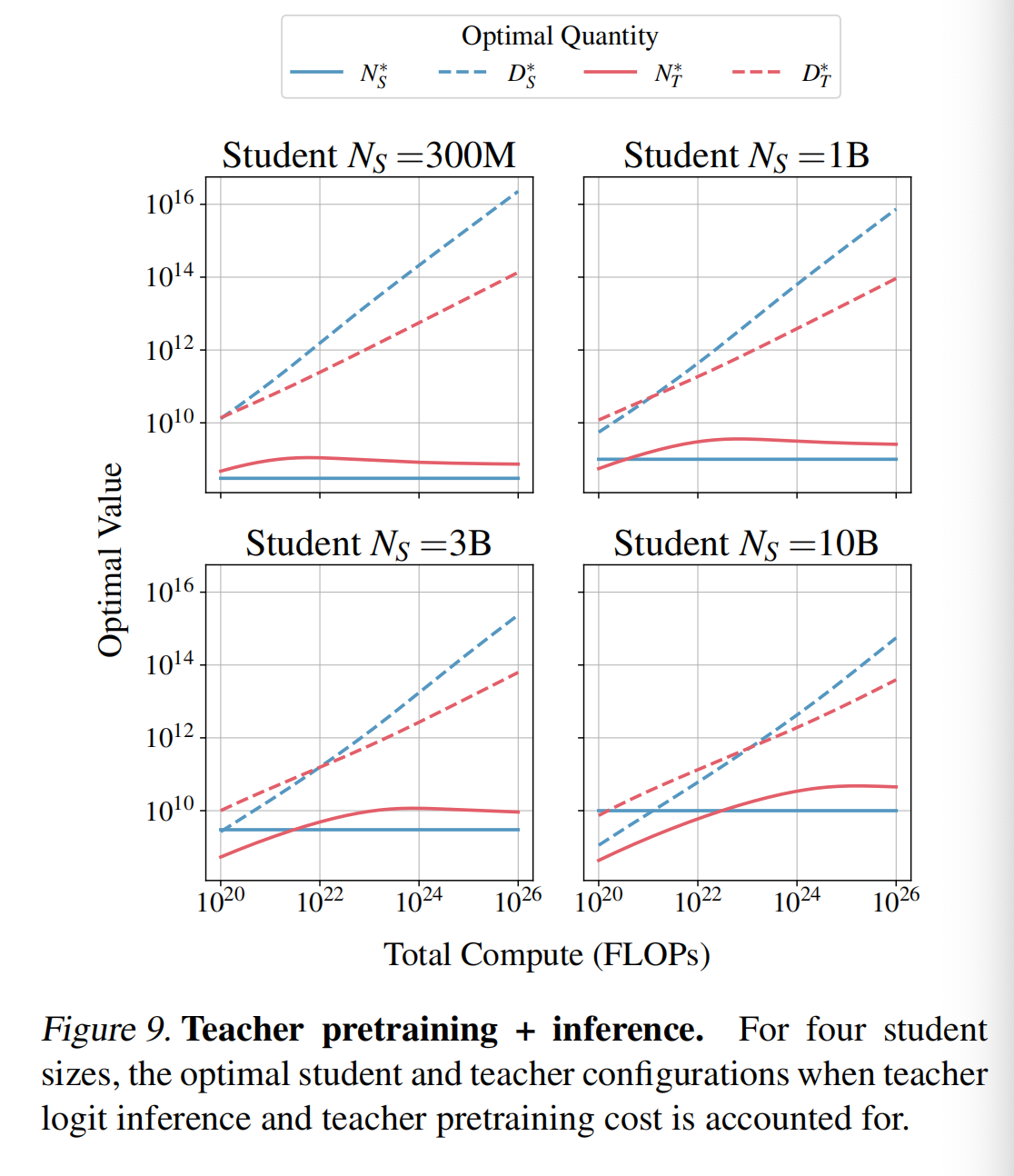
当教师模型训练包含在计算资源内时,最佳学生模型的交叉熵始终高于监督学习的设置。
这意味着如果你的唯一目标是生成一个特定目标大小的最佳模型,并且你无法访问教师模型,那么你应该选择监督学习,而不是训练一个教师模型然后进行知识蒸馏。相反,如果目的是将知识蒸馏到一系列模型中,或者将教师模型用作服务器模型,那么知识蒸馏可能比监督学习在计算上更有优势。仔细思考后,这个发现是符合预期的,否则它将意味着在总计算资源一定的情况下,知识蒸馏可以胜过直接的最大似然优化。
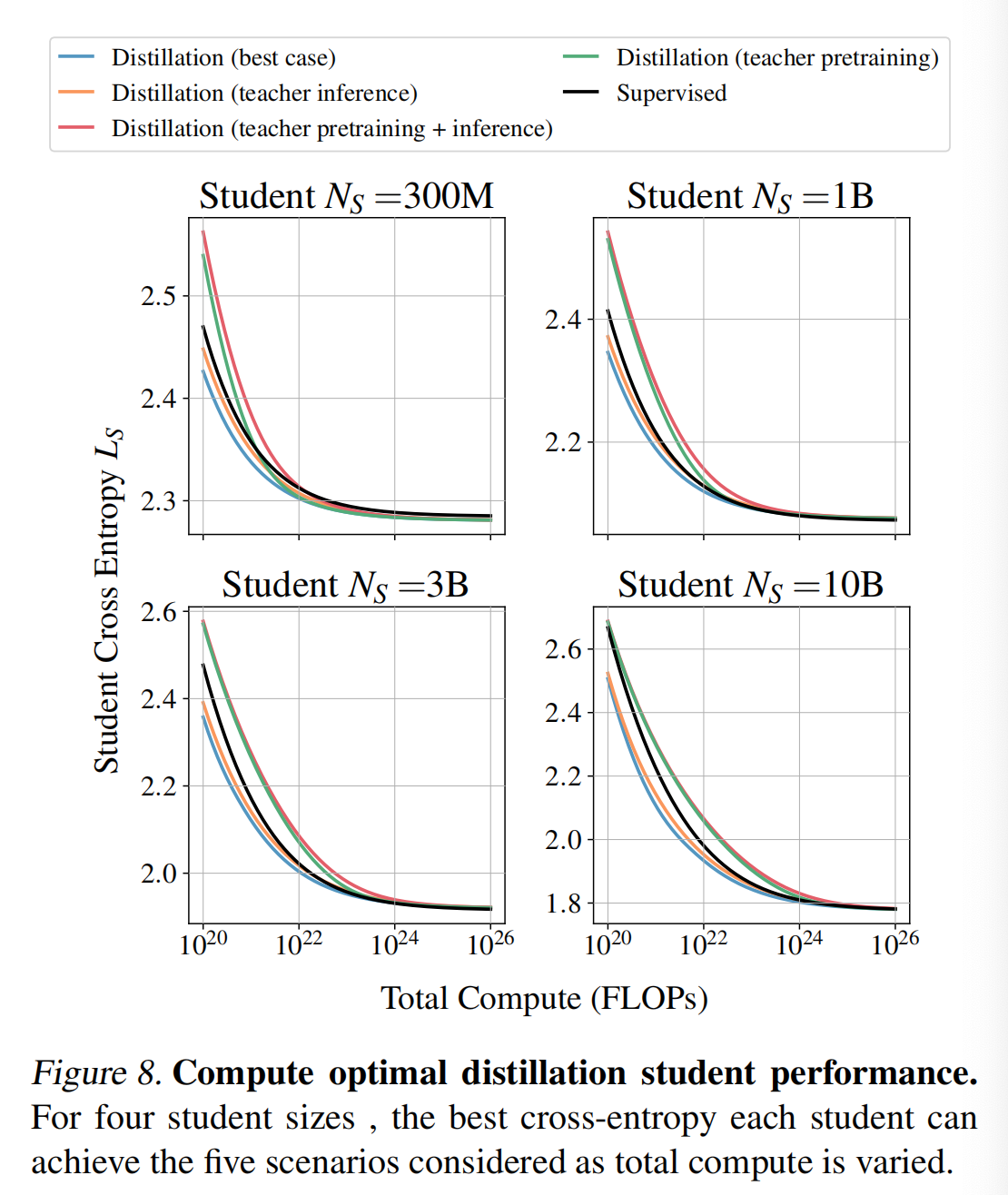
为了建立对这些量如何相互作用的直觉,我们采用最复杂的场景,即教师预训练 + 推理。 随着计算量的变化,最优蒸馏设置的可视化结果在 9中呈现。