

我们都认识到 DeepSeek模型的优势,但您是否知道,其近一半的图层的贡献低于预期? 我们可以移除近一半的后置图层,而对性能的影响微乎其微,对于大型模型而言影响甚至更大。这意味着浪费了大量用于训练 LLM 的资源。 在本文中,我们将介绍深度诅咒(Curse of Depth)这一概念,它强调、解释并解决了最近在现代 LLM 中观察到的近一半层的有效性低于预期的问题。
摘要
我们提出了一种新颖的深度神经网络训练方法,该方法结合了监督学习和无监督学习的优势。我们的方法,我们称之为“半监督对比学习”(SSCL),利用带标签的数据学习判别性特征,同时利用未标签的数据来提高模型的鲁棒性和泛化能力。SSCL 基于对比学习的原则,即训练模型将相似样本的表示聚集在一起,同时将不相似样本的表示推开。然而,与传统的对比学习方法不同,SSCL 通过使用带标签数据的标签来指导对比学习过程,从而整合了监督信息。具体来说,我们引入了一种新的损失函数,该函数将监督对比损失与无监督对比损失相结合。监督对比损失鼓励模型学习相对于带标签类别具有判别性的特征,而无监督对比损失鼓励模型学习对未标签数据中的变化具有鲁棒性的特征。我们在各种图像分类任务上评估了 SSCL,结果表明,尤其是在带标签数据的数量有限时,它优于监督学习和无监督学习方法。此外,我们证明了 SSCL 可用于学习对对抗攻击不太敏感的鲁棒特征。
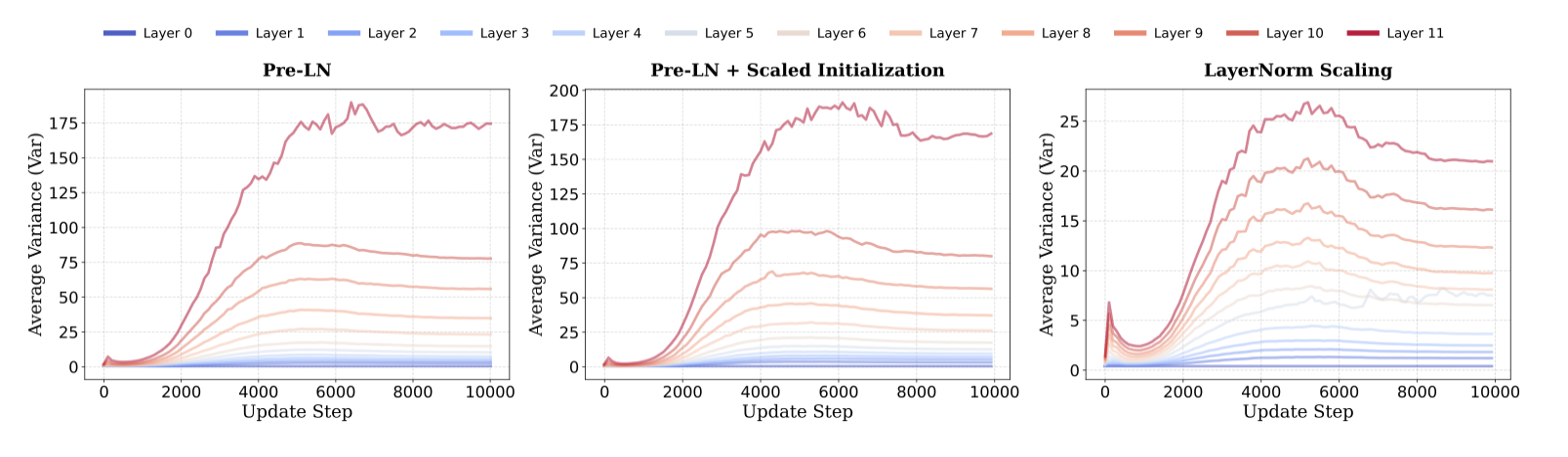
在本文中,我们介绍了深度诅咒,这一概念旨在强调、解释并解决现代大语言模型 (LLM) 中最近观察到的现象:近一半的层其效果不如预期。我们首先确认了这种现象在最流行的 LLM 家族中广泛存在,例如 Llama、Mistral、DeepSeek 和 Qwen。我们的分析,从理论和经验两方面出发,都表明 LLM 中深层效果不佳的根本原因是 Pre-Layer Normalization (Pre-LN,预层归一化) 的广泛使用。虽然 Pre-LN 能够稳定 Transformer 大语言模型的训练过程,但其输出方差会随着模型深度的增加呈指数级增长,这导致深层 Transformer 模块的导数趋近于单位矩阵,因此几乎无法对训练做出有效贡献。为了解决这个训练难题,我们提出了 LayerNorm Scaling(层归一化缩放),它通过层归一化深度的平方根倒数来缩放输出方差。这种简单的修改能够有效缓解更深层 Transformer 层的输出方差爆炸问题,从而提高它们的贡献。我们的实验结果涵盖了从 1.3 亿到 10 亿参数规模的模型,结果表明,与 Pre-LN 相比,LayerNorm Scaling 能够显著提升 LLM 预训练的性能。此外,这种性能提升也能无缝延续到监督微调阶段。所有这些增益都可以归因于 LayerNorm Scaling 使得更深层能够在训练过程中更有效地发挥作用。我们的代码已在 LayerNorm-Scaling 开源。
介绍
最近的研究表明,大语言模型(LLM)中较深的层(Transformer blocks)往往不如较早的层有效。一方面,这个有趣的观察结果为大语言模型压缩提供了一个有效的指标。例如,我们可以更大幅度地压缩较深的层,以实现更高的压缩率。更激进的做法是,为了获得更经济实惠的大语言模型,可以完全剪枝整个深层,而不会影响性能。另一方面,拥有许多无效层是不可取的,因为大语言模型在训练时极其耗费资源,通常需要数千个GPU训练数月,更不用说用于数据整理和管理的劳动力。理想情况下,我们希望模型中的所有层都经过良好训练,层与层之间的特征具有足够的差异性,以最大限度地提高资源的利用率。无效层的存在表明,当前的大语言模型范式必然存在问题。解决这些局限性是社区的迫切需求,以避免浪费宝贵的资源,因为新版本的大语言模型通常沿用之前的计算范式进行训练,这会导致无效层的产生。
为了立即引起社区的关注,我们引入了深度诅咒(CoD)的概念,以系统地呈现各种大语言模型(LLM)家族中无效深层现象,从而识别其背后的根本原因,并通过提出层归一化缩放(LayerNorm Scaling)来纠正它。我们首先陈述下面的深度诅咒。
深度诅咒。 ==深度诅咒指的是观察到的现象,即与早期层相比,LLM中更深层对学习和表示的贡献明显更少。这些更深层通常表现出对模型剪枝和扰动攻击的显着鲁棒性,这意味着它们无法执行有意义的转换。这种行为阻止了这些层有效地促进训练和表示学习,从而导致资源利用率低。==
CoD 的经验证据。@yin2023outlier 发现,与较浅的层相比,大语言模型的较深层可以容忍显著更高程度的剪枝,从而实现高稀疏性。类似地,@gromov2024unreasonable 和 @men2024shortgpt 证明,移除早期层会导致模型性能急剧下降,而移除深层则不会。@lad2024remarkable 表明,GPT-2 和 Pythia 的中间层和深层对诸如层交换和层丢弃之类的扰动表现出显著的鲁棒性。最近,@li2024owlore 强调,早期层包含更多的异常值,因此对于微调更为关键。虽然这些研究有效地突出了大语言模型中深层的局限性,但它们未能确定此问题的根本原因或提出可行的解决方案来解决它。为了证明深度诅咒在流行的 LLM 系列中普遍存在,我们对各种模型(包括 LLaMA2-7/13B、Mistral-7B、DeepSeek-7B 和 Qwen-7B)进行了层剪枝实验。我们通过一次剪除每个模型的整个层,并直接在 MMLU 上评估生成的剪枝模型,来衡量大规模多任务语言理解 (MMLU) 基准上的性能下降,如图1所示,无需进行任何微调。
结果: 1). 大多数使用预层归一化 (Pre-LN) 的大语言模型在移除更深层时表现出显著的稳健性,而使用 Post-LN 的 BERT 则呈现相反的趋势。2). 在不显著降低性能的情况下可以被剪枝的层数随着模型大小的增加而增加。
识别 CoD 的根本原因。 我们从理论上和经验上将 CoD 的根本原因确定为使用预层归一化 (Pre-LN),它在应用主要计算(例如注意力或前馈操作)之前对层输入进行归一化,而不是之后。具体来说,在稳定训练的同时,我们观察到 Pre-LN 的输出方差随着层深度的增加而显著累积,导致深层 Pre-LN 层的导数接近单位矩阵。这种行为阻止了这些层引入有意义的转换,从而导致表示学习的减少。
通过 LayerNorm 缩放缓解 CoD。 我们提出了 LayerNorm 缩放,它通过深度的平方根 $\frac{1}{\sqrt{l}}$ 来缩放 Layer Normalization 的输出。LayerNorm 缩放有效地缩减了 Pre-LN 各层的输出方差,从而显著降低了训练损失,并仅使用一半的 Token 就达到了与 Pre-LN 相同的损失。图2比较了不同设置下的分层输出方差:(1)Pre-LN,(2)具有缩放初始化的 Pre-LN,以及(3)LayerNorm 缩放。如图所示,Pre-LN 在更深的层中表现出显著的方差爆炸。相比之下,LayerNorm 缩放有效地降低了各层的输出方差,从而增强了训练期间更深层的贡献。这种调整导致训练损失比 Pre-LN 显著降低。与之前的 LayerNorm 变体不同,LayerNorm 缩放易于实现,无需超参数调整,并且在训练期间不引入额外的参数。此外,我们进一步表明,使用 LayerNorm 缩放预训练的模型在自监督微调的下游任务中实现了更好的性能,这都要归功于学习到的更有效的深层。 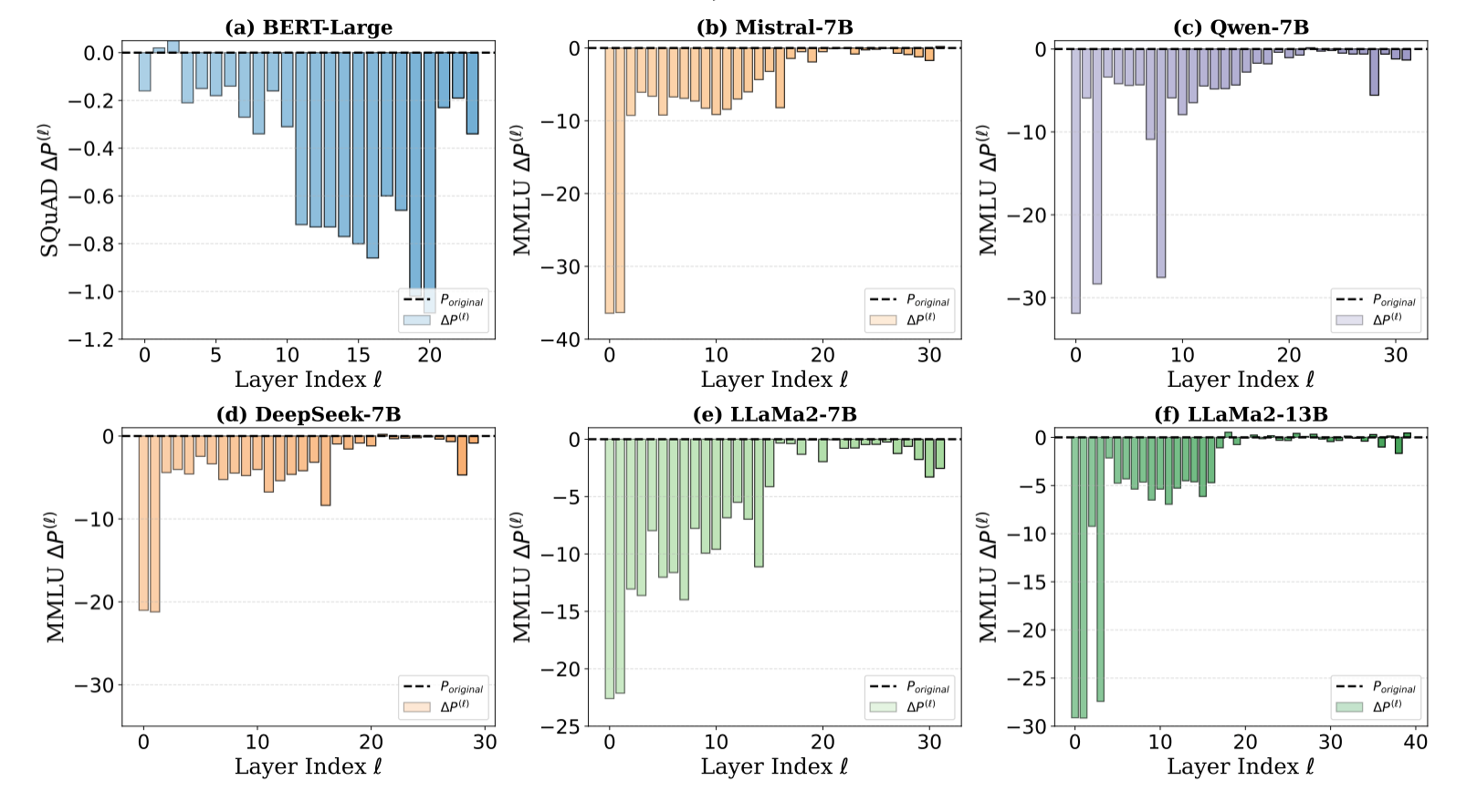
图2
贡献。
- 我们引入了深度诅咒这一概念,旨在强调、理解并纠正大语言模型(LLM)中一个常被忽视的现象——深层未能像它们应该的那样有效地做出贡献。
- 我们将根本原因归结为Pre-LN(预层归一化),它会导致输出方差随着模型深度的增加而呈指数增长。这导致深层Transformer块的导数接近单位矩阵,使得它们在训练期间变得无效。虽然缩放初始化有助于缓解初始化时的方差,但它并不能阻止训练期间的梯度爆炸。
- 为了缓解这个问题,我们提出了LayerNorm Scaling(层归一化缩放),它将Pre-LN的输出按深度的平方根进行反向缩放。这种调整确保了所有层都能有效地为学习做出贡献,从而提高大语言模型的性能。
- 我们希望这项工作能引起人们对这个问题的更多关注,有助于改进大语言模型,并最大限度地利用专门用于训练大型模型的计算资源。
深度诅咒的经验证据
为了实证分析层归一化对大语言模型中深度诅咒的影响,我们进行了一系列评估,这些评估的灵感来自 @li2024mix,并将他们的方法扩展到比较 Pre-LN 和 Post-LN 模型。
实验设置
方法: 我们通过评估在不同深度进行层剪枝的影响来评估 Pre-LN 和 Post-LN 模型。我们的假设是,Pre-LN 模型在更深层中表现出递减的有效性,而 Post-LN 模型的早期层效果较差。为了验证这一点,我们通过实证量化各个层对各种大语言模型整体模型性能的贡献。
大语言模型: 我们在多个广泛采用的大语言模型上进行实验:BERT-Large、Mistral-7B、LLaMA2-7B/13B、DeepSeek-7B 和 Qwen-7B。选择这些模型是为了确保架构和应用的多样性。BERT-Large 代表一个 Post-LN 模型,而其余的都是基于 Pre-LN 的模型。这种选择能够全面评估层归一化在不同架构和模型规模上的影响。
$$ \Delta P^{(\ell)} = P_{\text{pruned}}^{(\ell)} - P_{\text{original}}, $$其中,$P_{\text{original}}$ 代表未剪枝模型的性能,而 $P_{\text{pruned}}^{(\ell)}$ 表示移除第 $\ell$ 层后的性能。较低的 $\Delta P^{(\ell)}$ 表明被剪枝的层在模型的整体有效性中起着较小的作用。对于 BERT-Large,我们在 SQuAD v1.1 数据集上评估性能,该数据集衡量阅读理解能力。对于 Mistral-7B、LLaMA2-13B 和 Qwen-7B,我们在 MMLU 基准上评估模型性能,MMLU 是一个广泛使用的多任务语言理解数据集。
层剪枝分析
图2展示了六个大语言模型在不同层上的性能下降 ($\Delta P^{(\ell)}$),其中包括一个 Post-LN 模型 (BERT-Large) 和五个 Pre-LN 模型 (Mistral-7B, LLaMA2-13B, Qwen-7B, DeepSeek-7B 和 LLaMA2-7B)。如图2 (a) 所示,在 BERT-Large 中剪枝更深层的层会导致在 SQuAD v1.1 上的准确率显著下降,而剪枝较早的层影响则微乎其微。性能下降 $\Delta P^{(\ell)}$ 在第 10 层之后变得尤为严重,突显了更深层在维持 Post-LN 模型整体性能方面的关键作用。相比之下,移除网络前半部分的层导致的变化可以忽略不计,表明它们对最终输出的贡献有限。
如图[2(b)-(f)所示,Pre-LN 模型呈现出一种对比鲜明的模式,其中较深层对整体模型性能的贡献显著降低。例如,如图2(b) 和 (c) 所示,对 Mistral-7B 和 Qwen-7B 模型最后三分之一的层进行剪枝,在 MMLU 上的性能下降很小,表明这些层对整体准确性的贡献有限。相比之下,对前几层进行剪枝会导致显著的准确性下降,突显了它们在特征提取中的关键作用。类似地,图[2(d) 和 (e) 显示 DeepSeek-7B 和 LLaMA2-7B 也遵循类似的模式,较深层对性能的影响很小,而较早的层则发挥着更重要的作用。最后,如图2(f) 所示,LLaMA2-13B 中超过一半的层可以安全地移除。这表明,随着模型尺寸的增加,浅层和深层之间的对比变得更加明显,较早的层在表征学习中起着主导作用。这一观察结果强调了社区需要解决深度诅咒问题,以防止资源浪费。
预备知识
$$ y = x_{\ell+1} = x^\prime_\ell + \mathrm{FFN}(\mathrm{LN}(x^\prime_\ell)), \label{x_result} $$$$ x^\prime_\ell = x_\ell + \mathrm{Attn}(\mathrm{LN}(x_\ell)), \label{xprime_result} $$$$ \begin{aligned} \mathrm{FFN}(x) &= W_2 \mathcal{F}(W_1 x), \\ \mathrm{Attn}(x) &= W_O (\mathrm{concat}(\mathrm{head}_1(x), \dots, \mathrm{head}_h(x))), \\ \end{aligned} $$$$ \mathrm{head}_i(x) = \mathrm{softmax} \left( \frac{(W_{Qi} x)^\top (W_{Ki} X)}{\sqrt{d_\mathrm{head}}} \right) (W_{Vi} X)^\top, $$$$ \frac{\partial \text{Pre-LN}(x)}{\partial x} = I + \frac{\partial f (\text{LN}(x))}{\partial \text{LN}(x)} \frac{\partial \text{LN}(x)}{\partial x}, $$其中,$f$ 在此代表多头注意力函数或 FFN 函数。如果项 $\frac{\partial f (\text{LN}(x))}{\partial \text{LN}(x)} \frac{\partial \text{LN}(x)}{\partial x}$ 变得过小,Pre-LN 层 $\frac{\partial \text{Pre-LN}(x)}{\partial x}$ 的行为会类似于恒等映射。我们的主要目标是防止极深的 Transformer 网络出现恒等映射行为。此过程的第一步是计算向量 $x_{\ell}$ 的方差 $\sigma^2_{x_\ell}$。
Pre-LN Transformers
假设 1. 设 $x_\ell$ 和 $x^\prime_\ell$ 分别表示第 $\ell$ 层的输入和中间向量。此外,设 $W_\ell$ 表示第 $\ell$ 层的模型参数矩阵。我们假设,对于所有层,$x_\ell$,$x^\prime_\ell$ 和 $W_\ell$ 服从均值为 $\mu = 0$ 的正态独立分布。
$$ \sigma^2_{x_{\ell}} = \sigma_{x_1}^2 \Theta\Bigl(\prod_{k=1}^{\ell-1} \left( 1 + \frac{1}{\sigma_{x_k}} \right) \Bigr), \label{sigma_l} $$$$ \Theta(L) \leq \sigma^2_{x_l} \;\leq\; \Theta(\exp(L)). $$这里,符号 $\Theta$ 的意思是:如果 $f(x) \in \Theta\bigl(g(x)\bigr)$,那么存在常数 $C_1, C_2$ 使得当 $x \to \infty$ 时,$C_1\,|g(x)| \le |f(x)| \le C_2\,|g(x)|$。下界 $\Theta(L) \leq \sigma^2_{x_\ell}$ 表明 $\sigma^2_{x_\ell}$ 至少线性增长,而上界 $\sigma^2_{x_\ell} \leq \Theta(\exp(L))$ 意味着它的增长不超过 $L$ 的指数函数。
基于假设 1以及相关研究工作,我们得到以下定理:
$$ \frac{\partial y_L}{\partial x_1} = \prod_{\ell=1}^{L-1} \left( \frac{\partial y_\ell}{\partial x^\prime_\ell} \cdot \frac{\partial x^\prime_\ell}{\partial x_\ell} \right). $$$$ \left\| \frac{ \partial y_L}{\partial x_1} \right\|_2 \leq \prod_{l=1}^{L-1} \left( 1 + \frac{1}{\sigma_{x_\ell}} A + \frac{1}{\sigma_{x_\ell}^2} B \right), $$$$ \sigma^2_{x_\ell} \sim \exp(\ell), \quad \left\| \frac{\partial y_L}{\partial x_1} \right\|_2 \leq M, $$$$ \sigma^2_{x_\ell} \sim \ell, \quad \left\| \frac{\partial y_L}{\partial x_1} \right\|_2 \leq \Theta(L), $$这意味着梯度范数随 $L$ 线性增长。
我们观察到,当方差呈指数增长时,随着层数 $L \to \infty$,范数 $\left\| \frac{\partial y_L}{\partial x_1} \right\|_2$ 被一个固定常数 $M$ 所限制。这个结果意味着即使是无限深度的 Transformer 仍然是稳定的,并且根据 Weierstrass 定理,网络能够保证收敛。因此,这意味着对于非常大的 $L$ 值,更深层的行为几乎就像从 $x_\ell$ 到 $y_\ell$ 的恒等映射,从而限制了模型的表达能力,并阻碍其学习有意义的转换。
这个结果并非我们所期望的,因此,我们更倾向于方差以更缓慢的方式增长——例如,线性增长——以便 $\left\| \frac{\partial y_L}{\partial x_1} \right\|_2$ 呈现线性增长。这一观察结果突显了适当的方差控制机制(例如缩放策略)的必要性,以防止过度的恒等映射,并提高网络深度利用率。
Post-LN Transformer
对于 Post-LN Transformer,我们继续采用假设 1。 在这种设置下,每一层之后都会进行层归一化 (LN) 处理,确保方差 $\sigma^2_{x_\ell}$ 和 $\sigma^2_{x^\prime_\ell}$ 在所有层中保持固定为 1。 因此,范数 $\left\| \frac{\partial y_\ell}{\partial x_\ell} \right\|_2$ 从一层到下一层的变化非常小,表明梯度传播是稳定的。
由于在 Post-LN Transformer 中,方差通过 LN 得到有效控制,因此基于方差的显式分析变得不那么重要。 然而,在更深层的 Post-LN 架构中,仍然存在其他重要的方面需要研究,例如特征映射的演变以及协方差核在深层中的表现。 这些方向将在未来的工作中继续进行研究。
LayerNorm 缩放
我们的理论和实证分析表明,Pre-LN 会放大输出方差,导致深度诅咒并降低更深层网络的有效性。 为了缓解这个问题,我们提出了 LayerNorm 缩放,这是一种简单而有效的归一化策略。 LayerNorm 缩放的核心思想是通过根据层深度缩放归一化输出来控制 Pre-LN 中输出方差的指数增长。 具体来说,我们应用一个与层索引的平方根成反比的缩放因子来缩小 LN 层的输出,从而稳定梯度流并增强训练期间更深层 Transformer 层的贡献。 LayerNorm 缩放如图 3所示。
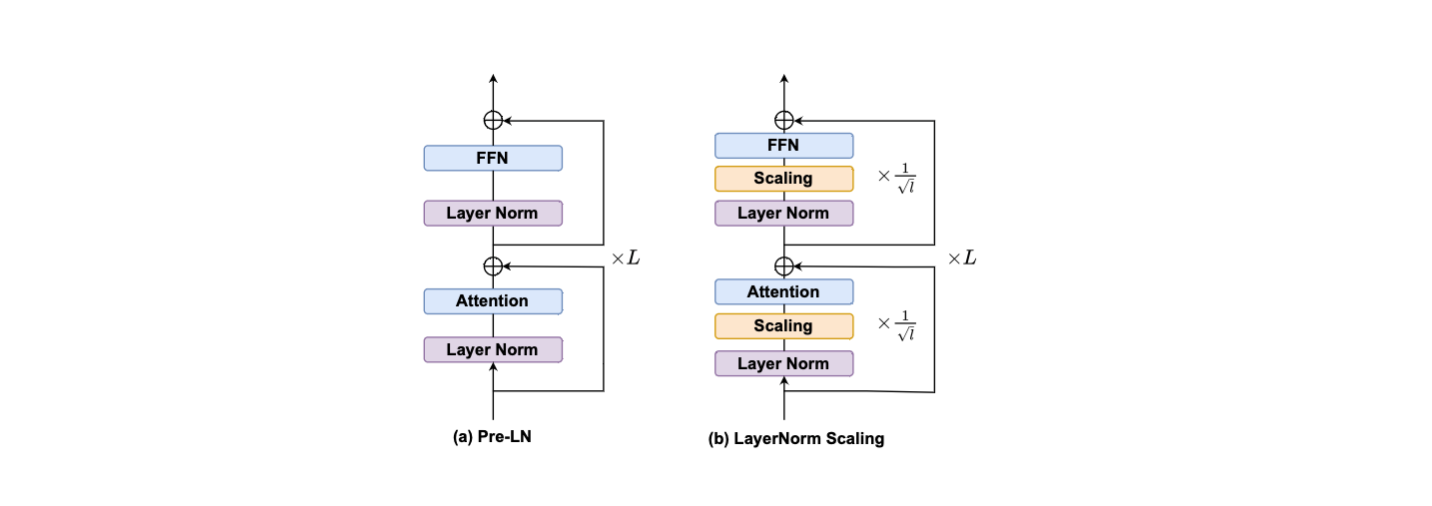
图3。
$$ \mathbf{h}^{(l)} = \text{LayerNorm}(\mathbf{h}^{(\ell)}) \times \frac{1}{\sqrt{\ell}}, $$其中 $\ell \in \{1, 2, \dots, L\}$。这种缩放可以防止方差随深度过度增长,解决了 Pre-LN 的一个关键限制。与 Mix-LN 不同,Mix-LN 可以稳定更深层的梯度,但会因 Post-LN 导致训练不稳定,而 LayerNorm Scaling 保留了 Pre-LN 的稳定性优势,同时增强了更深层对表征学习的贡献。应用 LayerNorm Scaling 可以显著降低每层输出方差,从而比原始 Pre-LN 产生更低的训练损失和更快的收敛速度。此外,与之前的 LayerNorm 变体相比,LayerNorm Scaling 是无超参数的,易于实现,并且不会引入额外的可学习参数,使其计算效率高且易于应用于现有的 Transformer 架构。
LayerNorm 缩放的理论分析
$$\begin{aligned} \sigma^2_{x_{\ell+1}} =\sigma_{x_\ell}^2 \Theta( 1 + \frac{1}{\sqrt{\ell} \sigma_{x_\ell}}), \end{aligned}$$$$ \Theta(L) \leq \sigma^2_{x_L} \;\leq\; \Theta(L^{(2-\epsilon)}). $$其中 $\epsilon$ 是一个小数,且 $0< \epsilon \leq 1/4$。
可以得出结论,我们的缩放方法有效地减缓了方差上限的增长速度,将其从指数增长降低到多项式增长。具体来说,它将上限限制为二次速率,而非指数速率。基于定理 1,经过缩放后,我们得到以下结果:
$$ \left\| \frac{ \partial y_L}{\partial x_1} \right\|_2 \leq \prod_{\ell=1}^{L-1} \left( 1 + \frac{1}{\ell\sigma_{x_\ell}} A + \frac{1}{\ell^2\sigma_{x_\ell}^2} B \right), $$$$ \sigma^2_{x_\ell} \sim \ell^{(2-\epsilon)}, \quad \left\| \frac{\partial y_L}{\partial x_1} \right\|_2 \leq \omega(1), $$$$ \sigma^2_{x_\ell} \sim \ell, \quad \left\| \frac{\partial y_L}{\partial x_1} \right\|_2 \leq \Theta(L). $$通过比较定理 1(缩放前)与定理 2(缩放后),我们观察到方差上限的显著降低。具体来说,它从指数增长 $\Theta(\exp(L))$ 降低到最多二次增长 $\Theta(L^2)$。事实上,这种增长甚至比二次扩展还要慢,因为它遵循 $\Theta(L^{(2-\epsilon)})$,其中 $\epsilon > 0$ 是一个很小的数。当我们为这种扩展选择一个合理的上限时,我们发现 $\left\| \frac{\partial y_L}{\partial x_1} \right\|_2$ 不再具有严格的上限。也就是说,随着深度的增加,$\left\| \frac{\partial y_L}{\partial x_1} \right\|_2$ 继续逐渐增长。因此,与原始 Pre-LN 相比,作为恒等映射的层数更少,在原始 Pre-LN 中,几乎所有深层都坍缩为恒等变换。相反,缩放后的网络有效地利用了更多的层,即使深度接近无穷大,从而提高了表达能力和可训练性。
LLM预训练
为了评估 LayerNorm Scaling 的有效性,我们遵循 @li2024mix 的实验设置,使用相同的模型配置和训练条件,将其与广泛使用的归一化技术进行比较,包括 Post-LN、DeepNorm 和 Pre-LN。与 @lialin2023relora 和 @zhao2024galore 一致,我们使用基于 LLaMA 的架构进行实验,模型大小为 130M、250M、350M 和 1B 参数,确保架构和训练设置的一致性。
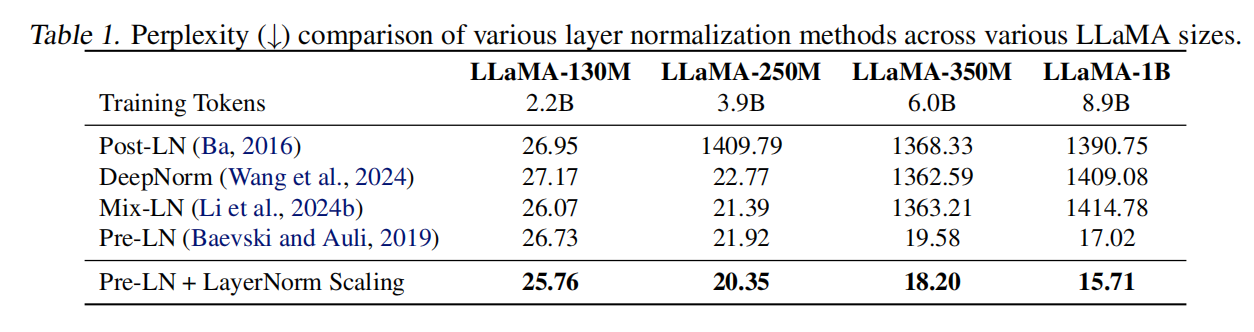
该架构结合了 RMSNorm 和 SwiGLU 激活函数,它们被一致地应用于所有模型大小和标准化方法。对于优化,我们使用 Adam 优化器,并采用特定大小的学习率:对于参数高达 3.5 亿的模型,学习率为 $1 \times 10^{-3}$,对于 10 亿参数的模型,学习率为 $5 \times 10^{-4}$。所有模型共享相同的架构、超参数和训练计划,唯一的区别是标准化方法的选择。与引入一个额外超参数 $\alpha$ 手动设置为 0.25 的 Mix-LN 不同,LayerNorm Scaling 不需要额外的超参数,因此实现起来更简单。表1显示 LayerNorm Scaling 在不同模型大小上始终优于其他标准化方法。虽然 DeepNorm 在较小模型上的表现与 Pre-LN 相当,但它在 LLaMA-1B 等较大架构上表现不佳,显示出损失值的不稳定和发散迹象。类似地,Mix-LN 在较小模型中优于 Pre-LN,但在 LLaMA-350M 中面临收敛问题,表明其对架构设计和超参数调整的敏感性,这是由于引入了 Post-LN。值得注意的是,Mix-LN 最初在 LLaMA-1B 上进行了 50,000 步的评估,而我们的设置将训练扩展到 100,000 步,在 100,000 步时 Mix-LN 无法收敛,突显了其在大规模设置中的不稳定性,这是由 Post-LN 的使用引起的。相比之下,LayerNorm Scaling 解决了 深度学习的诅咒,而不会因其简单性而影响训练稳定性。LayerNorm Scaling 在所有测试的模型大小上都实现了最低的困惑度 (PPL),显示出比现有方法更稳定的性能改进。例如,在 LLaMA-130M 和 LLaMA-1B 上,与 Pre-LN 相比,LayerNorm Scaling 分别降低了 0.97 和 1.31 的困惑度。值得注意的是,LayerNorm Scaling 保持了 LLaMA-1B 的稳定训练动态,而 Mix-LN 在此模型大小上无法收敛。这些发现表明,LayerNorm Scaling 提供了一种稳健且计算效率高的标准化策略,可在不增加额外实现复杂性的情况下增强大规模语言模型训练。
与其他层归一化的比较。 此外,我们使用 LLaMA-130M 进行了比较,以评估层归一化缩放 (LayerNorm Scaling) 相对于最近提出的归一化方法,包括 Admin、Sandwich-LN 和 Group-LN。表2显示 Admin 和 Group-LN 会降低性能。Sandwich-LN 略优于 Pre-LN。Mix-LN 和层归一化缩放 (LayerNorm Scaling) 都比 Pre-LN 有很大改进。然而,Mix-LN 未能将 perplexity (困惑度) 降低到 26 以下,不如层归一化缩放 (LayerNorm Scaling)。

监督式微调
我们认为,LayerNorm 缩放使得大语言模型(LLM)中更深层的网络在监督式微调期间能够更有效地发挥作用,因为它缓解了与深度增加相关的梯度消失问题。与使用 Pre-LN 训练的模型相比,使用 LayerNorm 缩放的更深层网络保持了稳定的输出方差,防止了不受控制的增长,并确保了有效的特征表示。因此,更深层的网络能够更有效地进行特征转换,从而增强表示学习并提高复杂下游任务的泛化能力。
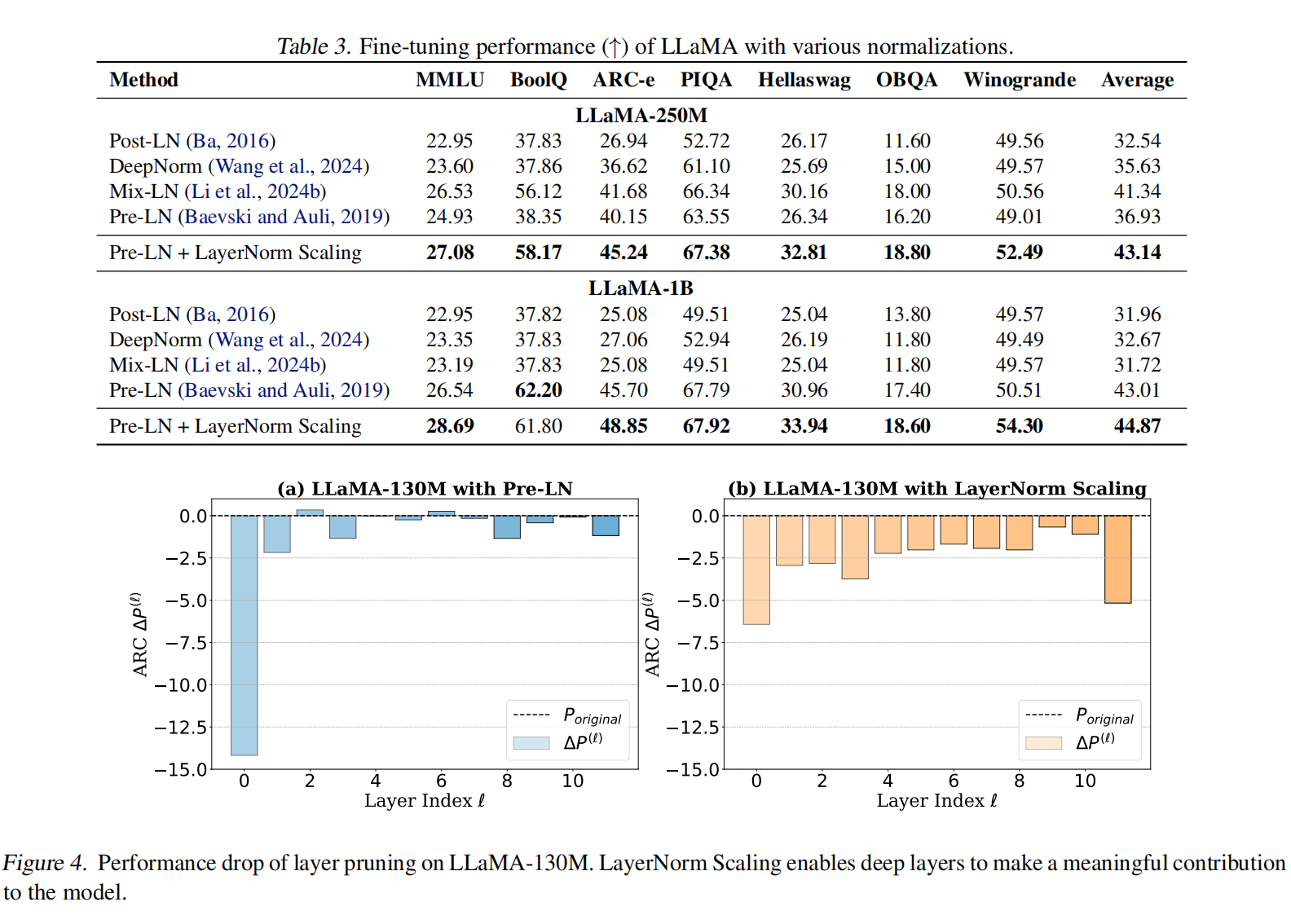
为了验证这一点,我们遵循 @li2024mix 和 @li2024owlore 中描述的微调方法,并应用与预训练相同的优化设置。结果表明 LayerNorm Scaling 在所有评估的数据集中始终优于其他归一化技术。对于 LLaMA-250M 模型,LayerNorm Scaling 将平均性能提高了 1.80%,并且与 Mix-LN 相比,在 ARC-e 上实现了 3.56% 的提升。在 LLaMA-1B 模型中也观察到类似的趋势,其中 LayerNorm Scaling 在八个任务中的七个任务上优于 Pre-LN、Post-LN、Mix-LN 和 DeepNorm,与最佳基线相比平均增益为 1.86%。这些结果证实,LayerNorm Scaling 通过改善梯度流和深层表示质量,实现了更好的微调性能,展示了其在各种下游任务上的鲁棒性和更强的泛化能力。
LayerNorm 缩放减少输出方差
由于 LayerNorm 缩放旨在减少输出方差,我们通过将其与两种缩放方法进行比较来验证这一点:LayerScale 和缩放初始化。LayerScale 使用对角矩阵 diag$(\lambda_1, \ldots, \lambda_d)$ 应用每通道权重,其中每个权重 $\lambda_i$ 初始化为一个较小的值(例如,$\lambda_i = \epsilon$)。与 LayerNorm 缩放不同,LayerScale 自动学习缩放因子,这不一定会引起降尺度效应。缩放初始化通过 $\frac{1}{\sqrt{2L}}$ 将 $W_0$ 和 $W_2$ 的初始化缩放到较小的值,其中 $L$ 是 Transformer 层的总数。由于缩放仅在初始化时应用,我们认为缩放初始化可能无法有效地在整个训练过程中减少方差。我们在图 4中进一步验证了这一点,在那里我们可以看到缩放初始化的输出方差与 Pre-LN 一样大。表4显示了 LLaMA-130M 和 LLaMA-250M 的结果。首先,我们可以看到 LayerScale 会降低性能。虽然缩放初始化比 Pre-LN 略有改进,但它不如 LayerNorm 缩放,并且对于更大的模型,差距变得更大。
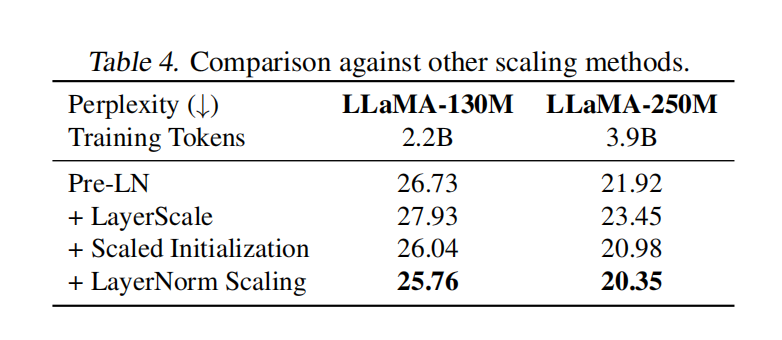
为了评估 LayerNorm Scaling 如何提高深层网络的有效性,我们对 LLaMA-130M 进行了层剪枝实验,系统地移除各个层,并测量 ARC-e 基准上的性能下降($\Delta P^{(\ell)}$)。图4 比较了标准 Pre-LN 和 LayerNorm Scaling 之间的剪枝效果。在 Pre-LN 中,移除深层网络层只会导致极小的性能下降,表明它们在表征学习中的作用有限。相比之下,使用 LayerNorm Scaling,剪枝更深的网络层会导致更明显的性能下降,表明它们现在在学习中发挥着更积极的作用。虽然早期层在两个模型中仍然至关重要,但 LayerNorm Scaling 中的性能下降在各层之间分布更均匀,反映了更平衡的学习过程。这些发现证实,LayerNorm Scaling 通过确保更深层网络有效地参与训练,从而缓解了深度诅咒。