
DeepSeek-R1-Zero最鼓舞人心的结果之一是通过纯强化学习(RL)出现的“顿悟时刻”。在顿悟时刻,模型学习到自我反思等新兴技能,这有助于它进行上下文搜索以解决复杂的推理问题。
在R1-Zero发布后的几天内,几个项目独立地在较小的规模(例如,1B到7B)上“再现”了R1-Zero类训练,并且都观察到了顿悟时刻,这通常伴随着响应长度的增加。我们遵循他们的设置来仔细审查R1-Zero类训练过程,并在本博客中分享以下发现:
💡
a) R1-Zero类训练中可能没有顿悟时刻。 相反,我们发现顿悟时刻(例如自我反思模式)出现在第0个周期,即基础模型。
b) 我们发现基础模型的响应中存在表面自我反思(SSR),在这种情况下,自我反思不一定导致正确的最终答案。
c) 我们通过RL对R1-Zero类训练进行了更深入的观察,发现响应长度增加的现象并不是由于自我反思的出现,而是RL优化良好设计的基于规则的奖励函数的结果。
1. 顿悟时刻出现在第0个周期
1.1 实验设置
基础模型。我们调查了由不同组织开发的广泛的基础模型系列,包括Qwen-2.5, Qwen-2.5-Math, DeepSeek-Math, Rho-Math, 和 Llama-3.x。
提示模板。我们直接使用在R1-Zero和SimpleRL-Zero中应用的模板来提示基础模型:
模板1(与R1-Zero相同)
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: {Question} Assistant:
模板2(与SimpleRL-Zero相同)
<|im_start|>system\nPlease reason step by step, and put your final answer within \boxed{}.<|im_end|>\n<|im_start|>user\n{Question}<|im_end|>\n<|im_start|>assistant
数据 我们从MATH训练数据集中收集了500个问题,均匀覆盖所有五个难度级别和所有科目,以填充上述模板中的{问题}。
生成参数 我们对选定问题的探索参数(温度)进行网格搜索,范围从0.1到1.0。所有实验的Top P设置为0.9。我们为每个问题生成8个响应。
1.2 实证结果
我们首先尝试了所有模型和提示模板(模板1或2)的组合,然后根据它们的指令遵循能力选择每个模型的最佳模板,并在所有实验中固定它。通过仔细调查,我们得出了以下发现:
😲
发现:顿悟时刻出现在第0个周期。我们观察到所有模型(除了Llama-3.x系列)在没有任何后训练的情况下已经表现出自我反思模式。
定性地,我们列出了以下表格中所有观察到的暗示自我反思模式的关键词。请注意,这个列表可能不是详尽无遗的。关键词由人工验证,像*“等待”*这样的词被过滤掉,因为它们的存在可能并不一定表示自我反思,而可能是幻觉的结果。我们注意到不同模型显示出与自我反思相关的不同关键词,我们假设这受到它们的预训练数据的影响。

在图1a中,我们展示了在不同基础模型中引发自我反思行为的问题数量。结果表明,自我反思可以在不同温度下观察到,且在第0个周期的顿悟时刻更频繁地出现在较高温度下。图1b显示了不同自我反思关键词的出现次数。我们可以观察到Qwen2.5系列的基础模型在产生自我反思行为方面最为活跃,这部分解释了大多数开放的R1-Zero复制基于Qwen2.5模型的事实。

图1a. 在不同基础模型中引发自我反思行为的500个MATH问题中的问题数量。

图1b. 在40,000个响应中关键词出现的数量(500个问题×每个问题8个响应×10个温度)。y轴为对数刻度。
在确认顿悟时刻确实在第0个周期出现且没有任何训练后,我们想知道它是否在做我们期望的事情——自我反思以纠正错误推理。因此,我们直接在Qwen2.5-Math-7B基础模型上测试了在SimpleRL-Zero博客中使用的示例问题。令人惊讶的是,我们发现基础模型已经表现出合理的自我修正行为,如图2所示。

图2. 我们直接在Qwen2.5-Math-7B基础模型上测试了在SimpleRL-Zero博客中报告的相同问题,发现顿悟时刻已经出现。
2. 表面自我反思
尽管图2中的示例展示了基础模型通过自我修正的CoT直接解决复杂推理问题的巨大潜力,但我们发现并非所有来自基础模型的自我反思都是有效的,能够导致改进的解决方案。为了便于讨论,我们将其称为表面自我反思,定义如下。
🔍
定义:表面自我反思(SSR)指的是模型响应中缺乏建设性修订或改进的重新评估模式。SSR不一定比没有自我反思的响应产生更好的答案。
2.1 案例研究
为了识别SSR,我们进行了案例研究,并观察到Qwen-2.5-Math-7B基础模型响应中的四种自我反思模式:
行为1:自我反思双重检查并确认正确答案(图3a)。
行为2:自我反思纠正最初错误的想法(图3b & 图2)。
行为3:自我反思引入错误到原本正确的答案中(图3c)。
行为4:重复的自我反思未能产生有效答案(图3d)。
行为3和4是表面自我反思,导致错误的最终答案。

2.2 基础模型容易产生SSR
接下来,我们分析了Qwen2.5-Math-1.5B的正确和错误响应中自我反思关键词的出现情况。如图4所示,大多数自我反思(按频率测量)在不同采样温度下并未导致正确答案,这表明基础模型容易产生表面自我反思。

图4. 正确和错误响应中的自我反思数量。蓝色条表示正确响应中自我反思关键词的总出现次数,而红色条表示错误响应中的总出现次数。
3. 更深入地观察R1-Zero类训练
尽管模型响应长度的突然增加通常被视为R1-Zero类训练中的顿悟时刻,但我们在第1节中的发现表明,这种时刻甚至可以在没有RL训练的情况下发生。这引发了一个自然的问题:为什么模型响应长度遵循一种独特的模式——在早期训练阶段下降,然后在某个时刻激增?
为了调查这一点,我们通过两种方法研究R1-Zero类训练:
(1)在Countdown任务上对R1-Zero进行玩具再现,以分析输出长度动态;
(2)在数学问题上对R1-Zero进行再现,以研究输出长度与自我反思之间的关系。
3.1 长度变化是RL动态的一部分
我们使用支持R1-Zero类训练的oat对Qwen-2.5-3B基础模型在Countdown任务上进行RL调优(如TinyZero所用),使用GRPO。在此任务中,模型被给定三到四个数字,并被要求使用算法操作(+,-,x,÷)构造一个等于目标的方程。这不可避免地要求模型尝试不同的提议,因此需要自我反思行为。
图5的右侧图显示了RL训练过程中奖励和响应长度的动态变化。与TinyZero和SimpleRL-Zero类似,我们观察到奖励持续增加,而长度先下降后激增,这被现有工作归因于顿悟时刻。然而,我们观察到基础模型的响应中已经存在重试模式(第1节),但其中许多是表面的(第2节),因此奖励较低。
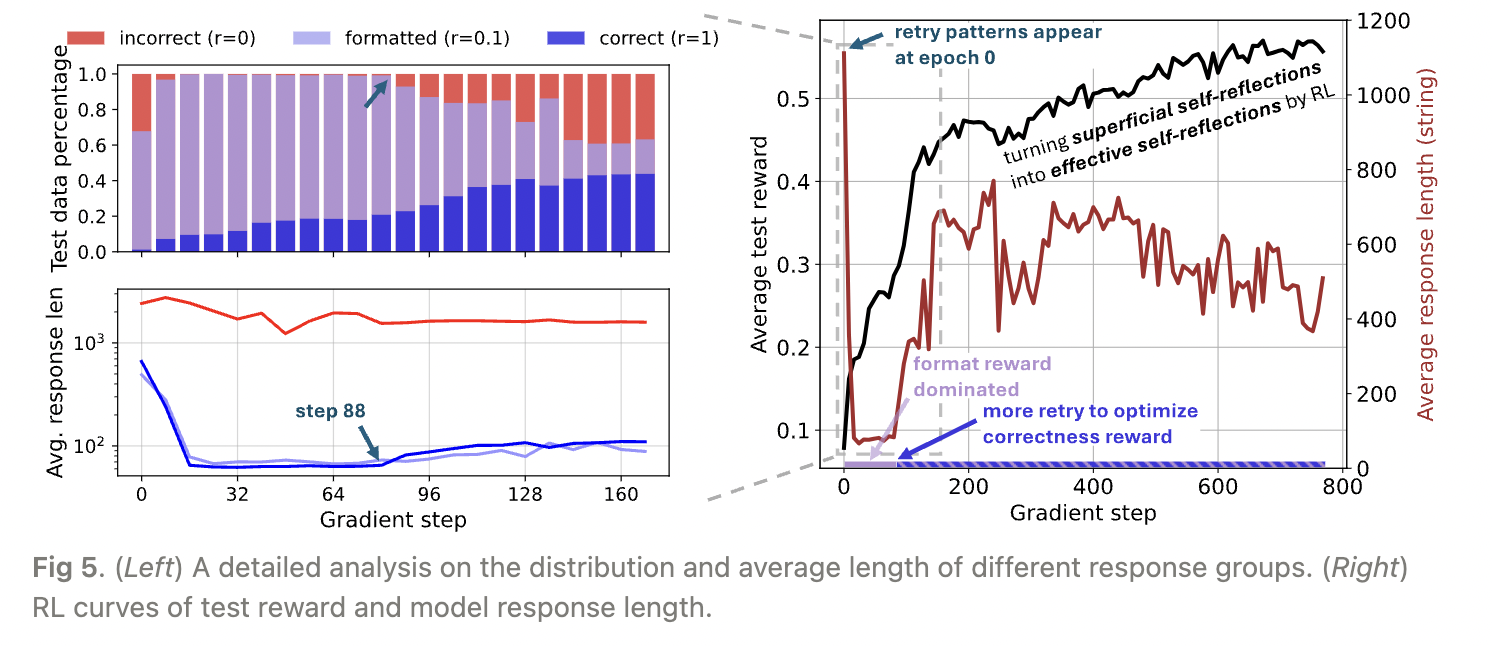
图5. (左) 不同响应组的分布和平均长度的详细分析。(右) 测试奖励和模型响应长度的RL曲线。
放大初始学习阶段,我们分析了基于规则的奖励塑造如何影响RL动态并导致长度变化。在图5的左侧图中,我们根据奖励将模型响应分为三组: $$ r =
\begin{cases}
0, & \text{如果由于格式问题无法解析答案} \
0.1, & \text{如果答案格式正确但不正确} \
1, & \text{如果答案格式正确且正确}
\end{cases} $$ 这种简单的分解揭示了RL动态的一些见解:
第88步之前的训练主要由格式奖励(r=0.1)主导,这更容易通过调整模型在生成token预算内停止并将答案格式化在
在第88步,模型开始向更高的奖励(r=1,表示正确性)攀登,通过输出更多的重试。因此,我们观察到正确响应的长度增加。作为副作用,模型还输出了更多冗长的表面自我反思,导致平均响应长度激增。
整个RL过程是将原本*表面自我反思*转变为*有效自我反思*,以最大化期望奖励,从而提高推理能力。
3.2 长度与自我反思可能没有相关性
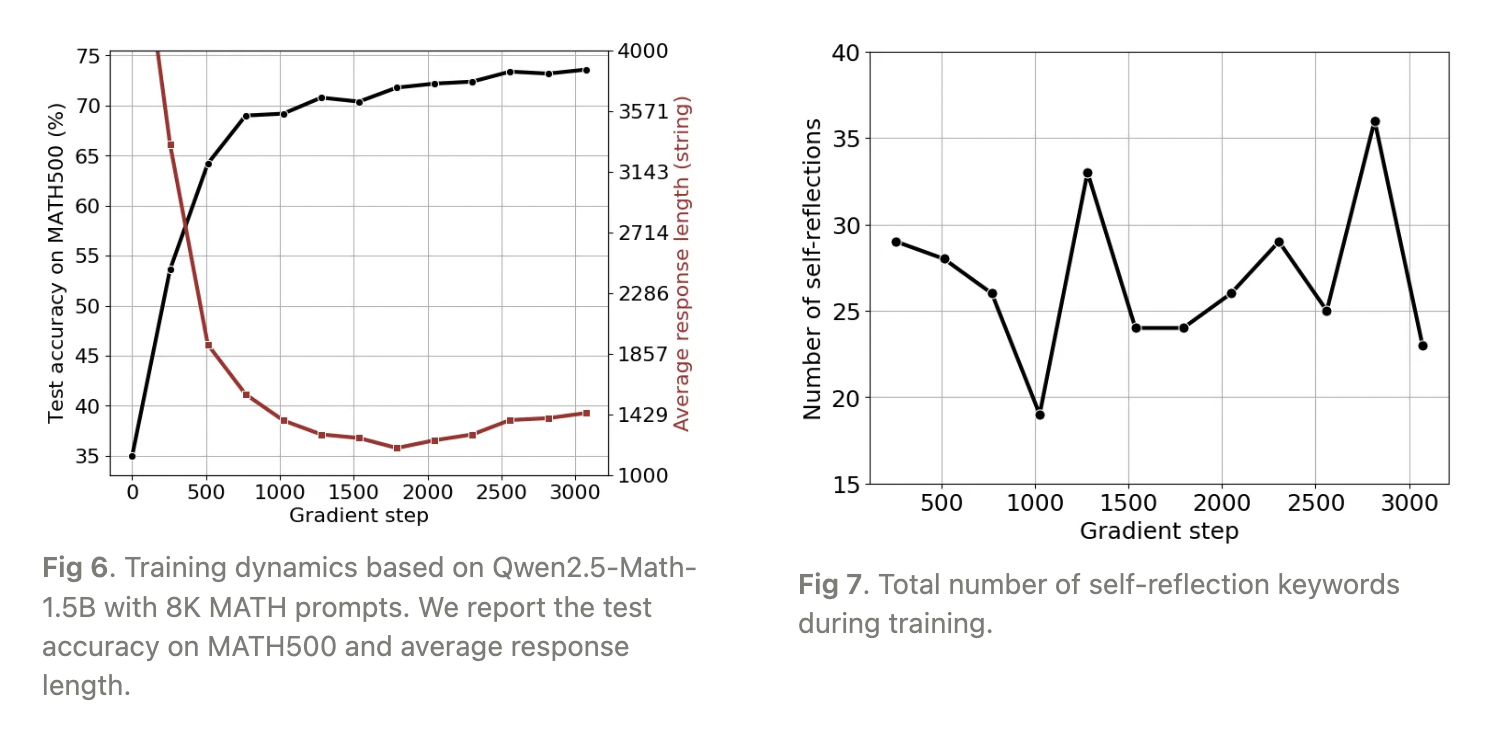
根据SimpleRL-Zero的设置,我们用8K MATH提示训练Qwen2.5-Math-1.5B。在训练开始时,我们观察到输出长度下降,直到大约1,700个梯度步骤,此后长度开始增加(图6)。然而,自我反思关键词的总数与输出长度之间并未表现出单调关系,如图7所示。这表明,仅凭输出长度可能无法可靠地指示模型的自我反思能力。
完整的训练过程大约在我们的单节点服务器上持续14天,目前仍在进行中(进度相当于SimpleRL-Zero中的48个训练步骤)。完成后将进行更详细的分析。
4. 结论与未来工作
本文的初步研究表明,R1-Zero类训练中可能没有传统意义上的“顿悟时刻”。相反,基础模型在第0个周期就表现出自我反思模式,且这些模式并不总是有效的。我们发现,表面自我反思(SSR)在基础模型的响应中普遍存在,且往往未能导致正确答案。
我们的研究结果对未来的研究方向提出了重要的启示。首先,理解自我反思的有效性对于设计更强大的AI模型至关重要。未来的工作可以集中在如何将表面自我反思转化为有效自我反思,以提高模型的推理能力和准确性。
其次,进一步的研究可以探索不同类型的奖励机制如何影响模型的学习过程。通过优化奖励函数,可能会促进更深层次的自我反思,从而提高模型的整体性能。
最后,我们建议在未来的研究中,使用更大规模的模型和更复杂的任务,以验证我们的发现并探索自我反思在不同上下文中的表现。
🔍
未来的研究方向:
研究自我反思的有效性与模型性能之间的关系。
探索不同奖励机制对自我反思的影响。
使用更大规模的模型和复杂任务进行验证。