
看到一个cuda层面实现kernel的库Liger Kernel,速度极快。
==直接一行调用GRPO loss:==
grpo_loss = LigerFusedLinearGRPOLoss()
以下为Liger Kernel库简介:

Liger Kernel 是一个专门为大语言模型(LLM)训练设计的 Triton 内核集合。它可以有效提高多 GPU 训练的吞吐量 20%,并减少 60% 的内存使用。我们已经实现了与 Hugging Face 兼容的 RMSNorm、RoPE、SwiGLU、CrossEntropy、FusedLinearCrossEntropy 等功能,未来还会增加更多。该内核开箱即用,支持 Flash Attention、PyTorch FSDP 和 Microsoft DeepSpeed。
我们还添加了优化的训练后内核,为对齐和蒸馏任务节省高达 80% 的内存。我们支持 DPO、CPO、ORPO、SimPO、JSD 等多种损失函数。
只需一行代码,Liger Kernel 就可以提高 20% 以上的吞吐量,并减少 60% 的内存使用,从而实现更长的上下文长度、更大的批量大小和更大的词汇表。
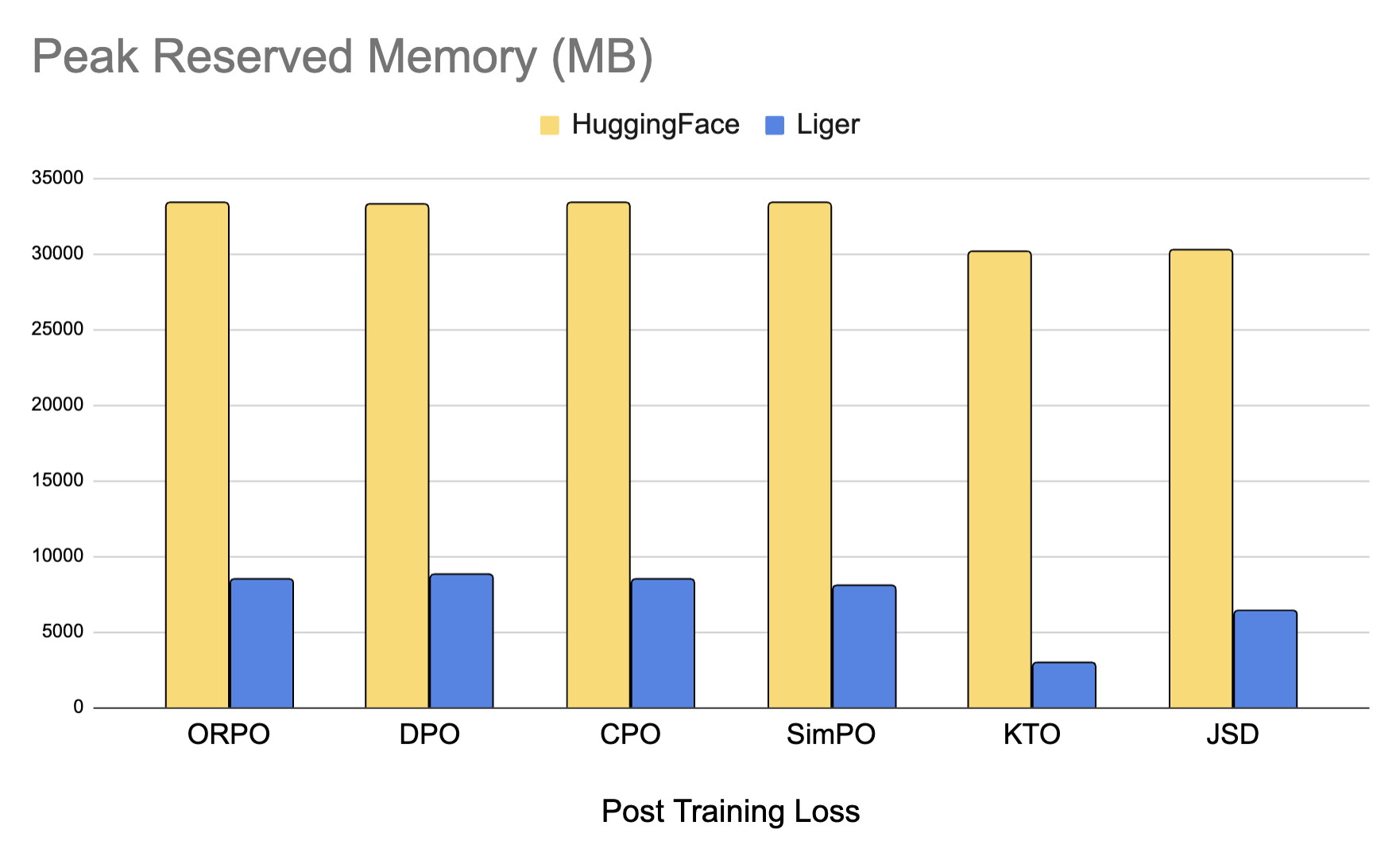
注意:
基准测试条件:LLaMA 3-8B,批量大小 = 8,数据类型 = bf16,优化器 = AdamW,梯度检查点 = True,分布式策略 = FSDP1,使用 8 个 A100 GPU。 Hugging Face 模型在 4K 上下文长度时开始出现内存不足(Out of Memory, OOM),而 Hugging Face + Liger Kernel 可以扩展到 16K。
主要特点:
易于使用:只需用一行代码修补您的 Hugging Face 模型,或使用我们的 Liger Kernel 模块构建您自己的模型。 时间和内存高效:与 Flash-Attn 类似,但适用于 RMSNorm、RoPE、SwiGLU 和 CrossEntropy 等层!通过内核融合、原地替换和分块技术,Liger Kernel 将多 GPU 训练的吞吐量提高 20%,并减少 60% 的内存使用。
精确:计算是精确的——没有近似值!前向和后向传播均通过严格的单元测试实现,并与未使用 Liger Kernel 的训练运行进行收敛测试,以确保准确-性。
轻量级:Liger Kernel 依赖极少,仅需 Torch 和 Triton——无需额外库!告别依赖问题!
支持多 GPU:兼容多 GPU 设置(PyTorch FSDP、DeepSpeed、DDP 等)。
训练框架集成:Axolotl、LLaMa-Factory、SFTTrainer、Hugging Face Trainer、SWIFT。
有兴趣的可以看看他们的论文:发布于2024年10月。
Liger Kernel: 用于大语言模型 (LLM) 训练的高效 Triton 内核
摘要
大规模且高效地训练大语言模型 (LLM) 是一项艰巨的挑战,其主要驱动因素是不断增长的计算需求以及对更高性能的追求。 在这项工作中,我们推出了 Liger-Kernel,这是一套专门为大语言模型 (LLM) 训练而开发的开源 Triton 内核。 通过内核操作融合和输入分块等内核优化技术,与 HuggingFace 的实现相比,我们的内核在常用的大语言模型 (LLM) 训练中,平均吞吐量提高了 20%,并减少了 60% 的 GPU 内存占用。 此外,Liger-Kernel 在设计时充分考虑了模块化、易用性和可适配性,旨在满足普通用户和专业用户的需求。 内置了全面的基准测试和集成测试,以确保在各种计算环境和模型架构下的兼容性、性能、正确性和收敛性。
介绍
扩展大语言模型 (LLM) 训练在很大程度上依赖于计算基础设施的稳定性,并且容易受到效率瓶颈的影响。主机/设备内存管理以及张量运算的延迟-带宽权衡是效率问题的核心。然而,除了算法扩展策略之外,优化的真正潜力在于 GPU 内核级别的操作融合,这可以最大限度地减少内存复制并最大限度地提高并行效率。这些“最后一公里”的内核级优化至关重要,因为这一级别的任何收益都会被 GPU 固有的并行性放大,使其对于提高整体训练性能来说是不可或缺的。尽管分布式训练的硬件和软件可用性最近取得了进展,但优化训练过程仍然是一项高度复杂和专业的任务,这不仅需要对 LLM 算法和硬件架构有深入的了解,还需要大量的时间和资金投入。为了应对这些挑战,我们推出了 Liger-Kernel,这是一个用于 LLM 训练的高效 Triton 内核的开源库。Liger-Kernel 通过高度灵活且用户友好的界面,增强了 LLM 训练的效率和可扩展性。它简化了复杂的张量运算,通过内核融合最大限度地减少了计算开销,并与各种计算环境无缝集成。新手用户只需几行代码即可提高 LLM 训练效率,而高级用户可以使用模块化组件和自适应层配置来定制他们的模型以满足他们的需求。Liger-Kernel 只需要最少的依赖项,即 PyTorch 和 Triton。Liger-Kernel 支持多种分布式框架,例如 PyTorch FSDP、DeepSpeed ZeRO 和 ZeRO++,确保在各种硬件平台上实现广泛的兼容性和性能优化。
预备知识
在 PyTorch 中,Eager 模式执行为模型代码的编写提供了流畅的开发和调试体验。然而,PyTorch 操作的逐步执行会带来额外的计算开销,包括函数调用堆栈、调度以及 CUDA 内核启动延迟。此外,为反向传播而具体化每个中间激活值也会显著增加 GPU 内存的使用量。解决此问题的大部分工作都集中在模型编译和算法操作融合上。最近,越来越多的从业者开始使用 Triton 语言 实现自定义操作融合,以取代模型代码的 PyTorch 原生执行方式。
模型编译器
模型编译器将高级模型描述(例如,torch.nn.Module)转换为优化的底层代码,这些代码可以更有效地执行,尤其是在诸如 GPU 之类的专用硬件上。 此类编译器的示例包括 torch.compile、TVM、XLA 和 nvFuser。 torch.compile 是 PyTorch 2.0 中引入的最新 PyTorch 原生模型编译功能。 它的前端即时 (JIT) 捕获计算图并将 python 级操作转换为中间表示 (IR)。 它的后端对 IR 执行底层优化,并将 IR 转换为 Triton 中用于 GPU 的高性能代码以及带有 OpenMP 的 C++ 用于 CPU。 Apache TVM 为各种硬件平台提供统一的中间表示,旨在弥合高级深度学习框架和各种部署目标之间的差距。 XLA 由 Google 开发,旨在优化基于 TensorFlow 和 JAX 的训练工作流程。 它执行操作融合、布局优化和针对目标硬件量身定制的内核生成。 nvFuser 是 NVIDIA 开发的特定于 PyTorch 的 JIT 编译器,专为 PyTorch 设计。 它尤其能够生成针对特定 GPU 定制的优化 CUDA 代码,从而利用 GPU 架构的功能,例如内存层次结构、并行性和指令级优化。
操作融合的算法视角
Liger-Kernel 设计的基石是操作融合。自定义操作融合的主要目标是缓解高带宽内存 (HBM) 和共享内存 (SRAM) 之间因频繁内存复制而产生的瓶颈。每个流式多处理器 (SM) 需要快速访问数据才能并行执行多个线程,但 HBM 虽然容量大,但速度明显慢于 SRAM。这种不匹配可能导致延迟,处理核心空闲,等待数据从 HBM 传输到更快、更有限的 SRAM。在深度学习模型的上下文中,尤其是那些具有大型矩阵(如 Transformer 中)和大量操作的模型中,这种情况变得更加严重[^1]。操作融合将几个独立的 GPU 操作组合成一个单一的操作,以避免在第 2 节开头提到的逐步执行中每个操作的时间和内存开销。从算法的角度来看,像 FlashAttention 这样的操作融合技术提供了优化算法本身固有的特定计算模式的优势,与模型编译器执行的更广泛、更通用的优化相比,能够实现更精确和定制的性能改进。例如,FlashAttention 通过利用 GPU 内存层次结构来优化 Transformer 模型中的注意力计算,从而将内存复杂度从二次方降低到线性。它将注意力计算分成更小的块,这些块适合 GPU 片上 SRAM,避免了物化完整的注意力矩阵和对较慢的 GPU 高带宽内存 (HBM) 的冗余内存访问。
FlashAttention-2 通过减少寄存器溢出和增强跨注意力头的并行性,进一步改进了这种方法。这些创新共同为注意力计算带来了显著的加速和内存节省,特别是对于长序列长度。
使用 Triton 进行自定义操作融合
OpenAI 的 Triton 是一种用于高性能 GPU 内核的编程语言和编译器,它具有类似 Python 的语法(比 CUDA 更简单),从而更容易优化深度学习操作,而无需低级 GPU 编程的复杂性。它的 JIT 编译特性还允许使用它的库和工具更加轻量级和可移植。这些特性提高了 Triton 在 GPU 上为 PyTorch 编写高性能内核的受欢迎程度。Meta 的 xFormers 托管了用 Triton 和 CUDA 实现的可互操作且优化的 Transformer 构建块,并支持各种注意力机制。FlashAttention 仓库[^2] 除了托管 FlashAttention 算法的 CUDA 实现外,还包括 Triton 和 torch.script 中的其他 Transformer 构建块实现(例如,层归一化、线性层和平方 ReLU 激活的融合实现等)。Unsloth AI 的 Unsloth[^3] 在 Triton 中重新实现了流行的 LLM 和 LoRA 适配器层,以支持高效的 LLM 微调和快速推理。与 FlashAttention 中的分块设计类似,EfficientCrossEntropy[^4] 将线性投影与 CrossEntropy 损失融合,并以分块方式计算损失,以避免具体化整个 logits 张量。Liger-Kernel 从上述一些项目中汲取灵感并利用代码作为参考。
API 设计
易用性对于社区采纳至关重要,Liger 内核的设计宗旨是易于访问和使用。Liger 的 API 设计背后的指导原则是在尽可能不破坏用户现有代码库的前提下,为各种级别的自定义提供所需的灵活性。根据所需的自定义级别,有以下几种应用 Liger 内核的方法:
- 使用 AutoLigerKernelForCausalLM: 利用 Liger 内核最简单的方法是通过
AutoLigerKernelForCausalLM类。此方法不需要导入特定于模型的修补 API。如果支持该模型类型,Liger 将自动修补建模代码。
from liger_kernel.transformers import AutoLigerKernelForCausalLM
model = AutoLigerKernelForCausalLM.from_pretrained("path/to/some/model")
- 应用特定于模型的修补 API: 为了对模型代码进行细粒度控制,用户可以利用
Liger-Kernel提供的特定于模型的修补 API。这些 API 用途广泛,可以与因果语言模型之外的各种模型架构一起使用,例如序列分类。
from liger_kernel.transformers import apply_liger_kernel_to_llama
apply_liger_kernel_to_llama()
model = AutoModelForSequenceClassification.from_pretrained("/path/to/some/model")
- 组合自定义模型: 高级用户可以利用单独的 Liger 内核(根据需要)来创建他们自己的自定义模型。例如,下面类似 PyTorch 的代码演示了如何创建一个
LigerTransformer模块,该模块利用LigerLayerNorm来实现层归一化功能,并利用LigerCrossEntropyLoss来创建损失函数。
import torch
from liger_kernel.transformers import LigerLayerNorm, LigerCrossEntropyLoss
class LigerTransformer(torch.nn.Module):
def __init__(self, hidden_dim, *args, **kwargs):
super().__init__()
# create attn, mlp blocks or any custom operation
...
# use Triton-optimized LigerLayerNorm
self.layer_norm = LigerLayerNorm(hidden_dim)
def forward(self, x):
# forward pass of the model
...
# use the Triton-optimized LigerCrossEntropyLoss
loss_fn = LigerCrossEntropyLoss()
这些灵活的选项确保 Liger 内核可以轻松集成到各种工作流程中,从而促进 LLM 的高效训练和部署。
核函数
在整个讨论中,向量[^5]和矩阵分别用粗体小写字母和大写字母表示,例如,$x \in \mathbb{R}^n$ 和 $W\in \mathbb{R}^{m \times n}$。全一向量表示为 ${1}_n \in \mathbb{R}^n$。函数以元素方式应用于变量,即 $f({x})_i = f(x_i)$。我们使用 $\odot$ 表示张量之间的元素乘积,使用 $^\top$ 表示矩阵转置。
在我们的核函数实现中,输入和输出张量都被重塑为形状为 $(B \times T, H)$ 的二维矩阵,其中 $B$ 是批次大小,$T$ 是序列长度,$H$ 是隐藏维度。
在每个核函数中,Triton 并行化输入[^6]的每一行的操作。因此,我们关注于给定一行输入(表示为 ${x}$)和相应的输出(表示为 ${y}$)的数学运算。在反向传播过程中,给定一个损失函数 $\mathcal{L}$,我们使用 $\nabla_{{y}}\mathcal{L}$ 来表示从 $\mathcal{L}$ 反向传播到 ${y}$ 的梯度。
RMSNorm
$$ \begin{aligned} {y} = \hat{{x}} \odot {\gamma}, \hspace{20pt} \hat{{x}} = \frac{{x}}{\textrm{RMS}({x})}, \end{aligned} $$$$ \begin{aligned} \begin{split} \nabla_{{x}}\mathcal{L} &= \frac{1}{\textrm{RMS}({x})}\left(\nabla_{{y}}\mathcal{L} \odot {\gamma} - \underbrace{\left[\hat{{x}}^\top(\nabla_{{y}}\mathcal{L} \odot {\gamma})/n \right]}_{\textrm{a numerical value}} \hat{{x}}\right), \\ \nabla_{{\gamma}}\mathcal{L} &= \nabla_{{y}}\mathcal{L} \odot \hat{{x}}. \end{split} \end{aligned} $$由于相同的 ${{\gamma}}$ 应用于同一批次中的所有输入向量 ${{x}}$,因此需要将梯度加总。
LayerNorm.
$$ \begin{aligned} {y} = \tilde{{x}} \odot {\gamma} + {\beta}, \hspace{20pt} \tilde{{x}} = \frac{{x} - \bar{{x}}} {\textrm{RMS}({x} - \bar{{x}})}, \end{aligned} $$$$ \begin{aligned} \begin{split} \nabla_{{x}}\mathcal{L} &= \frac{1}{\textrm{RMS}({x} - \bar{{x}})}\left(\nabla_{{y}}\mathcal{L} \odot {\gamma} - \underbrace{\left[\tilde{{x}}^\top(\nabla_{{y}}\mathcal{L} \odot {\gamma})/n \right]}_{\textrm{a numerical value}} \tilde{{x}} - \frac{1}{n} \left[(\nabla_{{y}}\mathcal{L})^\top {\gamma} \right] {1} \right), \\ \nabla_{{\gamma}}\mathcal{L} &= \nabla_{{y}}\mathcal{L} \odot \tilde{{x}} \\ \nabla_{{\beta}}\mathcal{L} &= \nabla_{{y}}\mathcal{L}. \end{split} \end{aligned} $$由于相同的 ${{\gamma}}$ 和 ${{\beta}}$ 应用于批次中的所有输入向量 ${{x}}$,因此需要将梯度加总[^8]。
RoPE.
$$ \begin{aligned} {y} = {R}_{\Theta, m}^d {x}. \end{aligned} $$$$\begin{aligned} {R}_{\Theta, m}^d = \begin{pmatrix} \cos m \theta_1 & 0 & \dots & 0 & -\sin m \theta_1 & 0 & \dots & 0 \\ 0 & \cos m \theta_2 & \dots & 0 & 0 & -\sin m \theta_2 & \dots & 0 \\ 0 & 0 & \dots & 0 & 0 & 0 & \dots & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \dots & \cos m \theta_{d/2} & 0 & 0 & \dots & -\sin m \theta_{d/2} \\ \sin m \theta_1 & 0 & \dots & 0 & \cos m \theta_1 & 0 & \dots & 0 \\ 0 & \sin m \theta_2 & \dots & 0 & 0 & \cos m \theta_2 & \dots & 0 \\ 0 & 0 & \dots & 0 & 0 & 0 & \dots & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \dots & \sin m \theta_{d/2} & 0 & 0 & \dots & \cos m \theta_{d/2} \end{pmatrix} \end{aligned}$$$$ \begin{aligned} \nabla_{{x}}\mathcal{L} = ({R}_{\Theta, m}^d)^\top \nabla_{{y}}\mathcal{L}. \end{aligned} $$在实现中,由于${R}_{\Theta, m}^d$的稀疏性,我们采用了文献中的高效计算方法。
SwiGLU.
$$ \begin{aligned} \begin{split} {y} &=\text{Swish}_{\beta=1}({W} {x}+{b})\odot({V} {x}+{c}) \\ &=\text{SiLU}({W} {x}+{b})\odot({V} {x}+{c}), \end{split} \end{aligned} $$$$ \begin{aligned} {y}({x_1}, {x_2}) =\text{SiLU}({x_1})\odot {x_2}. \end{aligned} $$$$ \begin{aligned} & \nabla_{\boldsymbol{x}_1} \mathcal{L}=\nabla_{\boldsymbol{y}} \mathcal{L} \odot\left[\sigma\left(\boldsymbol{x}_{\mathbf{1}}\right)+\operatorname{SiLU}\left(\boldsymbol{x}_{\mathbf{1}}\right) \odot\left(1-\sigma\left(\boldsymbol{x}_{\mathbf{1}}\right)\right)\right] \odot \boldsymbol{x}_{\mathbf{2}}, \\ & \nabla_{\boldsymbol{x}_{\mathbf{2}}} \mathcal{L}=\nabla_{\boldsymbol{y}} \mathcal{L} \odot \operatorname{SiLU}\left(\boldsymbol{x}_{\mathbf{1}}\right) . \end{aligned} $$第一个公式计算了损失函数 $\mathcal{L}$ 关于输入 ${x_1}$ 的梯度,它等于损失函数 $\mathcal{L}$ 关于输出 ${y}$ 的梯度与一个包含sigmoid函数 $\sigma({x_1})$ 和SiLU函数 $\text{SiLU}({x_1})$ 的表达式的点乘,再与 ${x_2}$ 点乘。
第二个公式计算了损失函数 $\mathcal{L}$ 关于输入 ${x_2}$ 的梯度,它等于损失函数 $\mathcal{L}$ 关于输出 ${y}$ 的梯度与SiLU函数 $\text{SiLU}({x_1})$ 的点乘。
GeGLU.
$$ \begin{aligned} {y} =\text{GELU}({W} x+{b})\odot({V} x+{c}), \end{aligned} $$$$ \begin{aligned} \text{GELU}(z) \approx 0.5z\left(1+\tanh\left[\sqrt{2/\pi}\left(z+ 0.044715 z^3\right)\right]\right). \end{aligned} $$$$ \begin{aligned} {y}({x_1}, {x_2}) =\text{GELU}({x_1})\odot {x_2}. \end{aligned} $$$$ \begin{aligned} \begin{split} \nabla_{{x_1}}\mathcal{L} &= \nabla_{{y}}\mathcal{L} \odot \nabla_{{x_1}}\text{GELU}({x_1}) \odot {x_2}, \\ \nabla_{{x_2}}\mathcal{L} &= \nabla_{{y}}\mathcal{L} \odot \text{GELU}({x_1}), \end{split} \end{aligned} $$$$ \begin{aligned} \begin{split} \nabla_{{x_1}}\text{GELU}({x_1}) \approx \, & 0.5 \odot \left(1+\tanh\left[\sqrt{2/\pi}\left({x_1}+ 0.044715 {x_1}^3\right)\right]\right) \\ \end{split} \end{aligned} $$$$ \begin{aligned} & + \sqrt{1/(2\pi)} {x_1} \odot \left(1-\tanh^2\left[\sqrt{2/\pi}\left({x_1}+ 0.044715 {x_1}^3\right)\right]\right) \odot\left(1+0.134145{x_1}^2\right). \end{aligned} $$交叉熵 (CE).
$$ \begin{aligned} {y} =\textrm{softmax}({x}), \end{aligned} $$$$ \begin{aligned} \nabla_{{x}}\mathcal{L} = {y} - {t}. \end{aligned} $$此外,我们还采用安全的 $\log$ 运算来避免数值不稳定性。
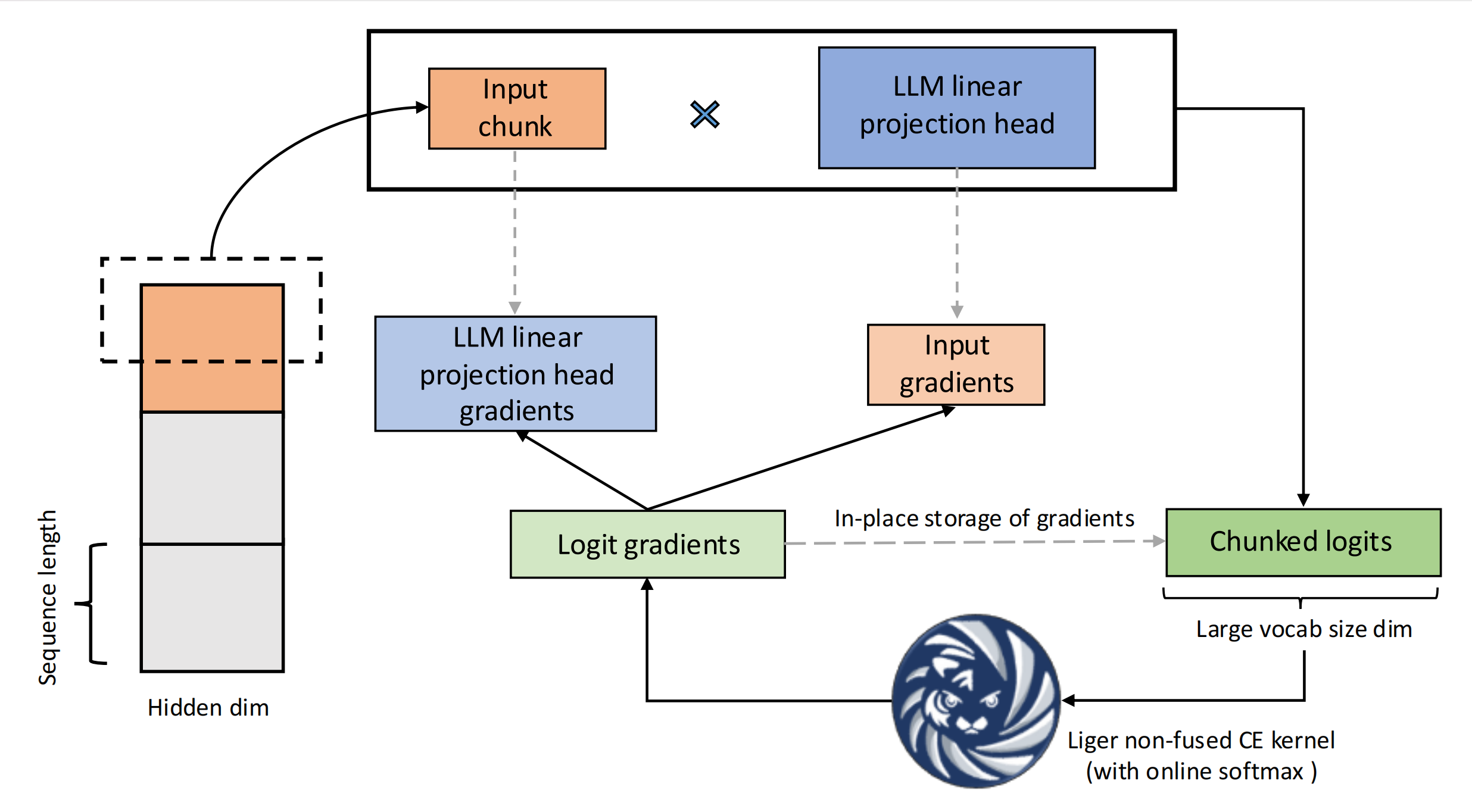
融合线性交叉熵 (FLCE).
$$ \begin{aligned} \begin{split} &{x}={W}^\top{h}, \\ &\nabla_{{h}}\mathcal{L} = {W}\nabla_{{x}}\mathcal{L}, \\ &\nabla_{{W}}\mathcal{L} = {h} (\nabla_{{x}}\mathcal{L})^\top, \end{split} \end{aligned} $$其中 ${W}\in \mathbb{R}^{H \times V}$ 表示给定词汇量大小 $V$ 的线性投影头权重。${h} \in \mathbb{R}^{H}$ 表示扁平化隐藏状态矩阵 ${H} \in \mathbb{R}^{BT \times H }$ 的单行。单行可以被视为分块大小等于 1 的特殊情况。${x}$ 表示从 ${h}$ 投影得到的 logits 值,对于它,我们已经基于 \[CE-backward\]{reference-type=“eqref” reference=“CE-backward”} 推导出了它的梯度。由于相同的权重 ${W}$ 被用于投影所有分块,它的最终梯度需要被加总为 $\nabla_{{W}}\mathcal{L} = \sum_{{h}} {h} (\nabla_{{x}}\mathcal{L})^\top$。通常,我们可以受益于最后一层投影的计算密集型行为,通过对张量大小进行精细的分块,可以有效地压缩分块矩阵乘法的开销,以保持较高的 GPU 利用率和饱和的运算时间。在实践中,我们将分块大小设置为 $2^{\lceil\log_2{\lceil\frac{BT}{\lceil V/H \rceil}\rceil}\rceil}$,其直觉是选择接近隐藏维度大小的分块大小,以平衡内存分配和处理速度之间的权衡。
备注。
我们额外地使用 $\frac{\textrm{chunk size}}{B\times T}$ 的比例来缩放分块输入的梯度和投影层权重。形式上,当在 CrossEntropy 损失计算期间采用均值缩减时,梯度是针对特定输入块计算的,并且没有对整个输入序列进行归一化。这种额外的缩放因子解决了这种近似问题。
测试最佳实践
测试是我们内核开发过程的基石。精确性是不容妥协的,因为即使是微小的偏差也可能产生深远的影响。通过严格的研究和实践经验,我们将我们的方法提炼成一套最佳实践,以确保我们的内核满足最高的精确性和可靠性标准。
正确性
确保内核精度至关重要,因为任何与原始实现的偏差都可能影响模型收敛或导致严重错误。 为了实现这一点,我们准备了一个纯 PyTorch 实现(例如,HuggingFace 提供的实现)进行比较,并使用各种输入形状和数据类型测试该实现。 我们包括常规形状(例如,2 的幂),并测试不规则形状以确保正确处理边缘情况。 我们设置适当的绝对和相对容差水平:对于 fp32,使用 atol = $10^{-7}$ 和 rtol = $10^{-5}$;对于 bf16,使用 atol = $10^{-3}$ 和 rtol = $10^{-2}$ [^12]。
此外,大型张量维度可能导致意外的内存访问问题。 默认情况下,内核中的 program_id 存储为 int32。 如果 program_id * Y_stride > 2,147,483,647,则该值变为负数,从而导致非法内存访问。 通过在处理大型维度时显式地将其转换为 int64,可以避免此类溢出和不正确的内存寻址错误。
性能
我们通过在速度和内存使用这两个关键维度上进行测试,来确保在Triton中重新实现的内核是合理的(与基线版本相比)。
对于测试中的输入形状,我们使用来自训练过程的实际维度/超参数,例如批大小为$4$,隐藏维度为$2048$,以及可变序列长度。 这种方法确保了测试结果反映了在各种模型的生产训练中预期的收益。
收敛测试
在实际训练环境中,张量的连续性、形状和数据类型可能与单元测试条件不同。为了证明我们计算收益的有效性,我们以较小的规模模拟这种真实世界的场景,并验证训练结束时 logits、权重和损失的准确性。
连续性
由于 Triton 直接在物理内存上操作,非连续张量(即元素并非按顺序排列)可能导致非法内存访问或产生不正确的输出。 例如,在部署我们的 RoPE 内核进行生产训练时,我们观察到显著的损失发散现象,这是因为来自 scaled_dot_product_attention 函数的导数没有以连续的方式存储。 为了避免此类问题,最佳实践是在将张量传递给内核之前,确保它们是连续的。
集成
Liger 已经成功地与机器学习社区中几个流行的训练框架集成,包括 Hugging Face transformers 的 Trainer 类[^13]、Hugging Face TRL 的 SFTTrainer 类[^14]、Axolotl[^15] 和 LLaMA-Factory[^16]。这些集成展示了 Liger API 的灵活性和易用性,使开发人员能够以最少的代码更改来利用其优化功能。通常只需要一个简单的标志就可以使用 Liger 内核修补模型代码。例如:
from trl import SFTConfig, SFTTrainer
trainer = SFTTrainer(
"meta-llama/Meta-Llama-3-8B",
train_dataset=dataset,
# Setting `use_liger=True' will load the model using AutoLigerKernelForCausalLM
args=SFTConfig(..., use_liger=True),
)
trainer.train()
数值实验
本节介绍使用 Liger-Kernel v0.2.1[^17] 进行的内核级别和端到端大语言模型 (LLM) 训练基准测试。
内核基准测试
我们针对各种设置单独对内核进行基准测试,并使用 Liger 展示在速度和内存消耗方面的改进。
设置。
所有基准测试均在单个 NVIDIA A100 GPU (80 GB) 上运行。CrossEntropy 内核在词汇量集合 $\{ 40960, 81920, 122880, 163840 \}$ 上进行基准测试。GeGLU 和 SwiGLU 内核在不同的序列长度上进行基准测试,而 RMSNorm、LayerNorm 和 RoPE 内核则在不同的隐藏维度上进行基准测试。序列长度和隐藏维度的大小均从 $\{ 4096, 8192, 12288, 16384 \}$ 中选择。所有基准测试重复 $10$ 次,以绘制中值速度和内存,以及 $[0.2, 0.8]$ 分位数作为下限和上限。
图不展示了,直接看文字结果。
与基线实现相比,所有 Liger-kernel 实现要么执行速度更快,要么消耗更少的内存,要么同时提供这两种优势。 在 CrossEntropy 内核的情况下,在线 softmax 计算以及内核输入就地替换为其梯度,导致大约 $3\times$ 更快的执行速度,并消耗大约 $5\times$ 更少的内存,词表大小为 $163840$。 对于 GeGLU 和 SwiGLU,我们在速度方面与基线保持一致,并通过在反向传播期间重新计算 SiLU$(\cdot)$ 和 GELU$(\cdot)$ 输出,将峰值内存消耗降低约 $1.6\times$(当序列长度为 $16384$ 时)。 RMSNorm 实现将归一化和缩放操作融合到单个 triton 内核中,并缓存均方根值以供反向传播中使用。 这避免了重复的数据传输和浮点运算,且内存开销最小。 ,对于隐藏维度为 $16384$ 的情况,执行时间减少约 $7\times$,峰值内存消耗减少约 $3\times$。 LayerNorm 内核也采用了类似的逆均方根缓存方法,从而使执行时间减少约 $30\%$,且内存开销最小。 最后,对于 RoPE 内核,我们采用扁平化的 1D 张量来表示旋转矩阵,并利用 ${R}_{\Theta, m}^d$ 中的重复块来显着减少延迟随隐藏维度大小增加而增长的情况。 特别是,对于大小为 $16384$ 的隐藏层,我们实现了大约 $8\times$ 的加速,同时内存消耗降低了大约 $3\times$。
设置。
对于端到端训练实验,我们使用 $4$ 个 NVIDIA A100 GPU(每个 $80$ GB)在 Alpaca 数据集上微调大语言模型(LLaMA 3-8B、Qwen2、Gemma、Mistral 和 Phi3)。我们改变批量大小,将精度设置为 bfloat16,并使用带有余弦学习率调度器的 AdamW 优化器。训练的序列长度设置为 $512$ 个 Token。吞吐量和 GPU 内存使用率指标在 $20$ 个训练步骤后收集,标准误差从 $5$ 次重复运行中测量。基准测试脚本可以在我们的 GitHub 仓库[^18]中找到。
性能对比
在批量大小为 $64$ 时,LLaMA 3-8B 的吞吐量提高了 42.8%,同时 GPU 内存使用量减少了 54.8%。这使得可以在较小的 GPU 上进行训练,或者以较低的资源消耗使用更大的批量大小和更长的序列长度。同样,在批量大小为 $48$ 时,我们的内核将 Qwen2 的吞吐量提高了 25.5%,同时 GPU 内存使用量减少了 56.8%。对于 Gemma,在批量大小为 $48$ 时,吞吐量提高了 11.9%,内存使用量减少了 51.8%。Mistral 在批量大小为 $128$ 时,吞吐量提高了 27%,GPU 内存使用量下降了 21%。最后,Phi3 在批量大小为 $128$ 时,吞吐量提高了 17%,同时内存使用量减少了 13%。总的来说,结果突出了几个值得注意的用例。LLaMA 3-8B 的卓越改进使其成为 GPU 内存是瓶颈的资源受限环境的理想选择。此外,Qwen2 强大的内存减少能力使其非常适合涉及大型数据集或延长训练持续时间的任务。Mistral 的高吞吐量增益使其有利于需要大批量大小的工作负载。
结论
Liger Kernel 提供了优化的 Triton 内核,通过用户友好的 API、与流行框架的无缝集成以及对性能的承诺,提高了训练效率。我们的目标是使 Liger Kernel 成为领先的用于大语言模型 (LLM) 训练的开源 Triton 内核库。我们旨在通过以下方式实现这一目标:
- 易用性: 提供直观的 API、广泛的模型支持和广泛的硬件兼容性
- 性能至上: 最大化计算效率并确保准确性。
- 生态系统参与: 通过活动和与行业领导者的合作,建立强大的社区,同时培养对贡献者的认可和品牌塑造。
- 卓越运营: 确保稳定的 CI、严格的测试协议和活跃的社区。
凭借这些承诺,Liger-Kernel 有望成为高效且可扩展的大语言模型 (LLM) 训练的首选,从而推动深度学习社区内的创新和采用。虽然目前的工作主要集中在训练上,但相同的技术可以无缝地适应于优化模型推理。