摘要
test-time scaling 利用额外的测试时计算来提高性能。最近,OpenAI 的 o1 模型展示了这种能力,但没有公开分享其方法,这导致了许多复制尝试。
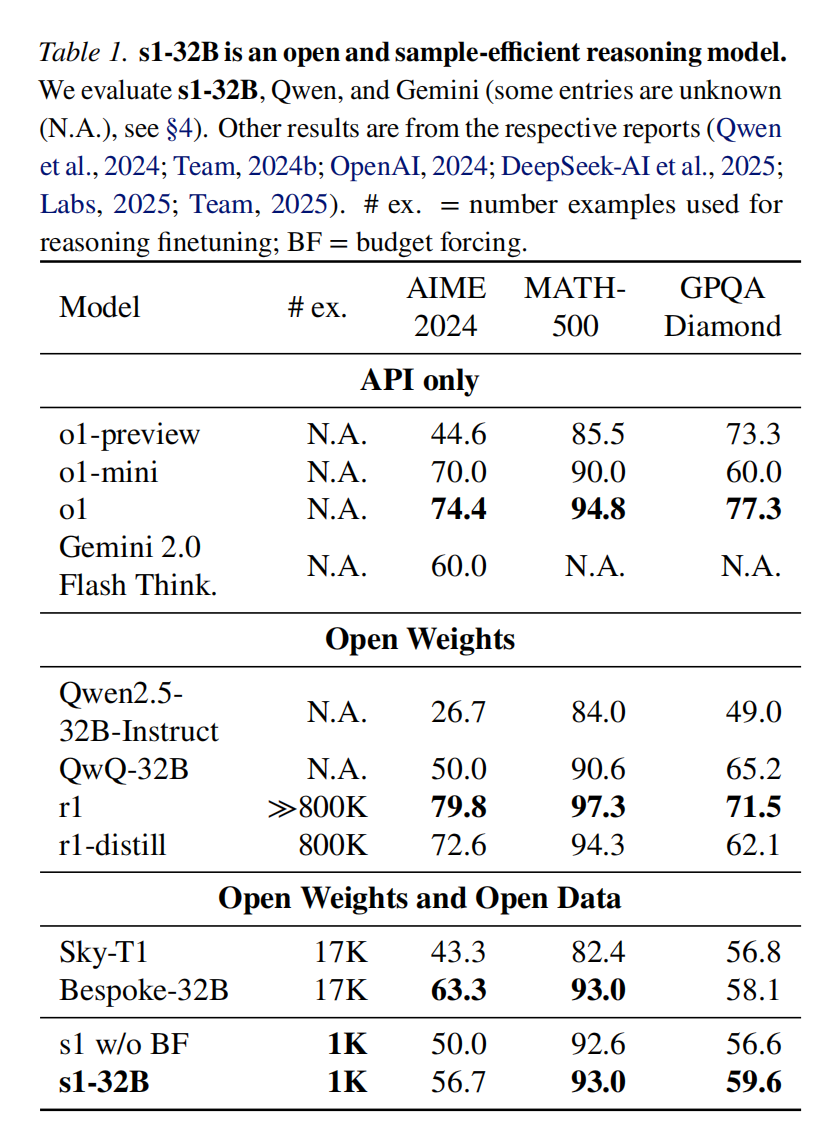
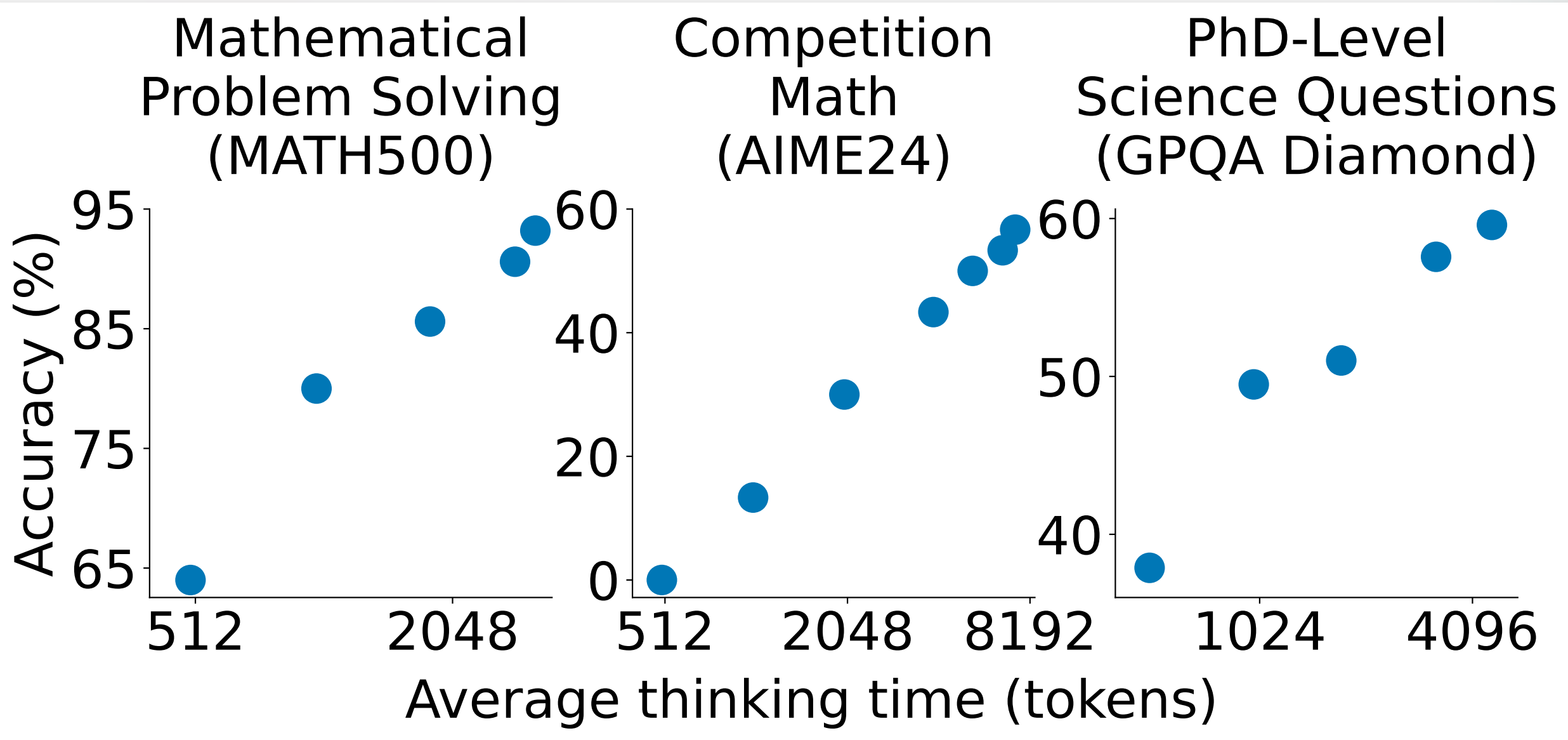
我们寻求实现测试时缩放和强大推理性能的最简单方法。首先,我们策划了一个==小型数据集 s1K==,其中包含 1000 个问题,并配有推理过程的轨迹,这些轨迹基于我们通过消融实验验证的三个标准:难度、多样性和质量。其次,我们开发了==预算强制方法来控制测试时计算,具体做法是强制终止模型的思考过程,或者在模型尝试结束时通过多次附加“等待”来延长其思考过程。这可以引导模型仔细检查其答案,通常会修正不正确的推理步骤==。在对 s1K 上的 Qwen2.5-32B-Instruct 大语言模型进行监督微调,并为其配备预算强制后,我们的模型 s1-32B 在竞赛数学问题上的表现比 o1-preview 高出 27%(MATH 和 AIME24)。此外,使用预算强制缩放 s1-32B 允许在没有测试时干预的情况下将其性能外推:在 AIME24 上从 50% 提高到 57%。
引言
DeepSeek R1 成功地复制了 o1 级别的性能,也采用了通过数百万样本和多个训练阶段的强化学习。然而,尽管有大量的 o1 复制尝试,但没有一个公开复制了清晰的测试时缩放行为。
因此,我们提出问题:==实现test-time scaling和强大的推理性能的最简单方法是什么?==
我们证明,仅使用1000个样本进行下一个 Token 预测训练,并通过一种简单的测试时技术(我们称之为预算强制)来控制思考时长,可以得到一个强大的推理模型,其性能随着测试时计算量的增加而扩展。具体来说,我们构建了 s1K,它包含1000个精心策划的问题,这些问题与从 Gemini Thinking Experimental 中提取的推理轨迹和答案配对。我们对一个现成的预训练模型在我们的少量数据集上进行了监督微调(SFT),仅需在 16 个 H100 GPU 上训练 26 分钟。训练后,我们使用预算强制来控制模型在测试时花费的计算量:
(I) 如果模型生成的思考 Token 超过了期望的限制,我们将通过附加一个思考结束 Token 分隔符来强制结束思考过程。以这种方式结束思考会使模型过渡到生成答案。
(II) 如果我们希望模型在问题上花费更多的测试时计算量,我们会抑制思考结束 Token 分隔符的生成,而是将“等待”附加到模型当前的推理轨迹中,以鼓励更多的探索。
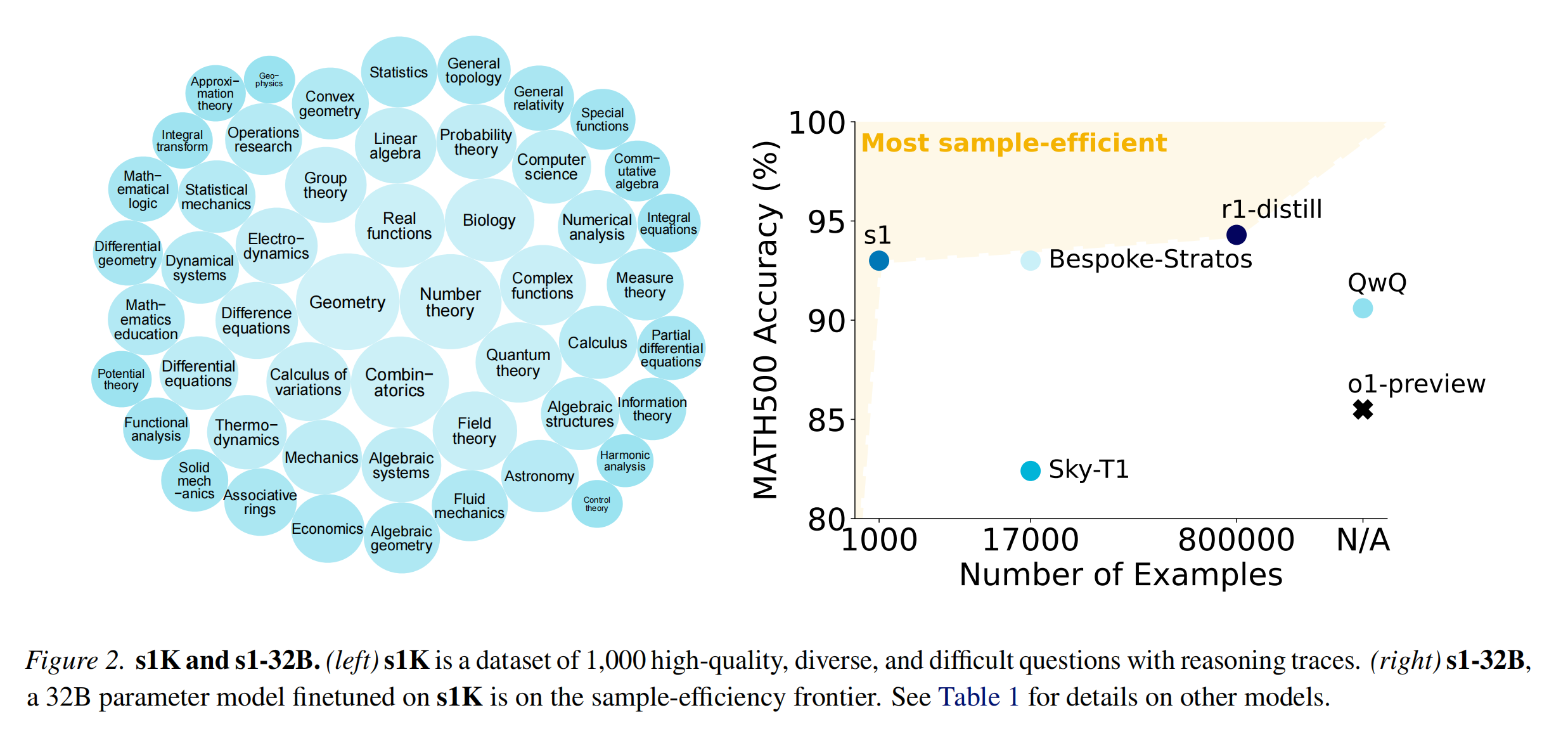
有了这个简单的配方——在 1000 个样本上进行 SFT 和测试时预算强制——我们的模型 s1-32B 表现出测试时扩展。此外,s1-32B 是最节省样本的推理模型,并且优于像 OpenAI 的 o1-preview 这样的闭源模型 。我们进行了广泛的消融实验,目标是 (a) 我们选择的 1000 个 (1K) 推理样本和 (b) 我们的测试时扩展。对于 (a),我们发现将难度、多样性和质量度量共同纳入我们的选择算法非常重要。随机选择、选择具有最长推理轨迹的样本或仅选择最大多样性的样本都会导致性能显著下降(在 AIME24 上平均下降约 ->30%)。在我们包含 59K 个示例的完整数据池(s1K 的超集)上进行训练,并不能比我们的 1K 选择提供实质性的提升。这突出了仔细数据选择的重要性,并呼应了先前关于指令微调的发现。对于 (b),我们为测试时扩展方法定义了期望,以比较不同的方法。预算强制导致最佳的扩展,因为它具有完美的控制性,并且具有清晰的正斜率,从而带来强大的性能。
用于创建 s1K 的推理数据整理
初始收集的 59K 样本
我们遵循三个指导原则,从 16 个不同的来源收集了最初的 59,029 个问题。
质量:数据集应具有高质量;我们始终检查样本并忽略例如格式较差的数据集;
难度:数据集应具有挑战性,需要大量的推理工作;
多样性:数据集应来自不同的领域,以涵盖不同的推理任务。我们收集了两类数据集:
现有数据集的整理
我们最大的数据来源是 NuminaMATH,它包含了来自在线网站的 30,660 个数学问题。我们还收录了历史上的 AIME 问题(1983-2021)。为了增强多样性,我们加入了 OlympicArena,其中包含来自各种奥林匹克竞赛的 4,250 个问题,涵盖天文学、生物学、化学、计算机科学、地理学、数学和物理学。OmniMath 贡献了 4,238 个竞赛级别的数学问题。此外,我们还纳入了来自 AGIEval 的 2,385 个问题,这些问题来自诸如 SAT 和 LSAT 等标准化考试,内容涉及英语、法律和逻辑。
定量推理中的新数据集
为了补充这些现有的数据集,我们创建了两个原创数据集。s1-prob 包含来自斯坦福大学统计系博士资格考试概率部分的 182 个问题,并附有涵盖难题证明的手写解答。概率资格考试每年举行一次,需要专业水平的数学问题解决能力。s1-teasers 包含 23 个具有挑战性的脑筋急转弯,这些脑筋急转弯通常用于量化交易职位的面试问题。每个样本都包含一个来自 PuzzledQuant 的问题和解答。我们只选取难度最高(“Hard”)的例子。
对于每个问题,我们使用 Google Gemini Flash Thinking API 生成推理轨迹和解决方案,提取其推理轨迹和响应。这产生了 59K 个问题、生成的推理轨迹和生成的解决方案的三元组。我们使用 8-grams 对所有样本进行去污染处理,以防止与我们的评估问题重复,并对数据进行去重。
1K 样本的最终选择
我们可以直接使用我们拥有的 59K 个问题进行训练,然而,我们的目标是以最少的资源找到最简单的方法。因此,我们进行了三个阶段的筛选,最终得到了一个包含 1000 个样本的最小集合,这个过程基于我们三个指导数据原则:质量、难度和多样性。
质量
我们首先移除所有在处理过程中遇到 API 错误的提问,将数据集缩减至 54,116 个样本。 接下来,我们通过检查样本是否包含任何具有格式问题的字符串模式来过滤掉低质量的示例,例如 ASCII 艺术图、不存在的图像引用或不一致的问题编号,从而将数据集缩减至 51,581 个示例。 从这个样本池中,我们从我们认为高质量且不需要进一步过滤的数据集中选取 384 个样本,用于我们最终的 1,000 个样本。
难度
对于难度,我们采用两个指标:模型性能和推理轨迹长度。我们针对每个问题评估两个模型:Qwen2.5-7B-Instruct 和 Qwen2.5-32B-Instruct。通过 Claude 3.5 Sonnet 将每次尝试与参考答案进行比较来评估正确性。我们使用 Qwen2.5 tokenizer 测量每个推理轨迹的 Token 长度,以此来衡量问题难度。这里的假设是,更困难的问题需要更多的思考 Token。根据评分结果,我们移除 Qwen2.5-7B-Instruct 或 Qwen2.5-32B-Instruct 能够正确解答的问题,因为这些问题可能过于简单。通过使用两个模型,我们降低了因其中一个模型在简单问题上出现罕见错误而导致简单样本被遗漏的可能性。这使得我们的总样本量减少到 24,496 个,为下一轮基于多样性的子抽样奠定了基础。虽然使用这两个模型进行过滤可能针对我们的设置进行了优化(因为我们也将使用 Qwen2.5-32B-Instruct 作为我们进行微调的模型),但基于模型的过滤方法可以推广到其他设置。
多样性
为了量化多样性,我们使用 Claude 3.5 Sonnet,基于美国数学学会的数学学科分类 (MSC) 系统(例如,几何、动力系统、实分析等),将每个问题分类到特定领域。[^1] 该分类法侧重于数学主题,但也包括其他科学,如生物学、物理学和经济学。为了从 24,496 个问题的池中选择最终示例,我们首先均匀随机地选择一个领域。然后,我们根据一个偏好较长推理轨迹的分布,难度部分有动机)从此领域中抽取一个问题。我们重复此过程,直到总共有 1,000 个样本。
这个三阶段过程产生了一个跨越 50 个不同领域的数据集。
测试时缩放

方法
我们将测试时缩放方法分为 1) 顺序,其中后续计算依赖于先前的计算(例如,一个长的推理轨迹),以及 2) 并行,其中计算独立运行(例如,多数投票)。我们专注于顺序缩放,因为我们直观地认为它应该具有更好的扩展性,因为后续计算可以建立在中间结果之上,从而实现更深入的推理和迭代改进。我们提出了新的顺序缩放方法以及对它们进行基准测试的方法。
预算强制
我们提出一种简单的解码时干预方法,通过在测试时强制执行最大和/或最小的思考 Token 数量。具体来说,我们通过简单地附加思考结束 Token 分隔符和“Final Answer:”来强制执行最大 Token 计数,以便提前退出思考阶段并使模型提供其当前最佳答案。为了强制执行最小值,我们抑制思考结束 Token 分隔符的生成,并可选择将字符串“Wait”附加到模型当前的推理轨迹中,以鼓励模型反思其当前的生成。包含一个示例,说明这种简单的方法如何引导模型得出更好的答案。
基线
我们使用以下方法对预算强制进行基准测试:(I) 条件长度控制方法,这种方法依赖于在提示词中告知模型其应生成内容的长度。我们按照粒度将其分组为:(a) Token 条件控制:我们在提示词中指定思考 Token 的上限;(b) 步骤条件控制:我们指定思考步骤的上限,其中每个步骤大约为 100 个 Token;(c) 类条件控制:我们编写两个通用提示词,告知模型进行较短或较长时间的思考。(II) 拒绝采样,它进行采样直到生成的文本符合预定的计算预算。这个预言机捕获了以文本长度为条件的响应的后验分布。
指标
$$ \begin{aligned} \text{control} = \frac{1}{|\mathcal{A}|} \sum_{a \in \mathcal{A}} \mathbb{I}(a_{\text{min}} \leq a \leq a_{\text{max}}) \end{aligned} $$$$ \begin{aligned} \text{scaling} = \frac{1}{\binom{|\mathcal{A}|}{2}} \sum_{\substack{a, b \in \mathcal{A} \\ b > a}} \frac{f(b) - f(a)}{b - a} \end{aligned} $$$$\begin{aligned} \text{缩放} \end{aligned}$$$$ \begin{aligned} \text{性能} &= \max_{a \in \mathcal{A}} f(a) \end{aligned} $$性能是指该方法在基准测试中所能达到的最大性能。如果一个方法的缩放是单调递增的,那么在极限情况下,它在任何基准测试中都能达到 100% 的性能。然而,我们研究的方法最终会趋于平缓,或者由于控制或上下文窗口的限制,进一步的缩放会失效。
训练
我们使用 s1K 对 Qwen2.5-32B-Instruct 模型进行监督微调,以获得我们的模型 s1-32B。在 16 个 NVIDIA H100 GPU 上,使用 PyTorch FSDP 进行微调耗时 26 分钟。
评估
我们选择了该领域广泛使用的三个具有代表性的推理基准:AIME24 包含 30 个问题,这些问题来自 2024 年 1 月 31 日星期三至 2 月 1 日星期四举行的美国邀请数学考试 (AIME)。AIME 测试算术、代数、计数、几何、数论、概率和其他中学数学主题的数学问题解决能力。在测试中获得高分的高中生将被邀请参加美国数学奥林匹克竞赛 (USAMO)。所有 AIME 的答案都是从 $000$ 到 $999$(包括 $000$ 和 $999$)的整数。一些 AIME 问题依赖于我们使用矢量图形语言 Asymptote 提供给模型的图形,因为它不能接受图像输入。MATH500 是一个包含各种难度竞赛数学问题的基准。我们评估了 OpenAI 在先前工作中选择的相同的 500 个样本。GPQA Diamond 包含来自生物学、化学和物理学的 198 个博士级科学问题。在相应领域拥有博士学位的专家在 GPQA Diamond 上仅取得了 69.7% 的成绩。当我们在本文的评估中使用“GPQA”时,我们始终指的是 Diamond 子集。我们基于“lm-evaluation-harness”框架构建。