从 PPO 到 GRPO
近端策略优化(PPO)是一种 actor-critic 强化学习算法,广泛应用于大语言模型(LLM)的强化学习微调阶段。具体而言,它通过最大化以下替代目标来优化大语言模型:
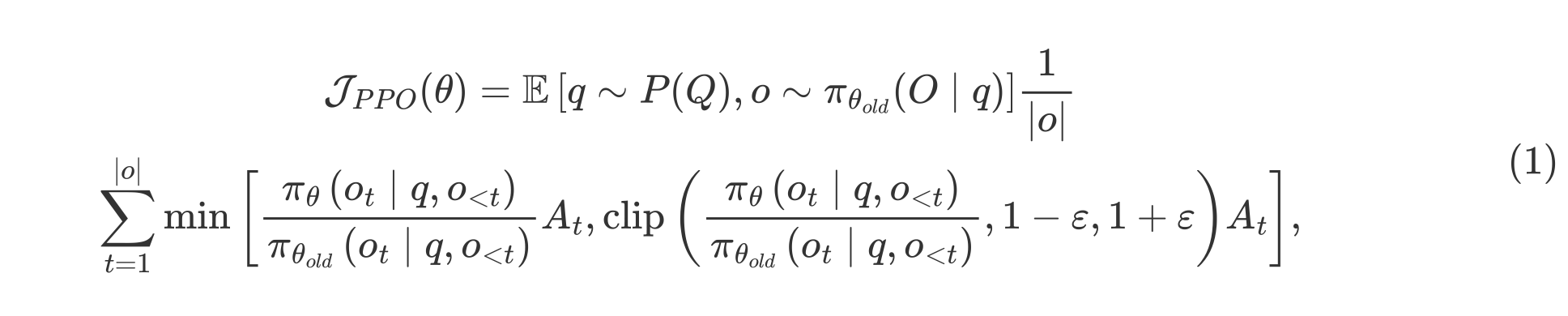
其中,$\pi_{\theta}$ 和 $\pi_{\theta_{old}}$ 分别是当前策略模型和旧策略模型,$q$ 和 $o$ 分别是从问题数据集和旧策略 $\pi_{\theta_{old}}$ 中采样的问题和输出。$\varepsilon$ 是 PPO 中引入的用于稳定训练的裁剪相关超参数。$A_t$ 是优势值,它通过应用广义优势估计(GAE)计算得出,基于奖励 $\{r_{\ge t}\}$ 和一个学习到的价值函数 $V_{\psi}$。因此,在 PPO 中,需要与策略模型一同训练一个价值函数。为了减轻对奖励模型的过度优化,标准做法是在每个 token 的奖励中添加来自参考模型的每个 token 的 KL 散度惩罚,即:
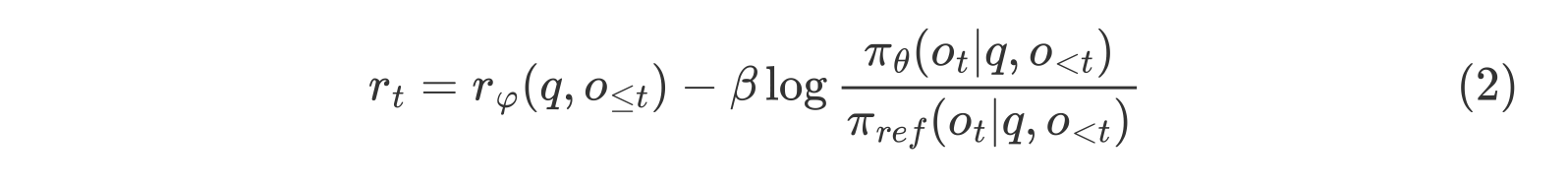
其中 $r_\varphi$ 是奖励模型,$ \pi_{ref} $ 是参考模型,通常是初始的 SFT 模型,而 $ \beta $ 是 KL 惩罚的系数。
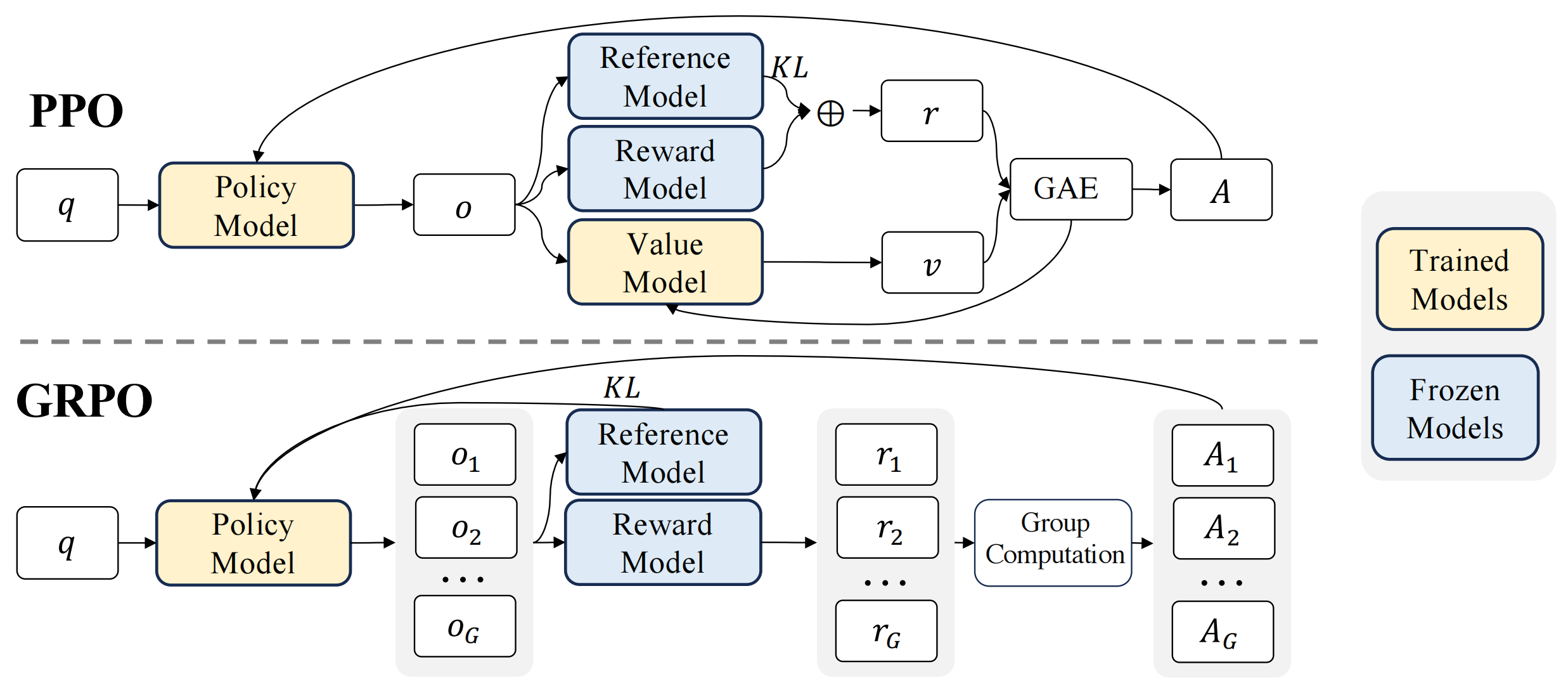
由于 PPO 中使用的价值函数通常是与策略模型大小相当的另一个模型,因此会带来大量的内存和计算负担。此外,在强化学习(RL)训练期间,价值函数被视为计算优势以减少方差的基线。
然而,在大语言模型(LLM)的背景下,通常只有最后一个 Token 会被奖励模型赋予奖励分数,这可能会使在每个 Token 上都准确的价值函数的训练变得复杂。为了解决这个问题,我们提出了组相对策略优化(GRPO),它无需像 PPO 那样进行额外的价值函数近似,而是使用针对同一问题生成的多个采样输出的平均奖励作为基线。更具体地说,对于每个问题 $q$,GRPO 从旧策略 $ \pi_{\theta_{old}} $ 中采样一组输出 $ \{o_1, o_2, \cdots, o_G\} $,然后通过最大化以下目标来优化策略模型:
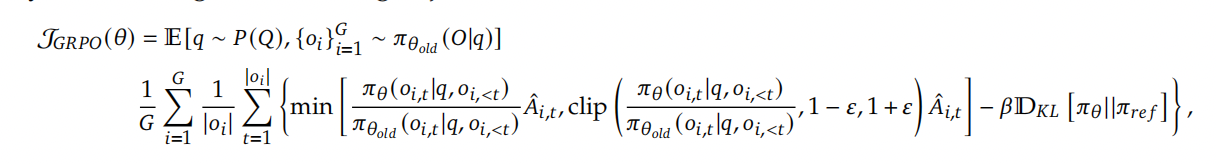
其中 $\varepsilon$ 和 $\beta$ 是超参数,$\hat{A}_{i,t}$ 是基于每个组内输出的相对奖励计算的优势。
GRPO 利用组相对方式计算优势,与奖励模型的比较性质非常吻合,因为奖励模型通常在同一问题的输出比较数据集上进行训练。另请注意,GRPO 不是在奖励中添加 KL 惩罚,而是通过直接将训练策略和参考策略之间的 KL 散度添加到损失中进行正则化,从而避免了 $\hat{A}_{i,t}$ 的计算复杂化。与PPO中使用的 KL 惩罚项不同,我们使用以下无偏估计器估计 KL 散度:
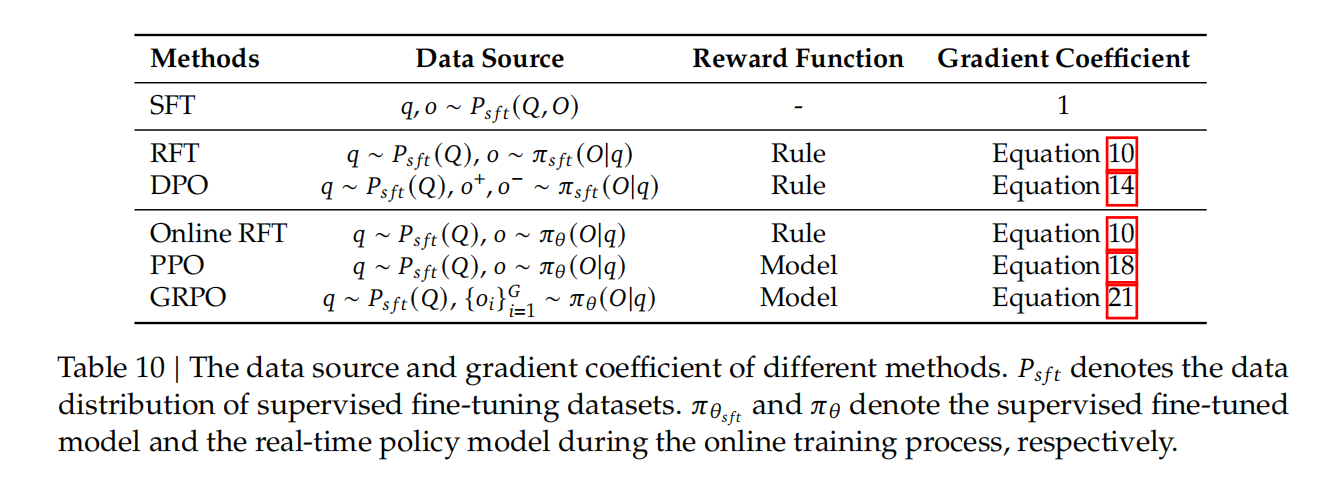
$\mathbb{D}_{KL}\left[\pi_{\theta} || \pi_{ref}\right] = \frac{\pi_{ref}(o_{i,t}|q,o_{i, 这保证是正数。 形式上,对于每个问题 $q$,从旧策略模型 $\pi_{\theta_{old}}$ 中采样一组输出 $\{o_1, o_2, \cdots, o_G\}$。然后使用奖励模型对这些输出进行评分,得到 $G$ 个相应的奖励 $\mathbf{r}=\{r_1, r_2, \cdots, r_G\}$。随后,通过减去组平均值并除以组标准差来对这些奖励进行归一化。结果监督在每个输出 $o_i$ 的末尾提供归一化奖励,并将输出中所有 Token 的优势 $\hat{A}_{i, t}$ 设置为该归一化奖励,即 $\hat{A}_{i, t} = \widetilde{r}_i = \frac{r_i- {\rm mean}(\mathbf{r})}{{\rm std}(\mathbf{r})}$。然后,通过最大化GRPO中定义的目标来优化策略。 结果监督仅在每个输出的末尾提供奖励,这可能不足以有效且高效地监督复杂数学任务中的策略。 遵循,我们还探索了过程监督,它在每个推理步骤的末尾提供奖励。 形式上,给定问题 $q$ 和采样的 $G$ 个输出 $\{o_1, o_2, \cdots, o_G\}$,使用过程奖励模型来对输出的每个步骤进行评分,从而产生相应的奖励:$\mathbf{R} = \{ \{r_1^{index(1)},\cdots,r_1^{index(K_1)}\}, \cdots, \{r_G^{index(1)},\cdots,r_G^{index(K_G)}\} \}$,其中 $index(j)$ 是第 $j$ 步的结束 token 索引,$K_i$ 是第 $i$ 个输出中的总步数。我们还使用平均值和标准差对这些奖励进行归一化,即 $\widetilde{r}_i^{index(j)} = \frac{r_i^{index(j)} - {\rm mean(\mathbf{R})}}{{\rm std(\mathbf{R})}}$。随后,过程监督计算每个 token 的优势,作为后续步骤的归一化奖励的总和,即 $\hat{A}_{i, t} = \sum_{index(j) \ge t} \widetilde{r}_i^{index(j)}$,然后通过最大化GRPO中定义的目标来优化策略。 随着强化学习训练过程的推进,旧的奖励模型可能不足以有效地监督当前的策略模型。因此,我们也探索了使用 GRPO 的迭代强化学习方法。如算 所示,在迭代 GRPO 中,我们基于策略模型的采样结果,为奖励模型生成新的训练数据集,并利用包含 10% 历史数据的回放机制,持续训练旧的奖励模型。随后,我们将参考模型设定为策略模型,并使用更新后的奖励模型持续训练策略模型。 在本节中,我们提供一个统一的范式来分析不同的训练方法,例如 SFT、RFT、DPO、PPO、GRPO,并进一步进行实验以探索统一范式的要素。一般来说,关于训练方法参数 $\theta$ 的梯度可以写成: 这里存在三个关键组成部分: 1)数据来源 $\mathcal{D}$,它决定了训练数据; 2)奖励函数 $\pi_{{rf}}$,它是训练奖励信号的来源; 3)算法 $\mathcal{A}$:它处理训练数据和奖励信号,得到梯度系数 $GC$,该系数决定了数据的惩罚或强化的幅度。
基于 GRPO 的结果监督强化学习
使用 GRPO 的过程监督强化学习
使用 GRPO 的迭代强化学习
迈向统一范式